推しアイデア
シャドウバースの新作が出たらしいので、よりよい「次のシャドウバース」を提案しているところ
シャドウバースの新作が出たらしいので、よりよい「次のシャドウバース」を提案しているところ
めんこやりたいから
Dynamodb Streams + API Gateway でリアルタイム通信をデータの損失なく行っているところ
Cygames より配信されている「Shadowverse」というゲームをインスパイアした、日本の伝統芸能「めんこ」を取り入れた全く新しいカードゲームです。 リアルタイム通信を用いて、1vs1の対戦ができます。
ゲーム開始直後、ユーザーには手札が配られます。
PP を消費することで、カードをプレイする(場に出す)ことができます。攻撃力、体力を持ったカードを特に「フォロワー」と呼びます。
フォロワーをプレイしたとき、「メンコチャレンジ」が発動します。
メンコに成功する(=相手のメンコをひっくり返す)と...
相手のフォロワーを、無料で一枚破壊することができます!!!
AWS ハッカソンなので、AWS リソースとそれ以外の部分で語っていきます。 チームとして新しく使用した技術には 🌟をつけておきます。
インフラ構成図
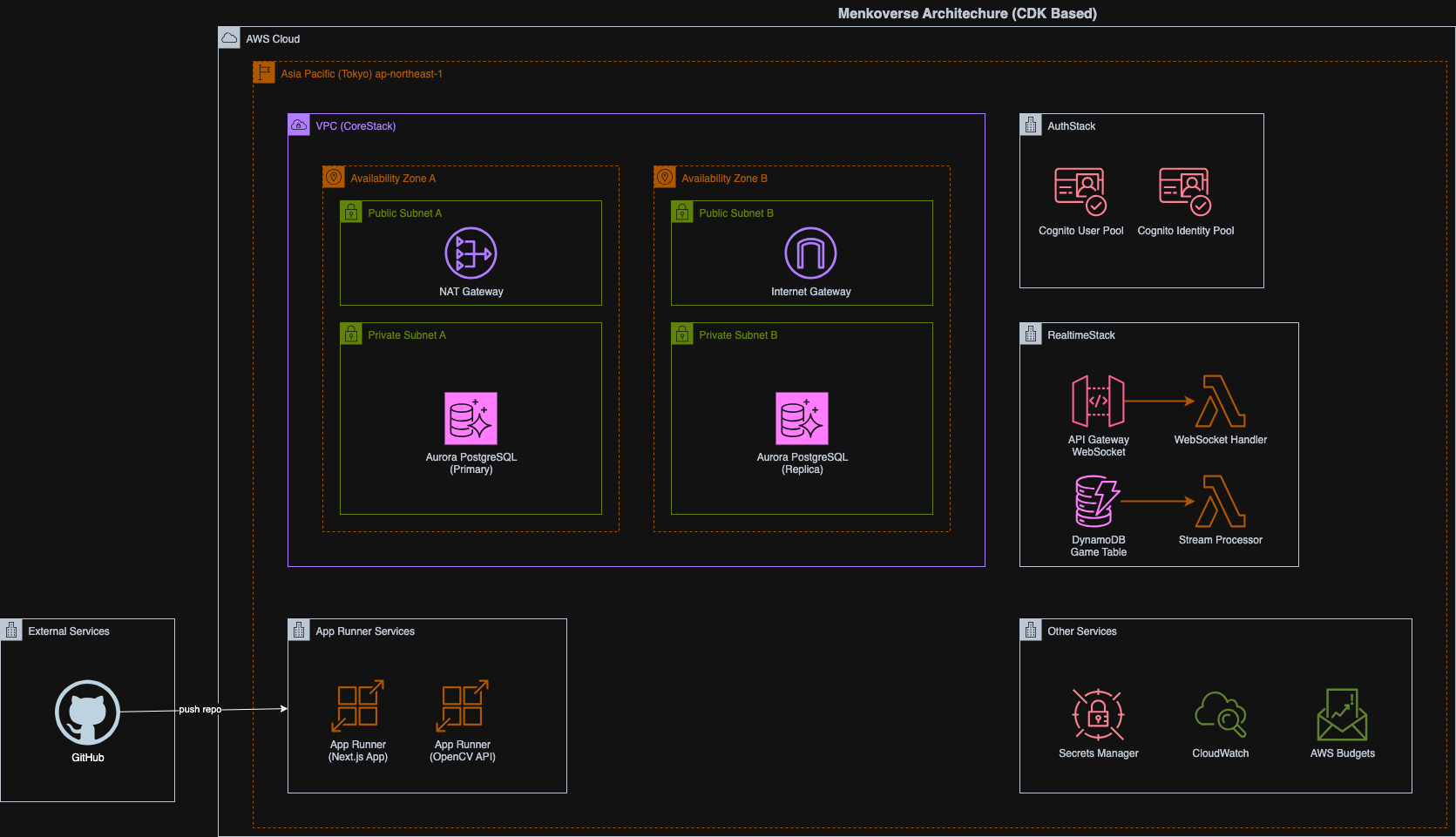
前提として、すべてのリソースは CdkStack として管理しています。 個別にデプロイできるよう、Stack を別々に分けておくことで各々の作業を止めないようにしました。リソースも関心ごとに分けています。
$ cdk list MenkoverseApp-dev Menkoverse-dev-Core Menkoverse-dev-Auth Menkoverse-dev-Data Menkoverse-dev-Realtime Menkoverse-dev-App
フロントエンド側の Auth.js と併せて使っています。Cognito は Amplify などの併せ技で使ったことはありましたが、今回のような t3-stack との統合は初めてです。 Auth.js では Cognito Provider が実装されており、これによってアプリ側からプロバイダの差異を気にせずに実装できました。
Auth.js | Cognito https://authjs.dev/getting-started/providers/cognito
RDS と比較して、非活動時に自動で停止することでコストを抑えてくれたりするメリットがあります。 ちなみにクエリ言語は PostgreSQL です。
Amazon Aurora Serverless | AWS https://aws.amazon.com/jp/rds/aurora/serverless/
リアルタイム通信を実装するため、API Gateway の機能の一つ、WebSocket API を使用しました。 ただし、websocket 通信はパケットが必ず届くとは限りません。フォロワーの攻撃処理が届かず相手の画面では負けなかった、とか起こっちゃったら最悪ですね。 これを回避するため、DB の変更を検知して確実にデータがストリーミングされる DynamoDB Streams を使用してイベント型で処理するようにしています。
チュートリアル: WebSocket API、Lambda、DynamoDB を使用して WebSocket チャットアプリを作成する - Amazon API Gateway | https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/websocket-api-chat-app.html
ちなみに、DB の変更を検知して処理する部分は supabase の subscribe の挙動を参考にしています。だいたい同じようなことが内部で起きているはず。たぶん。。。
Subscribing to Database Changes | Supabase Docs https://supabase.com/docs/guides/realtime/subscribing-to-database-changes
アプリケーション部分は AppRunner にデプロイしています。 EC2, Fargate と使用してきましたが、こちらは
などなど、時間がないハッカソンでは神的にいいサービスでした。これからも使います。


折り紙で作成 参考動画 事前にARマーカーを発行して、それをメンコに貼り付ける
 ※事前にテスト的に作って、メンコで遊べることを確認済み
※事前にテスト的に作って、メンコで遊べることを確認済み
AI 開発において重要なのは「工程の意識」だと思っています。単に「テトリスを作って」と丸投げするより、「テトリミノを作る実装方法を検討して」「関連する実装ファイルを調べ、まとめて」「これまでの情報をまとめ、実装して」と段階を踏んで指示したほうが的確な指示が得られます。 今回は、これをカスタムプロンプトによって実現しました。先に全体像を示しておきます。
# 基本 - 日本語で応答すること - 必要に応じて、ユーザに質問を行い、要求を明確にすること - 作業後、作業内容とユーザが次に取れる行動を説明すること - 作業項目が多い場合は、段階に区切り、git commit を行いながら進めること - semantic commit を使用する - コマンドの出力が確認できない場合、 get last command / check background terminal を使用して確認すること ## develop 作業を以下のように定義する - 「調査」と指示された場合、都度 .docs/reports/yyyymmdd/title.md に記載すること - 「計画」と指示した場合、.docs/plans.md に計画を記載する - 前回の内容が残っている場合は、読まずに消して構わない - コードベース / .docs を読み込み、要件に関連性のあるファイルパスをすべて記載すること - 不明な点については、fetch mcp を使用して検索すること - 必要最小限の要件のみを記載すること - このフェーズで、コードを書いては絶対にいけない - ユーザが「実装」と指示した場合、.docs/plans.md に記載された内容に基づいて実装を行う - 記載されている以上の実装を絶対に行わない - ここでデバッグしない - 「デバッグ」と指示された場合、直前のタスクのデバッグ「手順」のみを示す
あらためてカスタムプロンプトによって各工程を定義しておくことで、AI の場当たり的な行動を防ぎ、安定した挙動を期待することができます。
ちょうど Progate ハッカソンのキックオフでいい感じの資料があったので、これをもとに話します。
- 「調査」と指示された場合、都度 .docs/reports/yyyymmdd/title.md に記載すること
アイデアの検討自体は人間がやるとして、実現可能性を調べるのは AI にも任せられそうです。そこで、レポートとしてファイルに書き出してもらい、それを人間がレビューすることで調査していきます。 後述しますが、各種 mcp は主にここで使ってもらいます。
例として、「AR.js について、<参考記事>の実装パターンについて確認して現在と差分を取って」と投げたら以下のようなレポートを書いてくれました。
# AR.js Blog Pattern Implementation ## 日付: 2025/01/11 ## 概要 参考ブログ(https://blog.kimizuka.org/entry/2022/03/01/163300)のAR.js実装パターンを調査し、現在の実装を修正するための指針を確認した。 ## 参考ブログのパターン ### 重要な実装要素 1. **THREE.jsの事前読み込み** - `import * as THREE from '~/scripts/three.module'` - `window.THREE = THREE` で明示的にグローバルに設定 2. **AR.js動的読み込み** - scriptタグを動的に作成してAR.jsを読み込み - 読み込み完了後に `window.THREEx` が利用可能になる - 使用後はscriptタグを削除
- 「計画」と指示した場合、.docs/plans.md に計画を記載する - 前回の内容が残っている場合は、読まずに消して構わない - コードベース / .docs を読み込み、要件に関連性のあるファイルパスをすべて記載すること - 不明な点については、fetch mcp を使用して検索すること - 必要最小限の要件のみを記載すること - このフェーズで、コードを書いては絶対にいけない
調査を繰り返し、方針が定まったら計画に移ります。plan.md に現状と方針を書き出してもらい、人間がレビューします。
「DynamoDB によるリアルタイム通人の部分を実装する計画を書いて」とお願いしたときのがこんな感じ。
# DynamoDB Only リアルタイム通信システム最小実装計画 ## 設計方針 ### 最小実装の考え方 - **DynamoDB Streamsのみ使用**: SQSなどの複雑な仕組みは使わない - **シンプルなWebSocket配信**: 失敗時の再試行は最小限 - **基本的な接続管理**: 高度な障害復旧機能は後回し - **必要最小限のテーブル構造**: Single Table Design ### 前提条件 - DynamoDB Streamsによる変更検知 - WebSocket APIでのリアルタイム配信 - 基本的なエラーハンドリング - 開発・テスト環境での動作確認 ## 実装スコープ ### 含める機能 1. **DynamoDBテーブル設計**: ゲームデータの保存 2. **DynamoDB Streams**: 変更検知 3. **WebSocket API**: リアルタイム配信 4. **Lambda関数**: Streams処理とWebSocket配信 5. **接続管理**: 基本的な接続状態管理
- ユーザが「実装」と指示した場合、.docs/plans.md に記載された内容に基づいて実装を行う - 記載されている以上の実装を絶対に行わない - ここでデバッグしない
これはシンプルで、 さきほど書いた plan.md を参照して実装してくれます。逆にそれ以外の実装は行わせないようにすることで、想定外の挙動をある程度防いでいます。
ここは主に人間の仕事です。 僕は difit か GitHub PR の diff を見てレビューしていました。
Git diff閲覧ツール「ReviewIt」が「difit」に変わります| https://zenn.dev/yoshiko/articles/difit-from-reviewit
強いて挙げるなら、重要なタスクには GitHub Copilot for Review をつけてました。Premium Request を消費してしまいますが、けっこういい感じの修正案をくれます。
AI Agent の行動範囲を広げるため、MCP tools の導入を行いました。ここでは fetch MCP を例に挙げます。 調査タスクなどで積極的に web 検索を行ってもらうことで、最新の情報を取り入れ、より強固な案を練られるようにしました。
- 「計画」と指示した場合、.docs/plans.md に計画を記載する - 前回の内容が残っている場合は、読まずに消して構わない - コードベース / .docs を読み込み、要件に関連性のあるファイルパスをすべて記載すること - 不明な点については、fetch mcp を使用して検索すること - 必要最小限の要件のみを記載すること - このフェーズで、コードを書いては絶対にいけない
fetch MCP の導入についても記事にしてます。よければ。
【Fetch MCP】GitHub Copilot に Web 検索をさせよう https://zenn.dev/ulxsth/articles/a10c2ef7ad0866
CFn テンプレート を GUI で触れるサービスがあるらしいぞと知り、「CFn to CDK さえできれば GUI で CDK 掛けるんじゃね?」と考えて実装してみました。仔細は記事にしたので読んでください。
【AWS】CDK を GUI で書いてみる |よつhttps://zenn.dev/progate_users/articles/420552b897fe6e
VSCode 上で GUI をいじいじしながら CDK が生成されるのはけっこうおもろい。

結論としては、まだ実用には耐えないなーと思います。CDK to CFn の手段がない(正確には SAM テンプレートに対応した変換がない)ので、逆方向の変換が聞きません。これはつまり、「CDK ファイルが編集できない」ことになります。 GUI 側のファイルが SSoT になってしまう以上、手書きしたければ SAM あり CFn を書くことになります。これは当初の見込みと違っていたので、途中から使用を停止しました。
余談ですが、AI Agent の対応も CDK のほうが正確な感じがしました。おそらく CFn に比べ行数が抑えられていること、ネット上の情報数において CDK が上回っていることなどがあるかなと思います。
Web カメラの前でチャーハンを食べていたらマーカーだと認識された時の画像です。なんで?