












推しアイデア
AIと数学的解析による地域課題の分析とUGC的社会課題解決 あなたにピッタリのアイコンGET! 世界に一つ、あなただけの称号を入手できる!
―
AIと数学的解析による地域課題の分析とUGC的社会課題解決 あなたにピッタリのアイコンGET! 世界に一つ、あなただけの称号を入手できる!
未来を創るために自分達の地域を発展させることが重要
・AIによるモデレート ・埋め込みベクトルと物理的座標から関係性予測 ・ランキングのソート
こんにちは。今回は、私たちが開発したアプリ「EmpaCity」について紹介したいと思います。
「EmpaCity」は、暮らしている街や都市に対する ちょっとした不満や疑問を気軽にシェアできる場所 です。普段「ここ不便だな」とか「なんでこうなってるんだろう?」と思っても、わざわざ役所に言いに行くほどじゃないことってありますよね。でも、そういう声こそ実は大事で、集まれば街を良くするヒントになるはず。
作った背景や裏話も含めて、できるだけリアルに書くので、街づくりや開発に興味がある人に少しでも参考になれば嬉しいです。
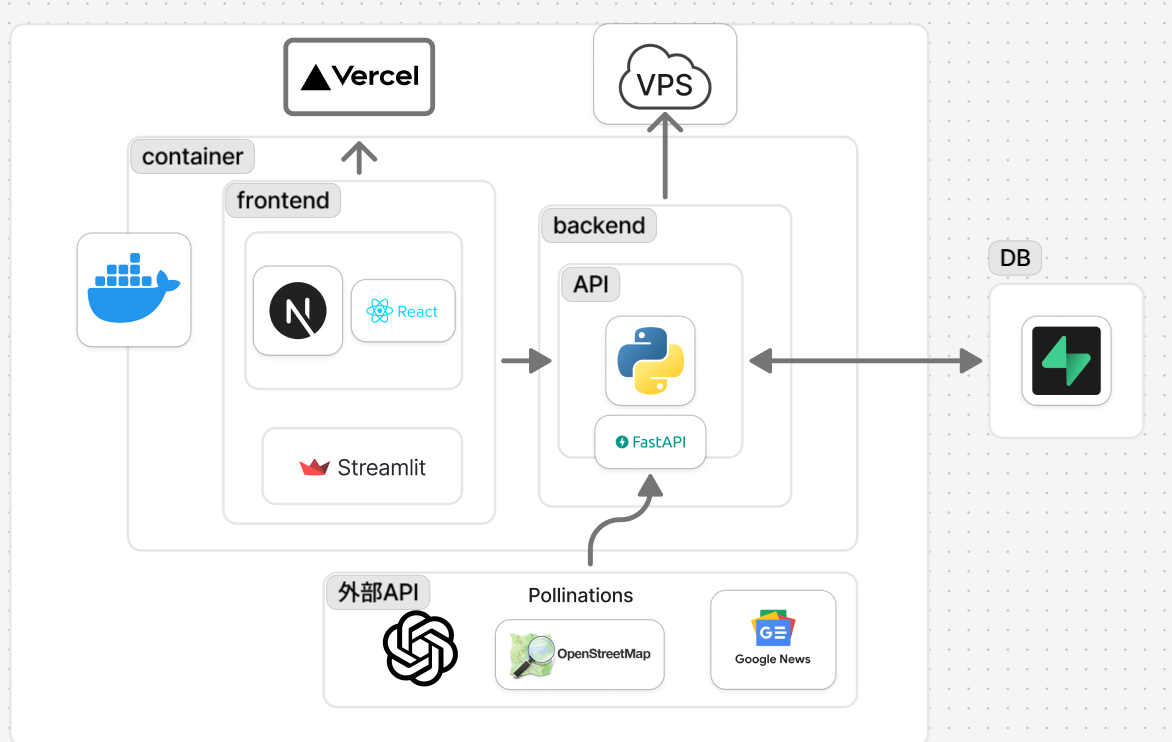
 (サインアップをするとSupabaseで認証メールが届きます)
(サインアップをするとSupabaseで認証メールが届きます)
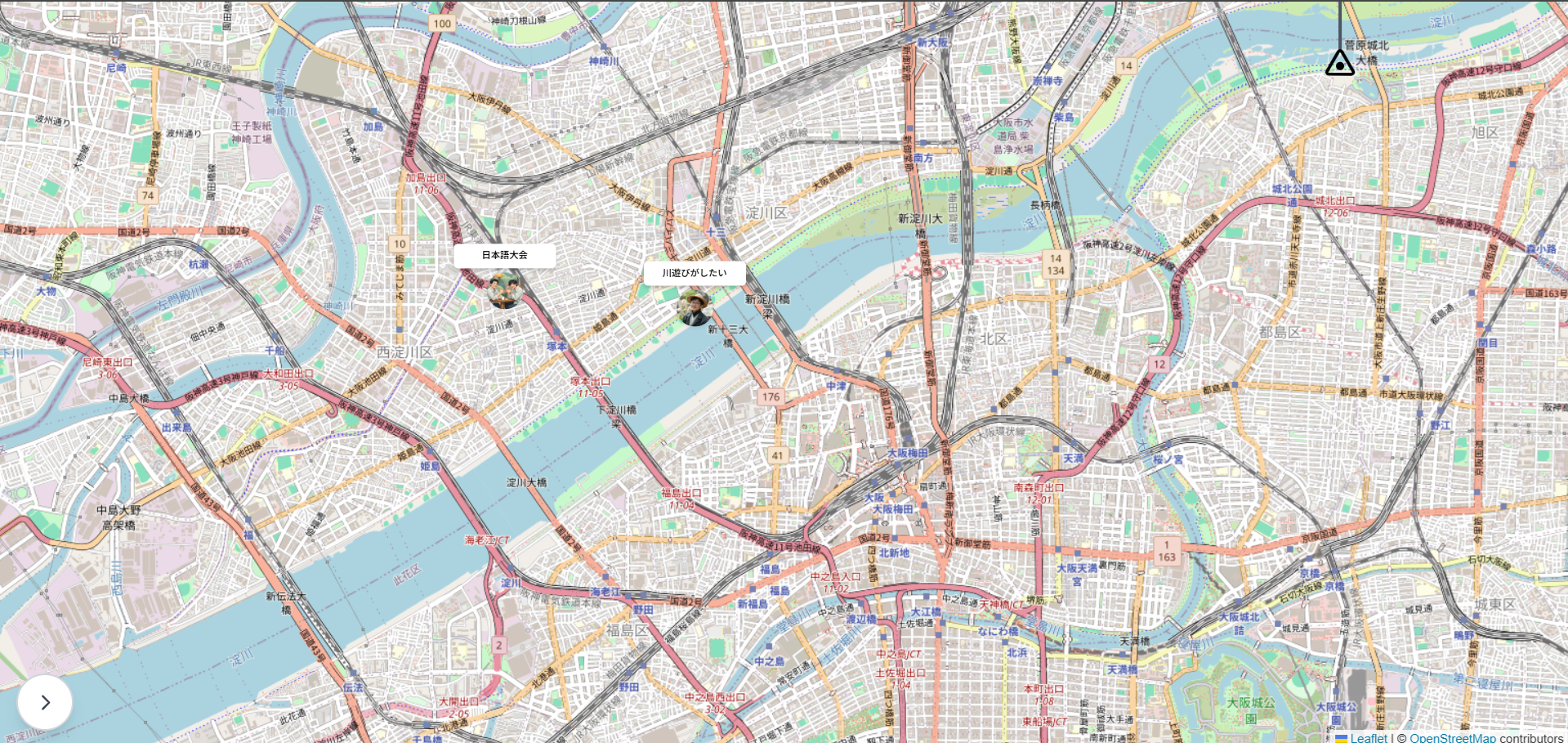 地図を画面全体に見せることで、ユーザーがどういうサービスなのかを一番最初に感覚的に理解できるようにしました
地図を画面全体に見せることで、ユーザーがどういうサービスなのかを一番最初に感覚的に理解できるようにしました
 丸みを帯びたデザインにしてかわいくも地図を邪魔しないようにしました
丸みを帯びたデザインにしてかわいくも地図を邪魔しないようにしました
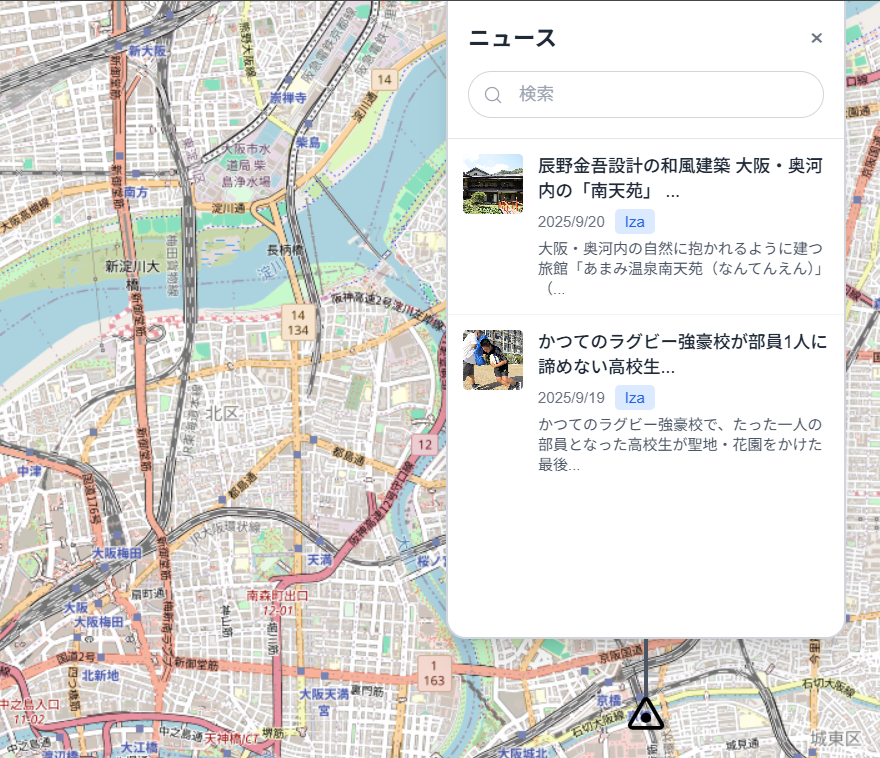 右上の紐を押すと、ニュースの画面が上から出てきます
右上の紐を押すと、ニュースの画面が上から出てきます
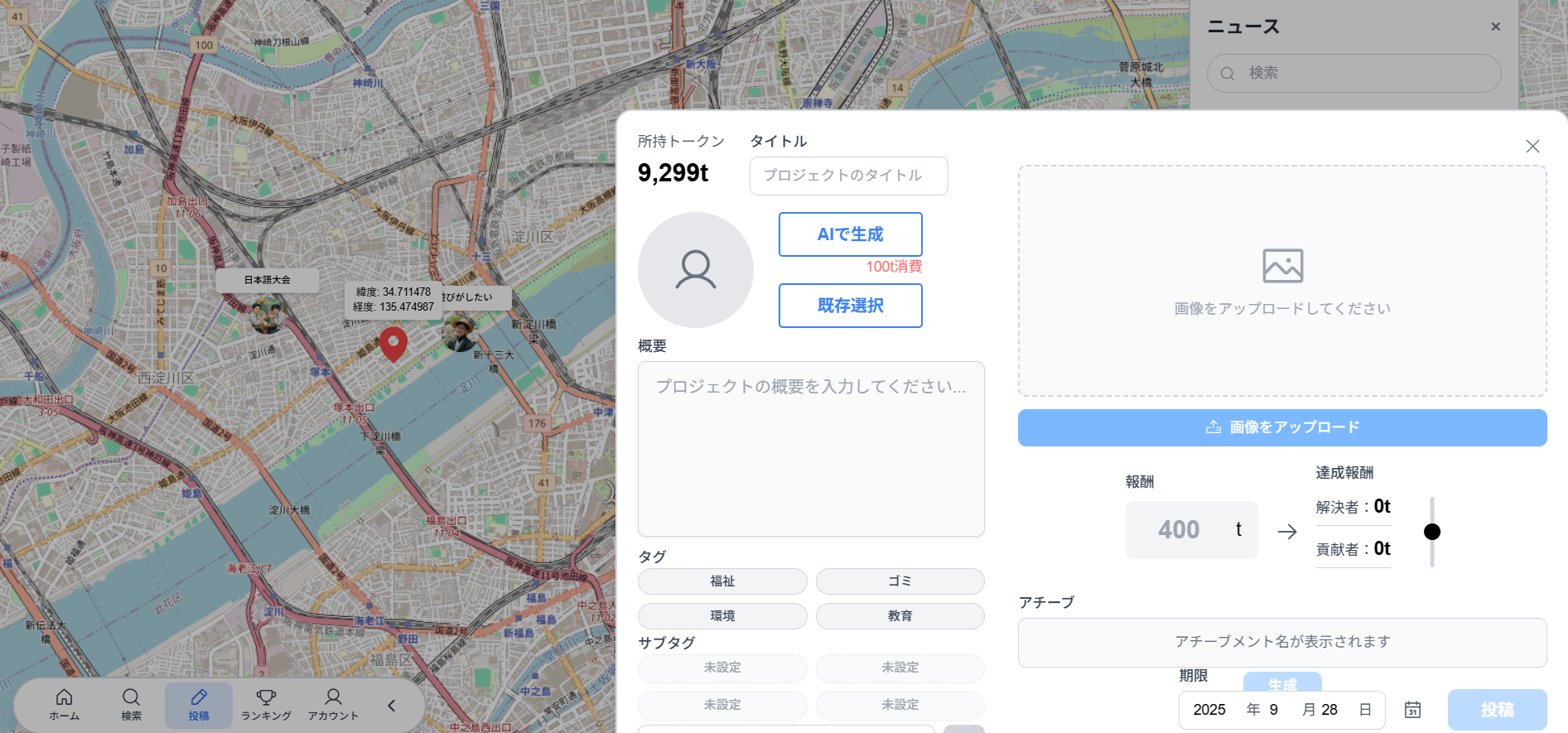 ユーザーが直感的に投稿を作製できるようにUXを工夫しました
ユーザーが直感的に投稿を作製できるようにUXを工夫しました
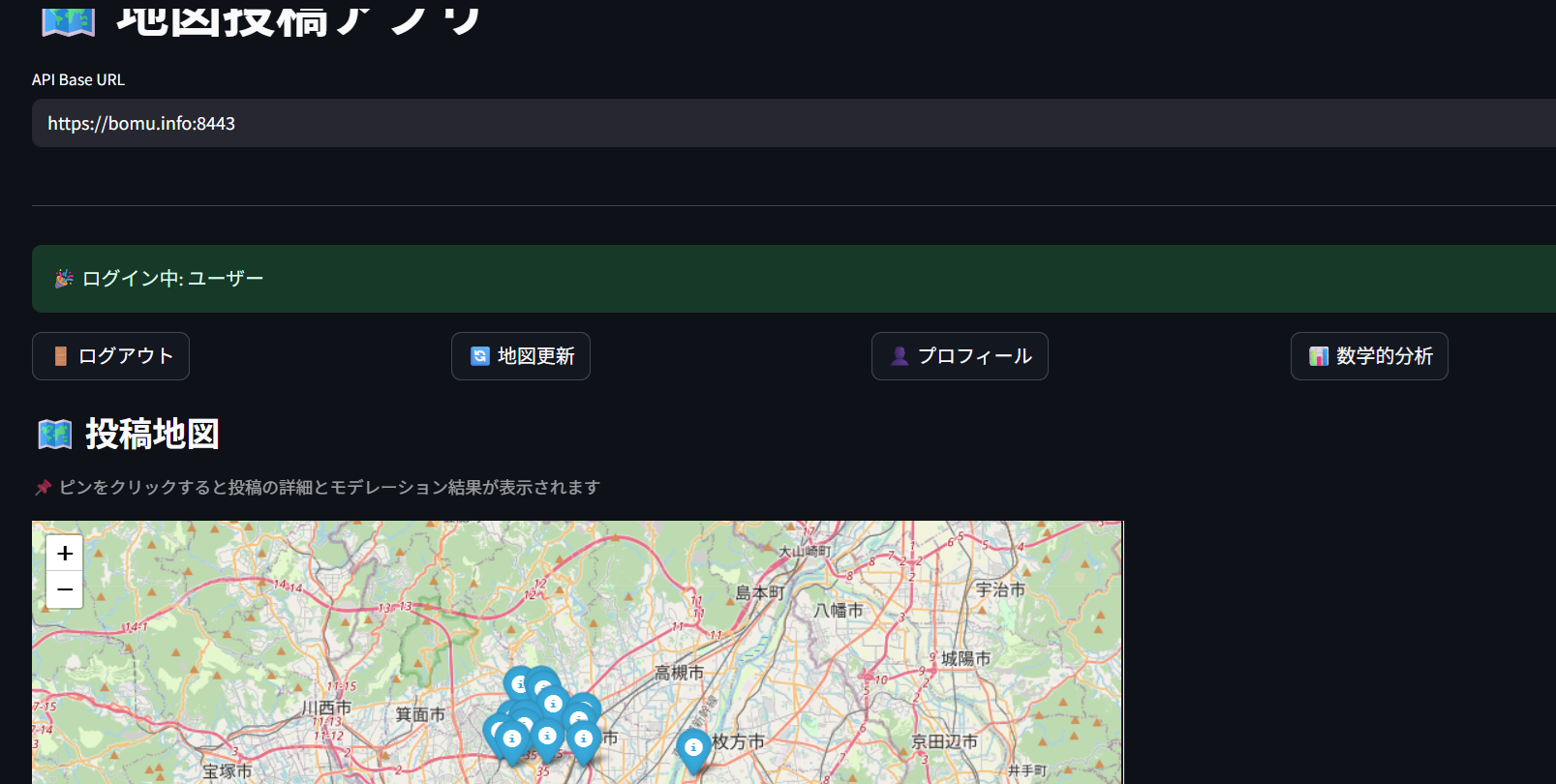 ピンをクリックすると、該当タグの投稿詳細と、その投稿の安全性をAIモデレーターが診断します。
ピンをクリックすると、該当タグの投稿詳細と、その投稿の安全性をAIモデレーターが診断します。

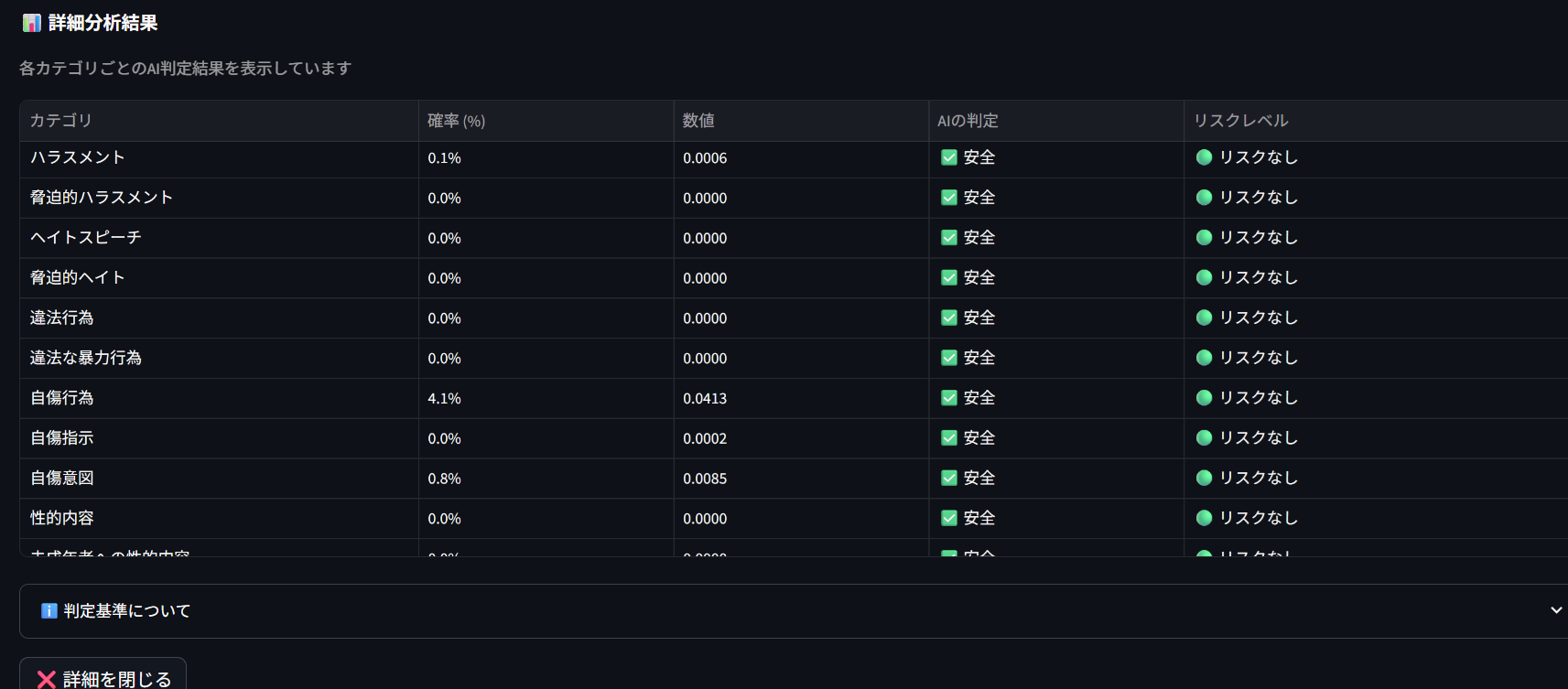 マップに表示されている範囲の投稿について、投稿内容を埋め込みベクトル化して内容を定量化したうえで、物理的な座標と関連付けて数学的に分析を行います。
マップに表示されている範囲の投稿について、投稿内容を埋め込みベクトル化して内容を定量化したうえで、物理的な座標と関連付けて数学的に分析を行います。
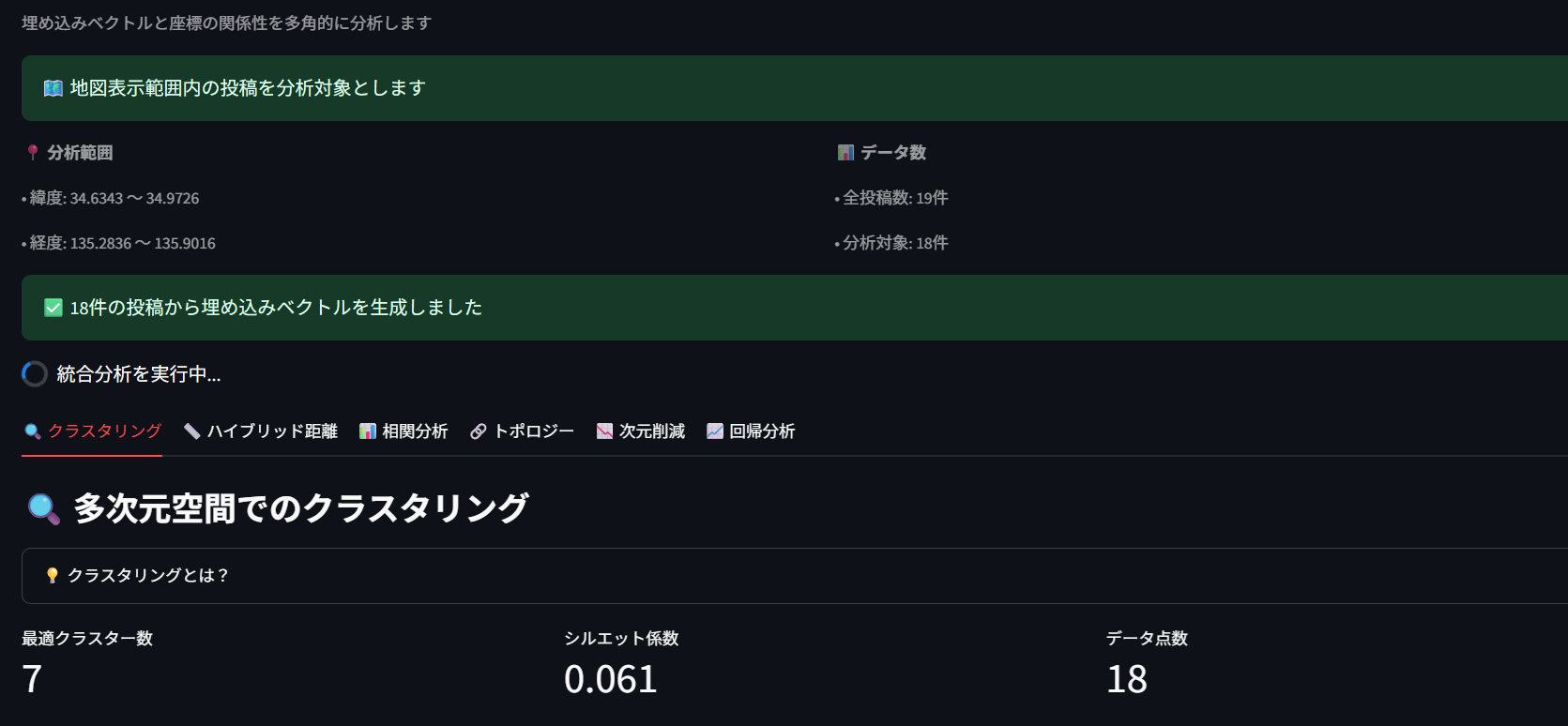


似たような投稿を自動的にグループ分けする技術です。
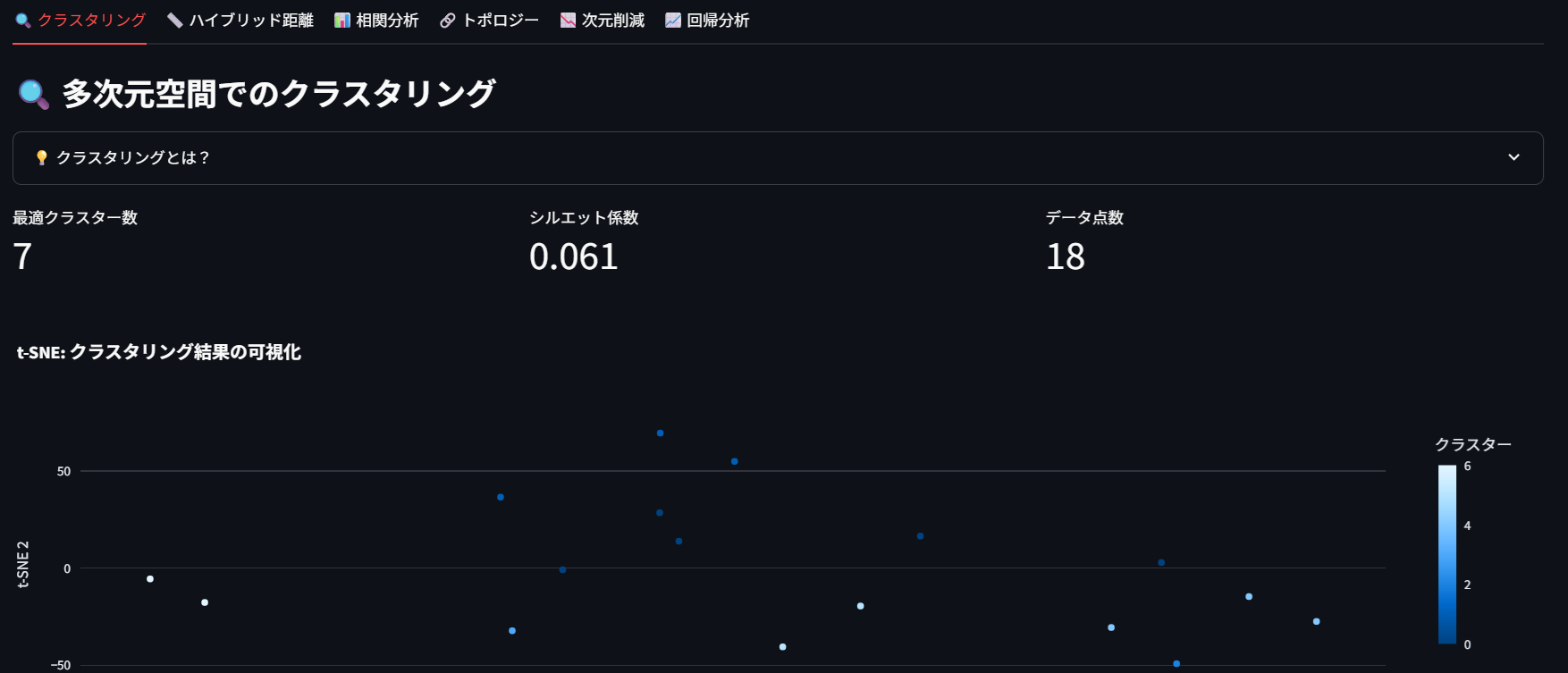
何ができるの?
投稿の内容が似ている記事同士を自動でグループ化 同じような話題や関心事を持つ投稿を発見 データ全体の傾向や特徴を理解 見方のポイント:
最適クラスター数: データが自然に分かれるグループの数 シルエット係数: グループ分けの上手さ(0.7以上で優秀、0.3以下で微妙) グラフの見方: 近くにある点は似た内容の投稿、色が同じ点は同じグループ 実用例: 「観光スポット」「グルメ」「イベント」など、投稿内容で自動分類できます!
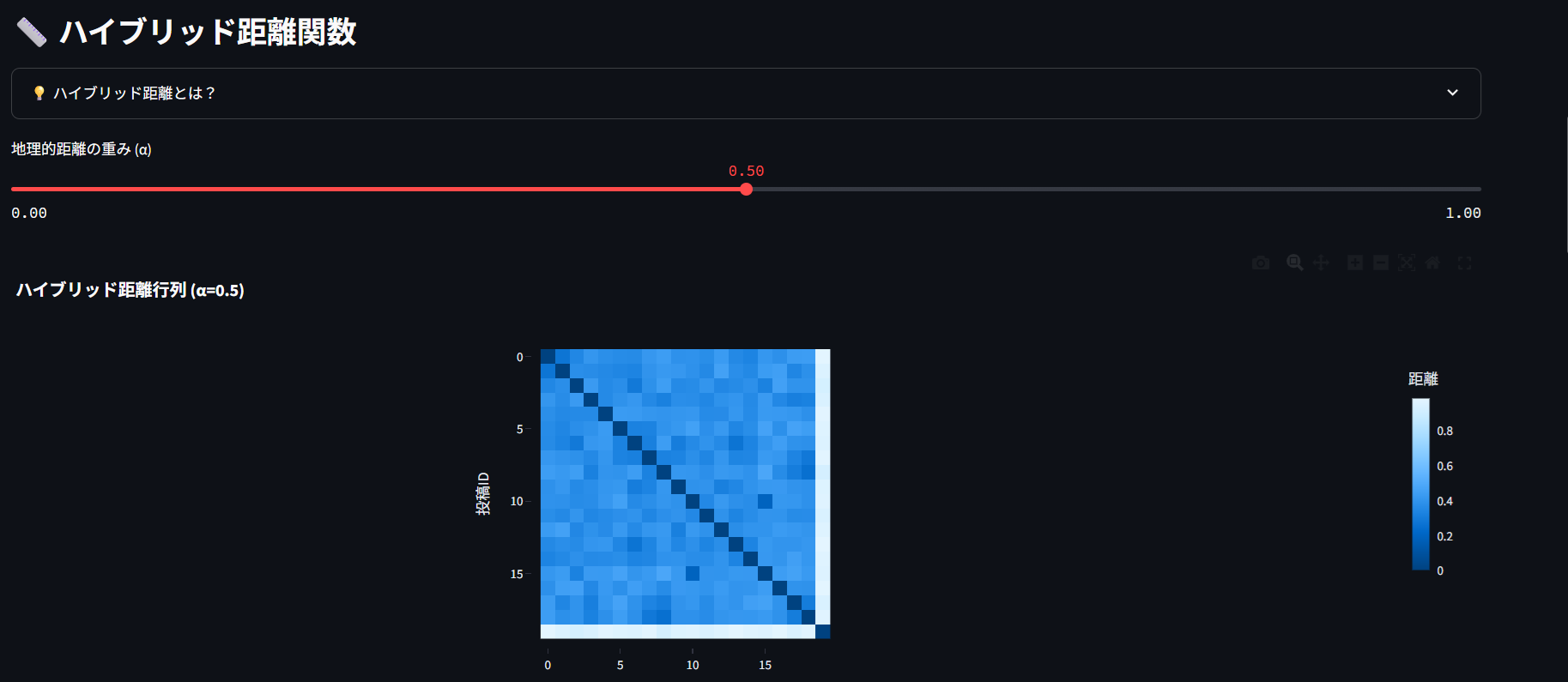
「場所の近さ」と「内容の似やすさ」を組み合わせた新しい距離の測り方です。
何ができるの?
地理的に近くて、内容も似ている投稿を発見 場所は遠いけど話題が似ている投稿を発見 地域性と話題性のバランスを調整して分析 αスライダーの使い方:
α = 0.0: 内容の似やすさだけを重視(場所は無視) α = 0.5: 場所と内容を同じくらい重視(バランス型) α = 1.0: 場所の近さだけを重視(内容は無視) グラフの見方:
ヒートマップ: 濃い色 = 距離が遠い(似てない)、薄い色 = 距離が近い(似ている) ヒストグラム: 投稿同士の距離の分布 実用例: 「渋谷のカフェ」と「新宿のカフェ」は地理的に近く内容も似ている → 距離が小さい
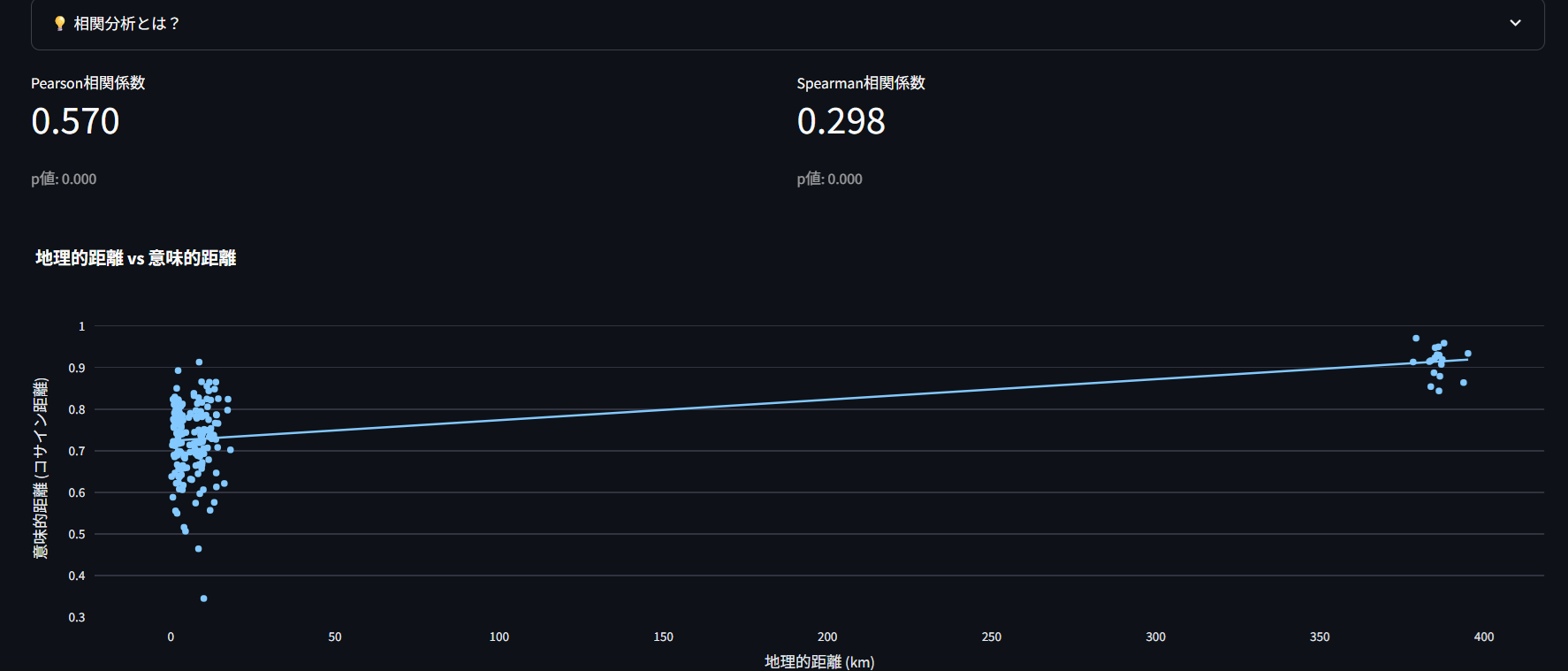
「場所の近さ」と「内容の似やすさ」にどの程度関係があるかを調べる分析です。
何が分かるの?
近い場所の投稿は、内容も似ているのか? 地域によって投稿の傾向は変わるのか? 場所と内容の関係の強さはどの程度? 相関係数の見方:
+1.0 に近い: 場所が近いほど内容も似ている(強い正の相関) 0.0 に近い: 場所と内容に関係はない(相関なし) -1.0 に近い: 場所が近いほど内容は似ていない(強い負の相関) 判定基準:
0.7以上: 強い相関 0.3〜0.7: 中程度の相関 0.3未満: 弱い相関 Pearson vs Spearman:
Pearson: 直線的な関係を測定 Spearman: 順序関係(ランク)を測定 実用例: 観光地では観光系の投稿が多い → 地理と内容に正の相関
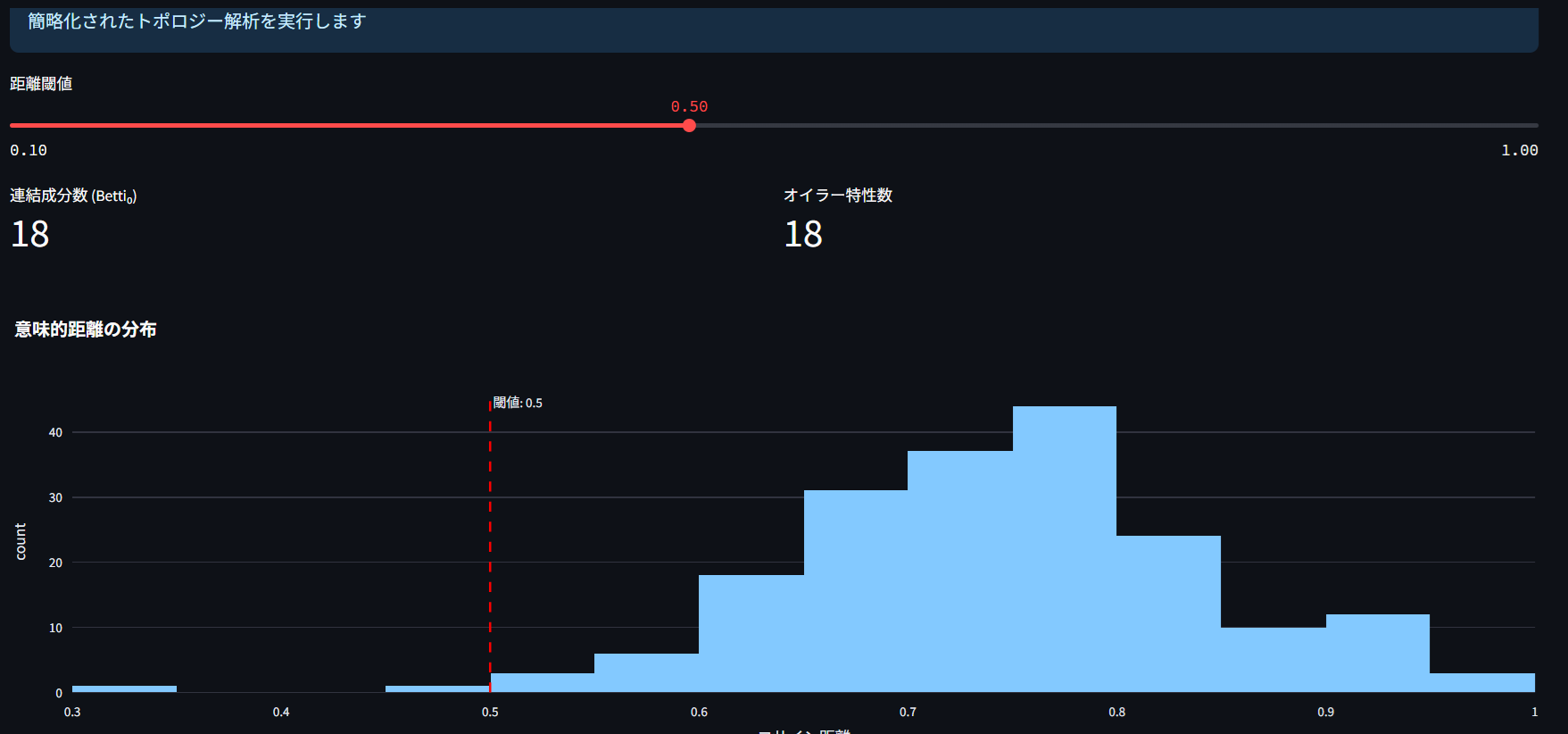
データの「形」や「つながり」を調べる最先端の分析技術です。
何ができるの?
データの中に隠れている「グループ」や「つながり」を発見 似た投稿同士がどのように「つながっている」かを理解 データ全体の「構造」や「形」を可視化 重要な指標:
連結成分数(Betti₀): 独立したグループの数 オイラー特性数: データの形の特徴を表す数値 距離閾値: どの程度似ていれば「つながっている」と判定するか 距離閾値の調整:
小さい値: 厳しい基準(よく似た投稿だけがつながる) 大きい値: 緩い基準(少し似ていればつながる) 実用例:
連結成分数が多い → 多様な話題の投稿がある 連結成分数が少ない → 似たような話題の投稿が多い
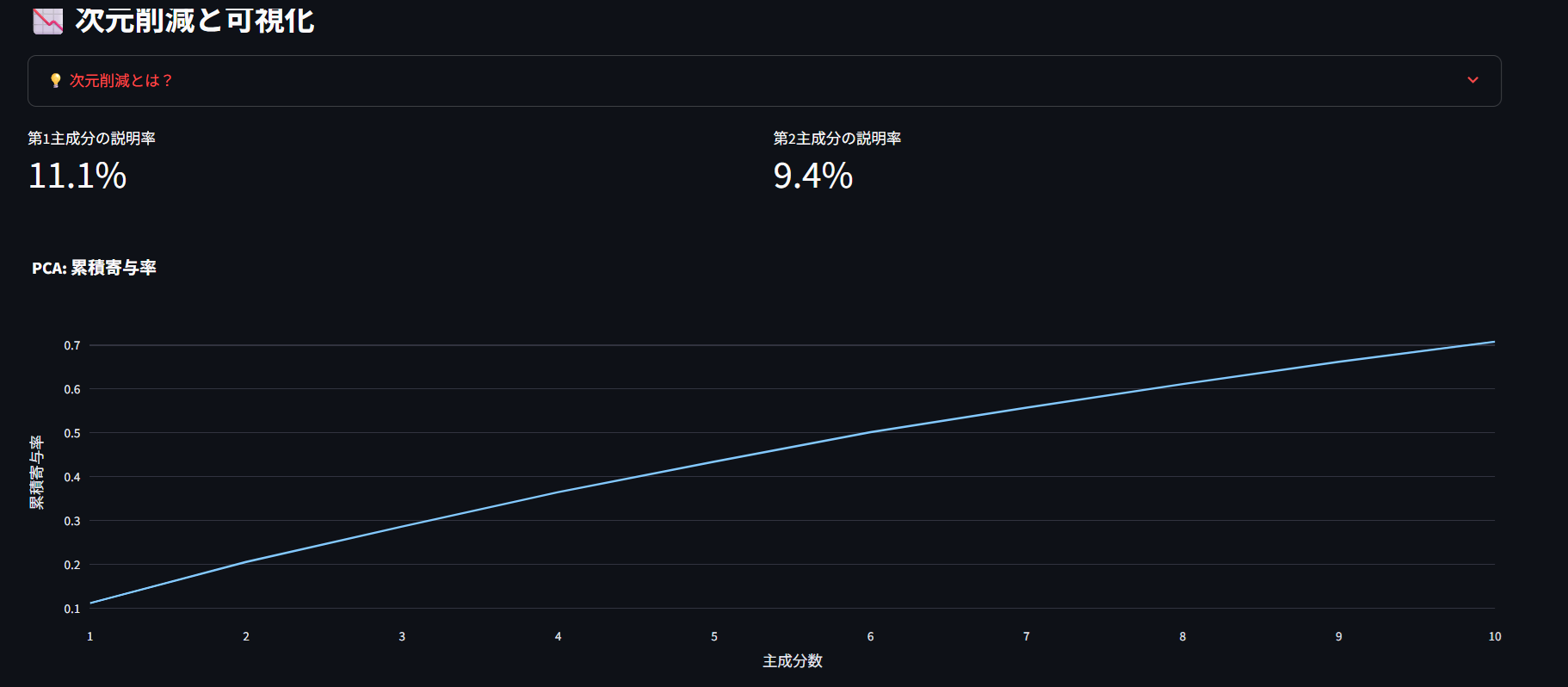
複雑な高次元データを人間が理解しやすい2次元や3次元に変換する技術です。
なぜ必要なの?
投稿の「意味」は数千次元のベクトルで表現される 人間には数千次元は理解不可能 2次元に圧縮して「投稿の関係性」を可視化 分析手法の特徴:
🔍 PCA(主成分分析)
データの中で最も重要な方向を見つける 線形変換(真っ直ぐな変換) 説明率:元データの何%の情報を保持しているか 🎯 t-SNE
似た投稿を近くに、違う投稿を遠くに配置 非線形変換(曲がった変換も可能) クラスターの構造が見えやすい 🗺️ UMAP
t-SNEより高速で、大域的構造も保持 距離関係をより正確に保つ 最新の次元削減技術 グラフの見方:
近くにある点 = 似た内容の投稿 遠くにある点 = 異なる内容の投稿 クラスター = 同じような話題のグループ
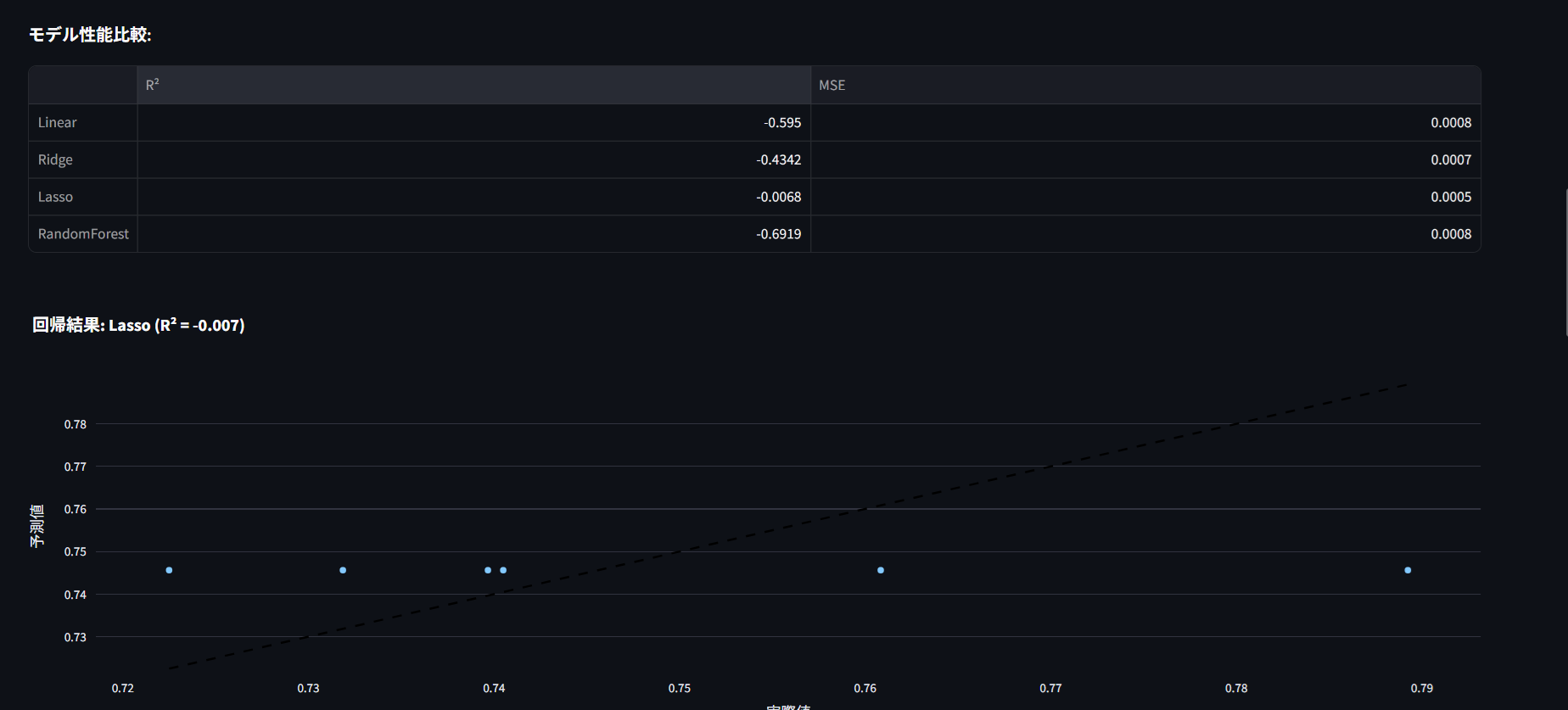
ある要因(場所、投稿の特徴など)から別の要因(意味的多様性)を予測する分析です。
何を予測しているの?
目的変数: 意味的多様性(その投稿が他の投稿とどれくらい異なるか) 説明変数: 緯度・経度・投稿内容の統計的特徴 分析モデルの特徴:
📏 Linear(線形回帰)
最もシンプルな予測モデル 直線的な関係を仮定 理解しやすい 🎯 Ridge回帰
線形回帰の改良版 過学習を防ぐ機能付き 安定した予測 ✂️ Lasso回帰
重要でない要因を自動で除外 特徴選択機能付き シンプルなモデル 🌳 RandomForest
複雑な非線形関係も捉える 高い予測精度 最も実用的 評価指標:
R²(決定係数): 予測の精度(1.0に近いほど優秀) MSE(平均二乗誤差): 予測の誤差(小さいほど優秀) 実用例: 「東京の観光地の投稿は多様性が高い」などの傾向を数値で予測
Cloud Flare R2(登録の手続きが何かと煩雑だった) ⇩ Google Drive(WorkSpaceアカウントが必要) ⇩ Supabase Storage(一番手続きが容易だった)
Freepik(無料だが、非同期での生成となるため扱いが難しい) ⇩ Pollinations(無料で使うことができ、APIキーを取得せずにURLにアクセスするだけで生成が可能)
我々のチームではDBを構築するえで、FigmaでDBのER図を書いたうえで、それをChatGPTに画像として読み込ませSQL文を構築し、それをSupabaseに読ませることでDBを簡単に構築することが出来ました。 後ほど触れますAIの強み弱みである、骨子が出来た場合の機能開発が光った場面でした さらに、SupabaseからSQLとしてDBの構造をローカルに落とし込み、それをAIに読ませることでDBに対するAIの解像度が上がり、正確に構築することが出来ました
AIは開発をするうえで人間はAIの目となり、最終意思決定者となるべきだと感じました。 VPSにデプロイしたバックエンドのプログラムと通信が出来ないことがありましたが、AIはシステム上のことして見えておらず原因を特定できていませんでしたが、私はXserverのVPSのダッシュボード上でも解放しないといけないことに気づき、解決することができました。 AIは見えるものをもとにしか考えられず、バックストーリーや視覚でしかとらえられないこと、よういに言語化できないものをテキストに落とし込むことこそが人間の大事な役割であると感じました。
AIは骨子のアイデアやコアの機能を作る部分ではあまり強くない印象が強い その一方で、コアの骨子の機能が完成したうえで機能を拡充するうえでは開発者が作った前提となるコードがあるので、非常に正確に開発をすることが出来た
1日目にチーム内で共通認識を作った 👈「初動でチームの方向性を決めれたためスムーズにできた」
Aさん「議事録多くてnotion管理難しかった!!」
Bさん「ミーティング欠席しても議事録あって次のミーティングに入りやすかった」 [1](URL Here)
Cさん「バック多すぎ。。。」
Bさん「個人個人の役割が明確化し良かった。」
 ‐Googleカレンダーで次のミーティングの決定
‐Googleカレンダーで次のミーティングの決定
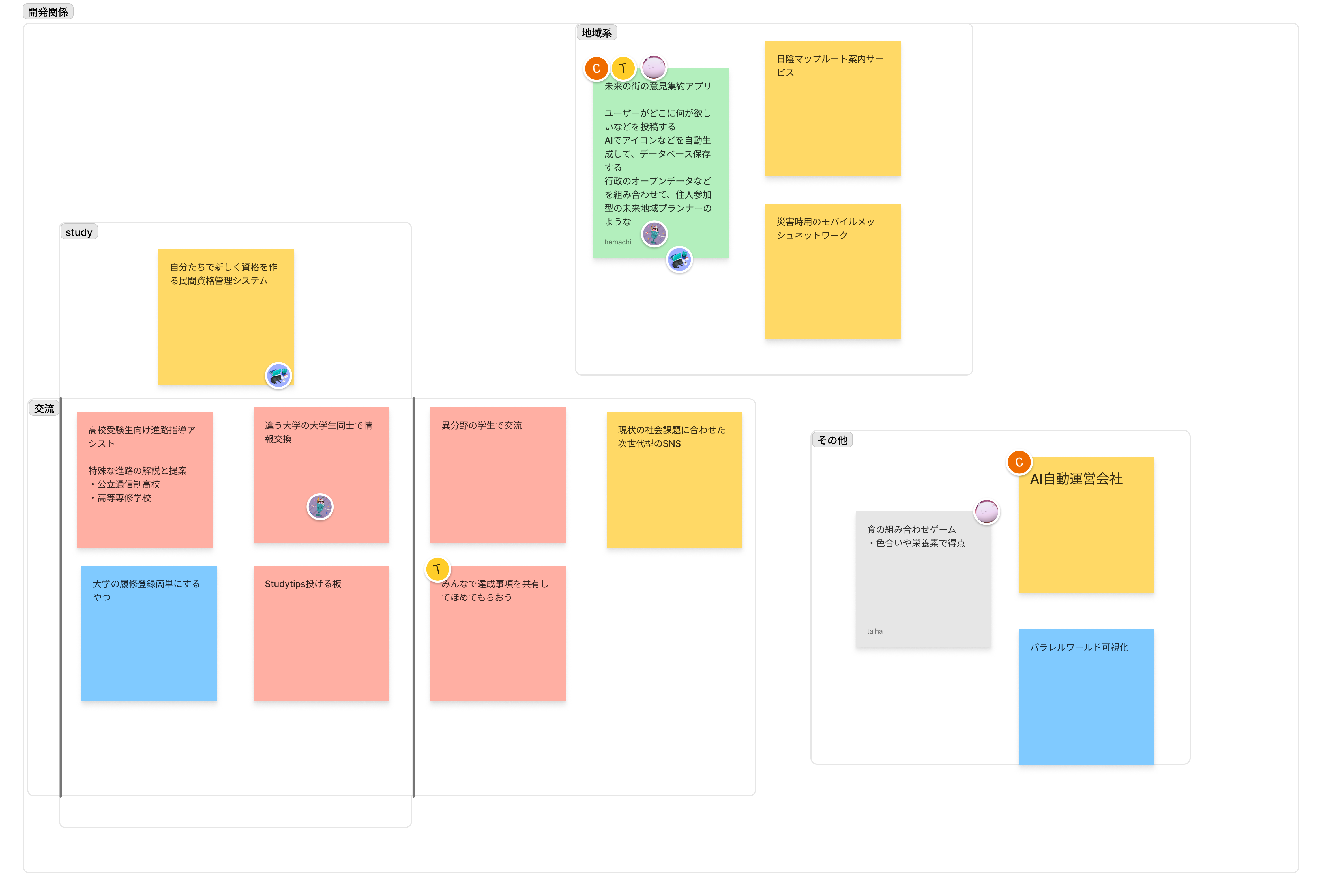
Aさん「ふせんはるの楽しかった!アイデアたくさんだせた」
Bさん「タイマーでアイデア出しの時間管理、アイデアのグルーピングができプロダクトの具体的なイメージが湧いた」
Dさん「簡単に画面の操作ができて楽しかった!!」
Bさん「必要なAPIがすぐ算出できた。バックが多数の中、これができてフロントのイメージが湧きやすかった」
私たちがこのサービスを作ろうと思ったきっかけは、「街に対するモヤモヤを気軽に言える場所がない」と気づいたことでした。
例えばチーム内で話題になったのは、
自転車専用の道路があるのに、歩道を走る自転車が多くてぶつかりそうで怖い
駅前の不正駐輪が多く、通行の邪魔になって困る
こうした小さな不安や不満は、日常の中で誰もが一度は感じること。でも「役所に言うほどではないかな」と思って結局そのままにしてしまいます。私たち自身もそうでした。
でも、もしそれを気軽にシェアできて「自分だけじゃなく、みんなも同じことを思っていた」とわかればどうでしょう。共感できるだけでも安心できるし、それが集まれば「この街に必要な改善は何か」という具体的なヒントになります。
私たちが目指しているのは、「些細な声が街の未来を動かすきっかけになる世界」です。 気軽に参加できるからこそ、普段は政治や街づくりに関心の薄い若い世代も自然に巻き込まれていく。そして、集まった声が地域課題の可視化につながり、行政やコミュニティが動きやすくなる。
最終的には、街の一人ひとりの気づきが積み重なって、「市民みんなで街の未来を創っていく仕組み」が実現できるのではないかと考えています。
サービスを作るにあたって、まず「どんな人が、どんな場面で使うのか」をイメージすることから始めました。
最初に行ったのは、身近な人へのヒアリングです。友人や家族に「街に対して普段どんな不満や疑問を持ってる?」と聞いてみると、予想以上に多くの声が出てきました。 「街灯が暗くて夜道が怖い」 「ゴミの分別ルールがわかりにくい」 「道路がデコボコしていてベビーカーが押しづらい」 など、日常生活の中で感じるちょっとした不便や不安がたくさんあることがわかりました。
そこから設定したペルソナはこんな感じです。
10代後半〜20代前半の若い世代
政治や行政には関心が薄いが、SNSは日常的に利用している
街に対して小さな不満や疑問はあるけど、伝える場がない
こうした人たちが気軽に参加できることが、このサービスを広げるうえで重要だと考えました。
また、開発のロードマップとしては次のような段階を計画しました。
気軽に投稿できる仕組みを作る(まずは声を集めることが第一歩)
賛同やコメントで声を広げる機能を追加する(「共感」が見えると投稿が増える)
集まった声を街や地域ごとに可視化する(データとしての価値を生む)
将来的には行政や団体とつなげる(市民の声が政策や改善に役立つようにする)
さらに当初は、「地図で具体的に不満のある場所を指定できるサービス」にしたいと考えていました。ただ、単に場所を示せるだけでは人々が積極的に発言するきっかけにならないのでは?という悩みがありました。どうすれば「気軽に声を上げやすい雰囲気」を作れるか。ここは開発前から特に頭を悩ませた部分です。
最終的に僕たちは、まずは 「気軽さ」 を最優先し、SNS感覚で投稿できる形から始めることにしました。将来的に地図や位置情報と組み合わせる発展も視野に入れつつ、まずは「人々の声を引き出す工夫」を積み重ねていこうと考えています。
「街の声」には、誰でも気軽に参加できるようにシンプルで直感的な機能を用意しました。
・声を投稿する 日常で感じた街への不満や疑問を、SNS感覚で投稿できます。 「歩道の段差がベビーカーで大変」「夜道の街灯が少なくて不安」といった小さな気づきもOK。
・共感・コメントする 他の人の投稿に「いいね」や「賛同」で共感を示せます。 また、自分の意見や体験をコメントで共有することも可能です。
・街ごとの声を可視化 投稿はエリアごとに整理されるので、「自分の街では何が課題になっているか」がひと目でわかります。 将来的には地図上で具体的に課題を表示できるようにする構想もあります。
匿名で安心して利用 実名を出さずに投稿できるため、気軽に声を届けやすい環境を整えています。
今はまず「声を集めること」を第一のゴールにしていますが、これからは以下のような機能追加も予定しています。
行政や地域団体とつなげる仕組み
投稿を分析してトレンドや共通課題を自動で抽出するダッシュボード
場所を指定して課題を共有できる地図機能
小さな投稿が集まり、それが見える形になることで「自分たちの声が街を動かす一歩になる」――そんな体験を提供していきます。
今回の「EmpaCity」は、ハッカソンをきっかけに生まれたプロダクトです。短い時間で形にする必要があったので、まずは「声を投稿して共感できる」というシンプルなコア機能に絞りました。
これからは、ハッカソンで得たフィードバックをもとに以下のような発展を考えています。
地図連動型の課題可視化 投稿をマップ上に表示して、どこでどんな声が多いのかを見えるようにする。
トークン&バッジの拡張 参加や提案が街づくりにつながったときにトークンや称号を与え、ゲーム感覚で続けられる仕組みを強化。
行政・団体との接点 市民の声を行政や地域団体へ届け、実際の改善につなげられる「橋渡し役」として進化させる。
全国規模の課題共有へ 最終的にはエリアを越えて、日本全体で課題や改善案を共有できる基盤に広げていきたい。
ハッカソンで「形にする」ことはできましたが、ゴールはまだまだ先にあります。これからユーザーや街のみんなと一緒にアップデートを重ねながら、「声が未来を動かすプラットフォーム」を目指して進化させていきたいです。



