










推しアイデア
タイピングゲームに「条件付きで単語を答える」機能を設けてみた
タイピングゲームに「条件付きで単語を答える」機能を設けてみた
「2」人以上が遊べるゲームなので ← すごい
100 名規模のゲームを無料構成でさばいているところ(Full-Stack TS で!)
IT 用語をたくさんタイピングして点数を稼ぎ、友人と競うリアルタイムタイピングゲームです。
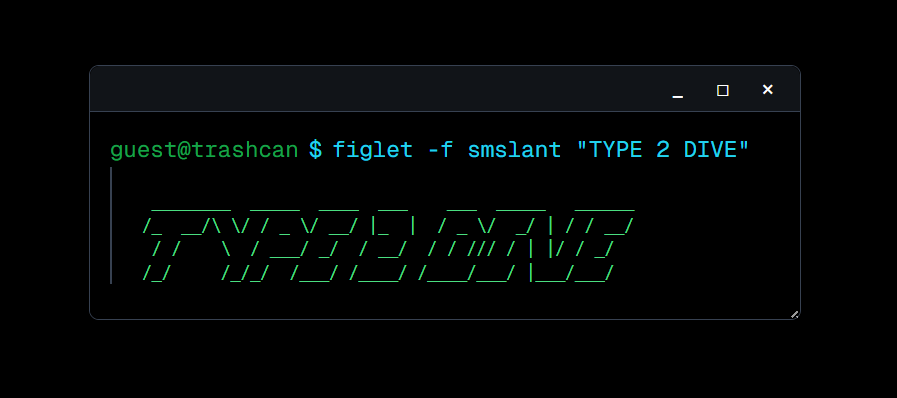
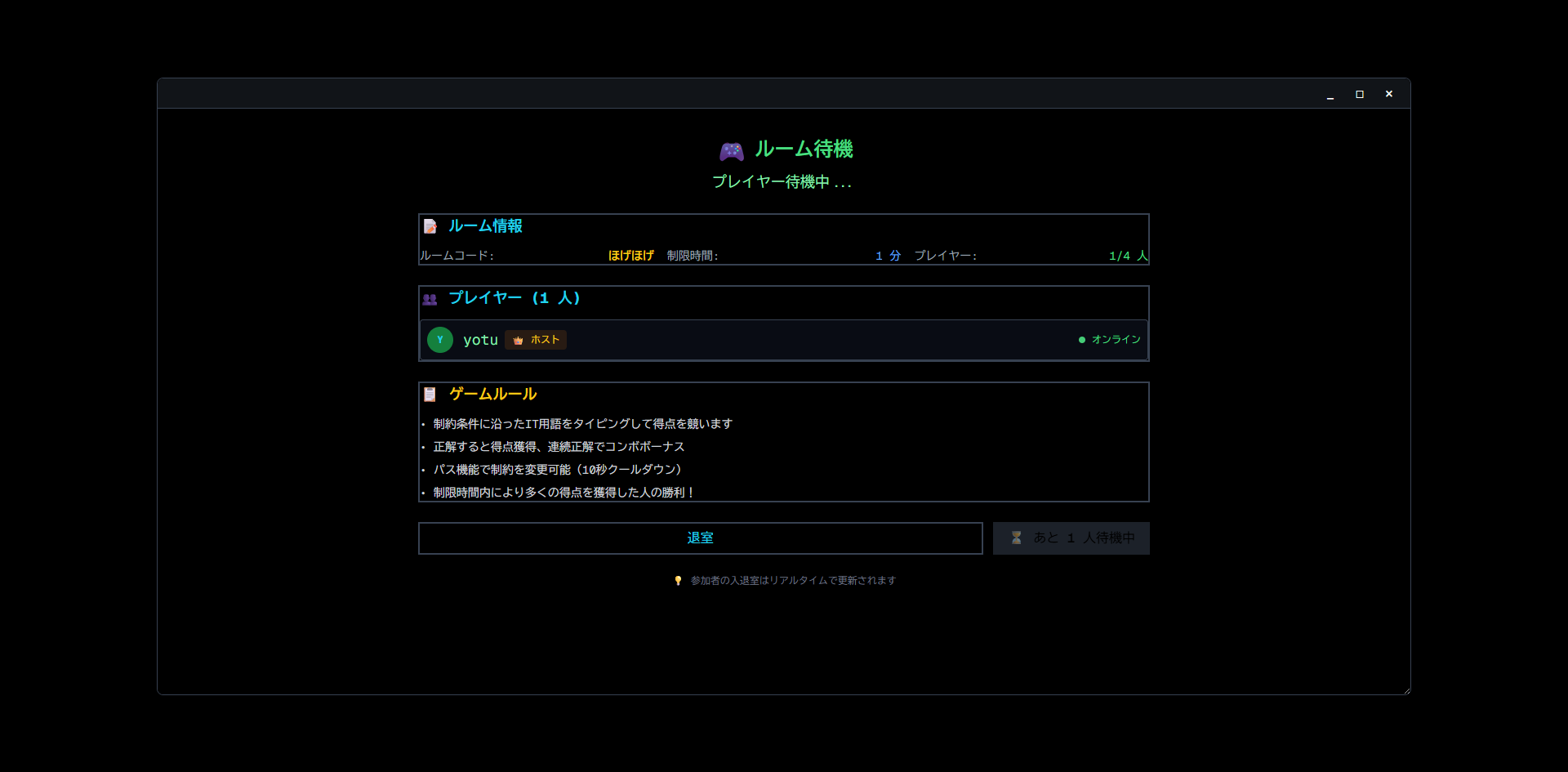
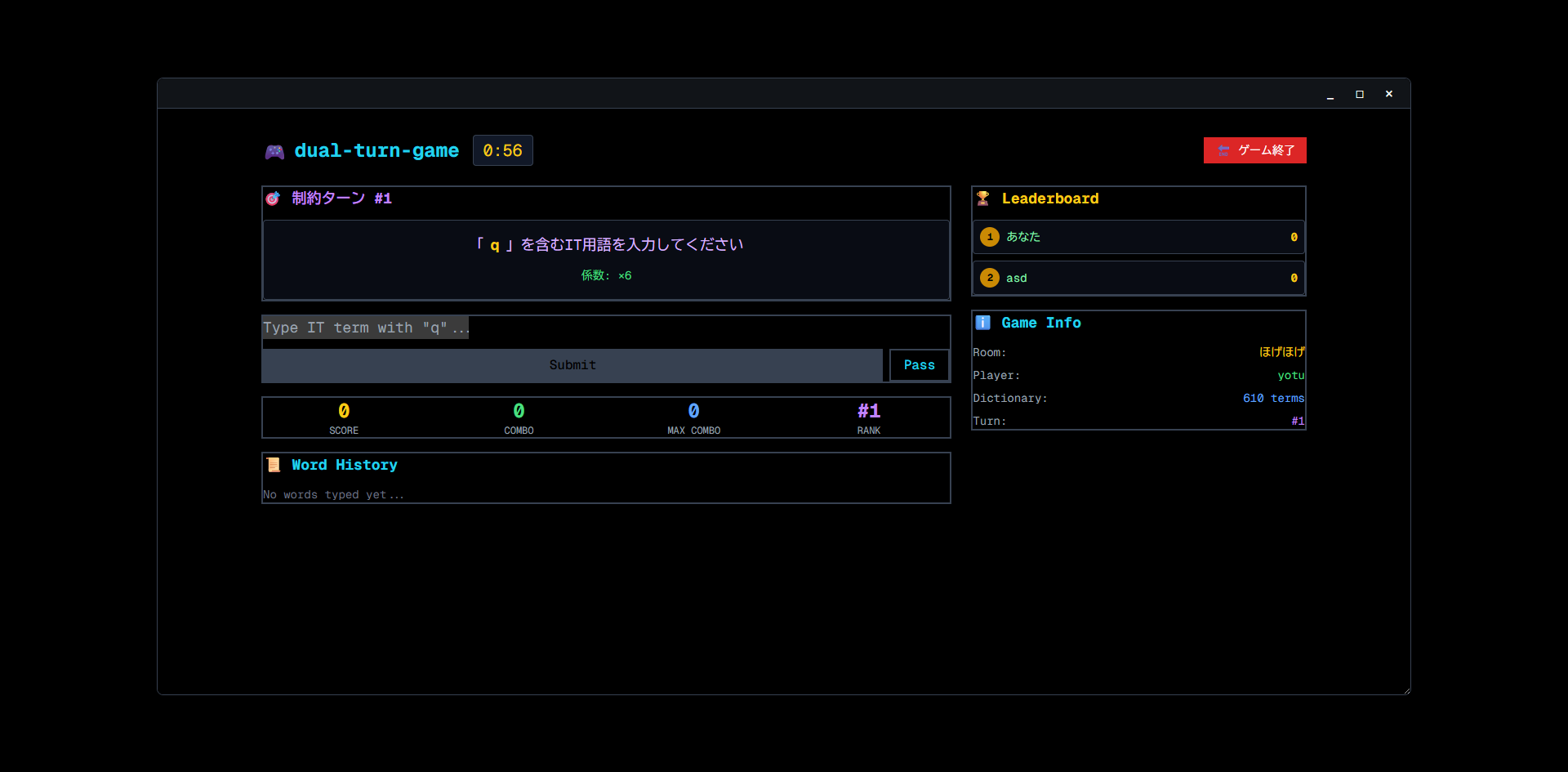
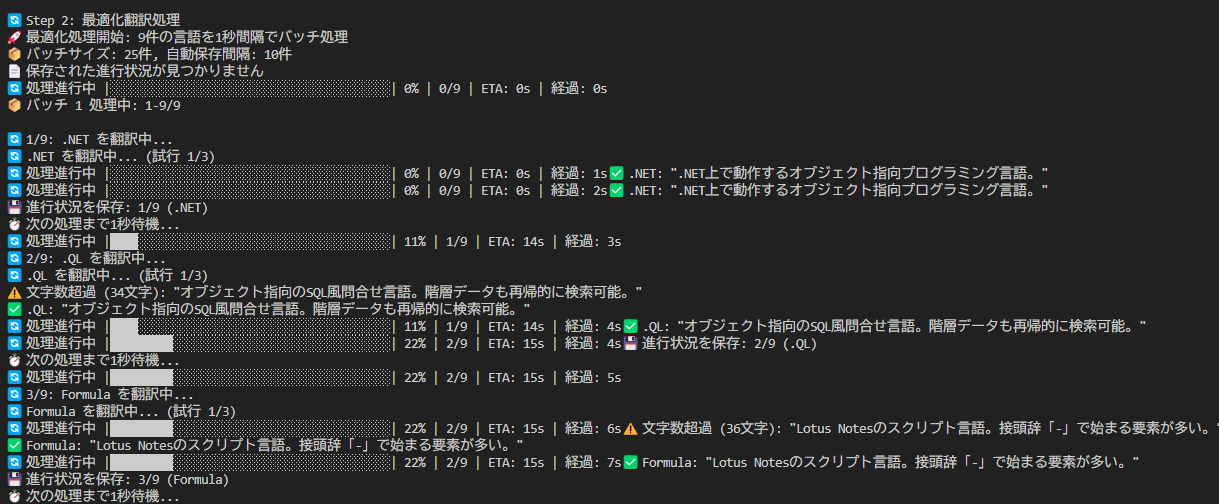
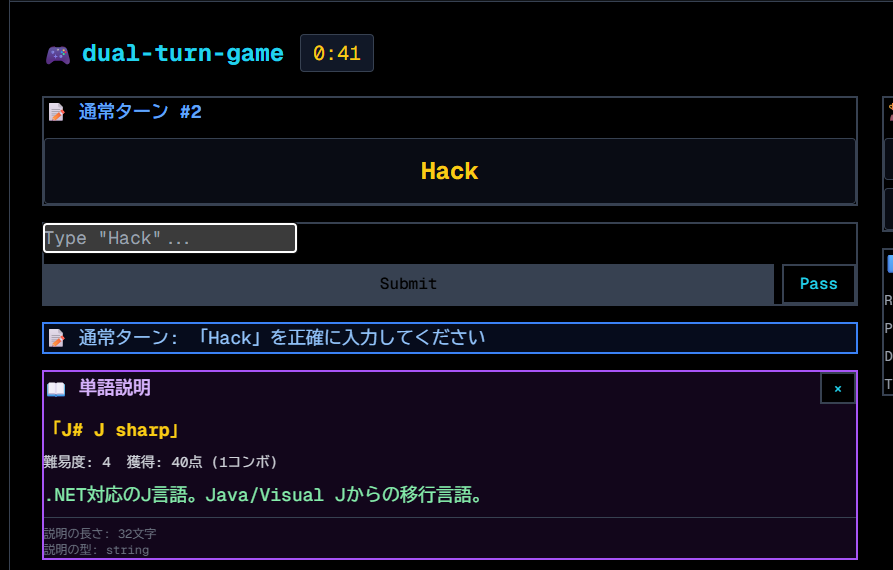
通常のタイピングと同様、単語が出てくるのでそれを入力する形で進行します(画像左)。 ただのタイピングゲームだと面白くないので、「制約ターン」というものを設けてみました(画像右)。
その名の通り「制約」の中で該当する単語を答えるターンです。たとえば「"a" を含む」という制約には「AWS」「Laravel」「Julia」などが該当します。
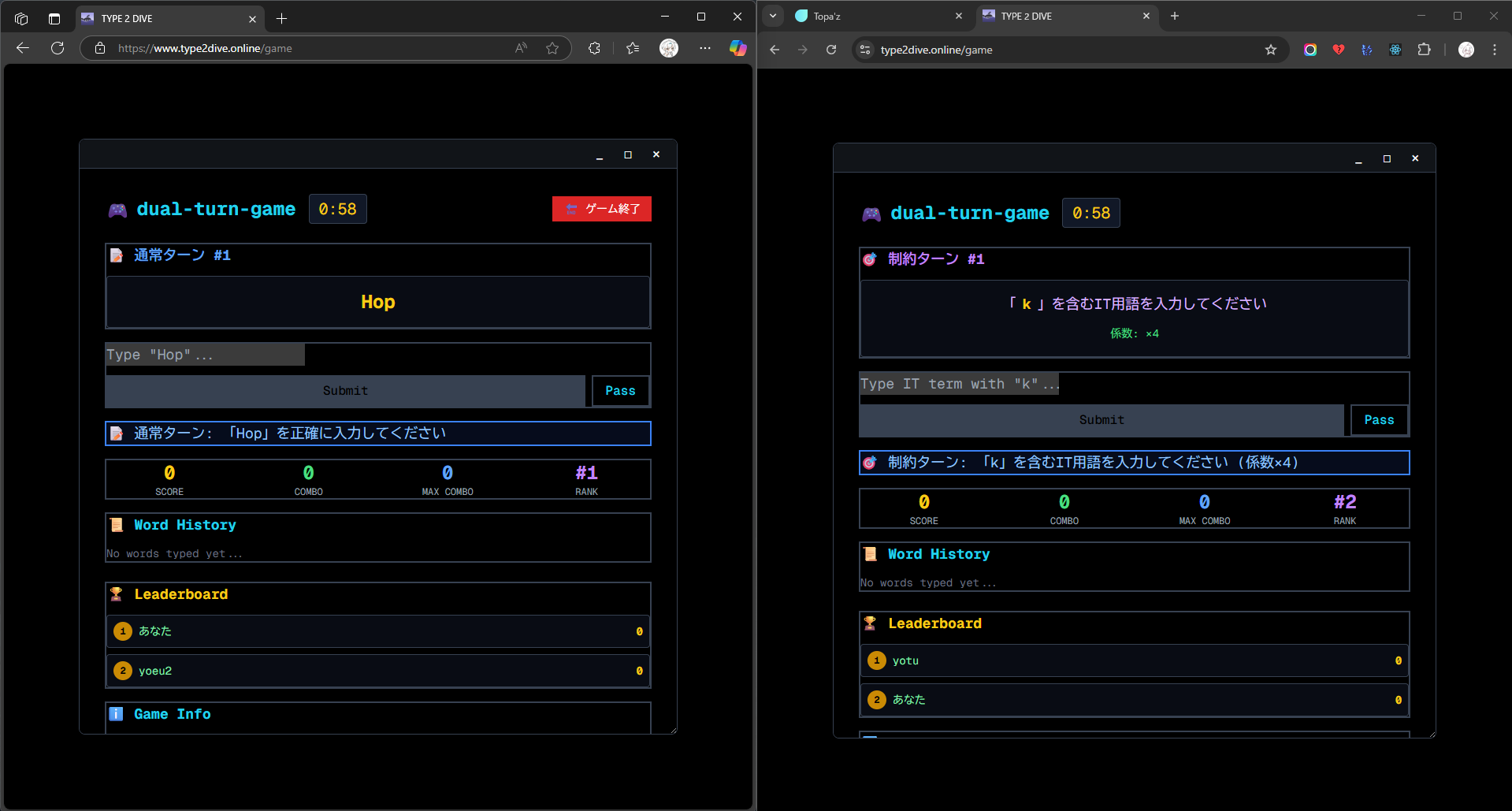
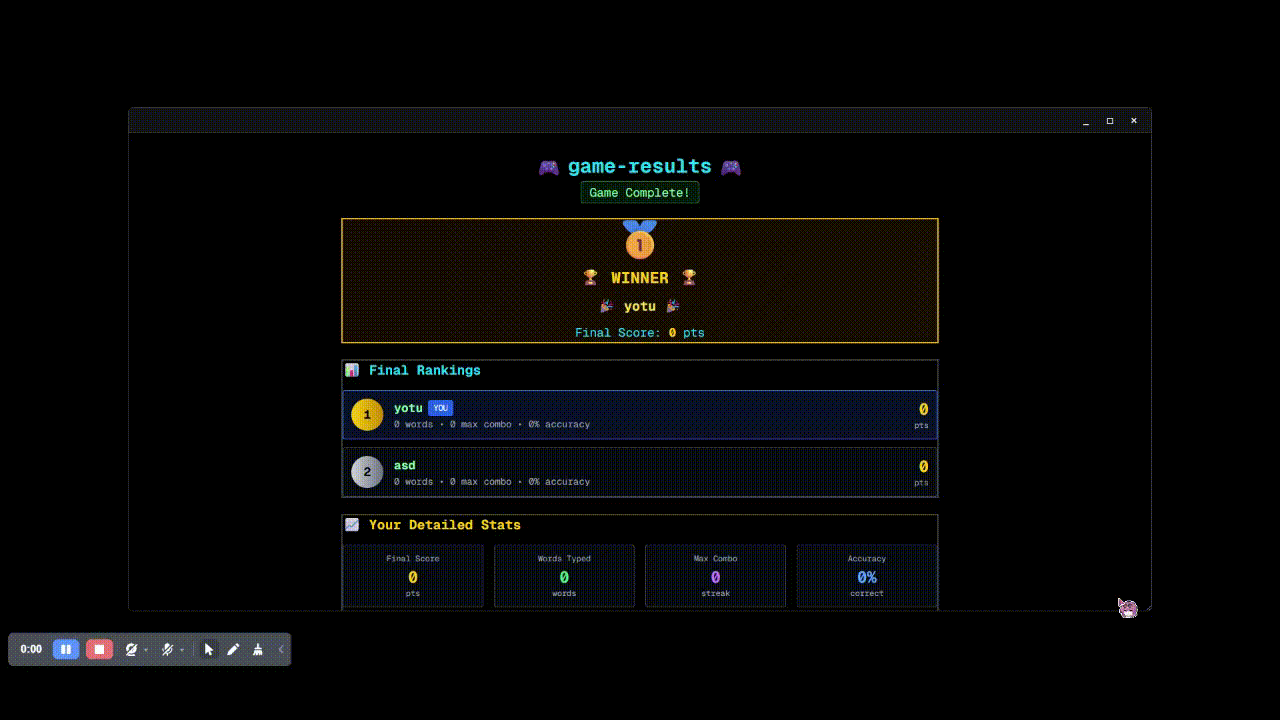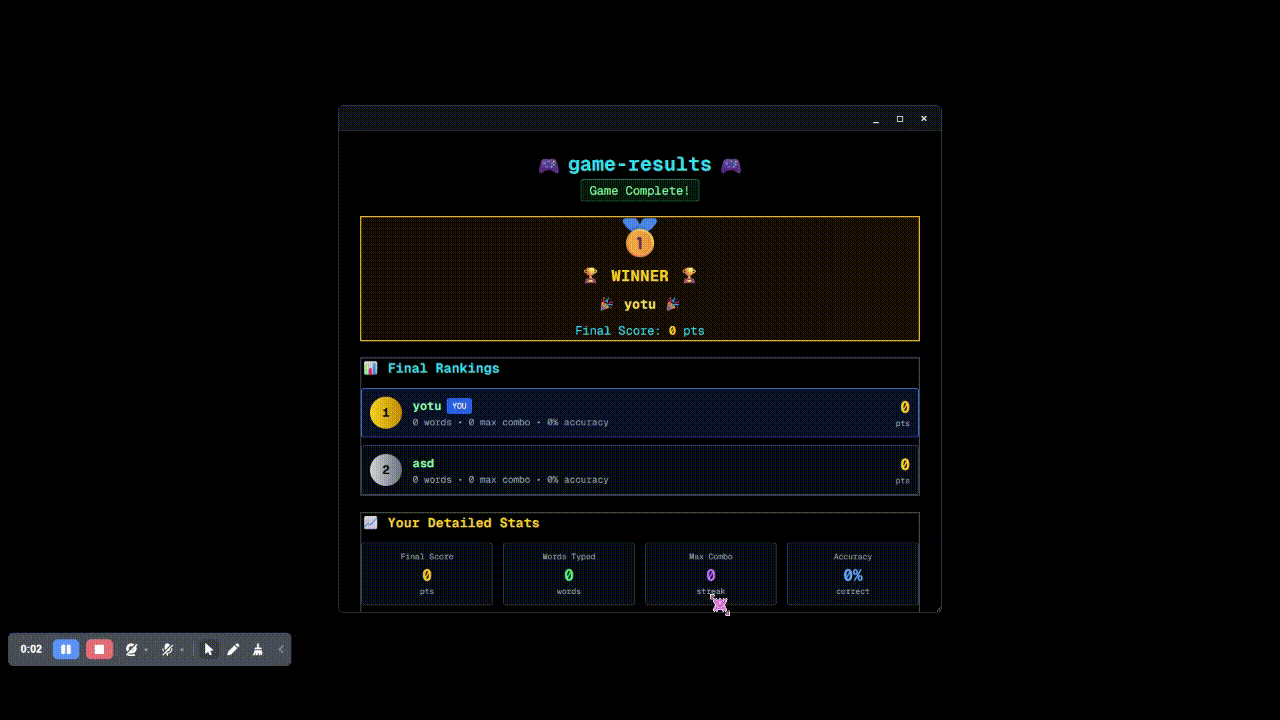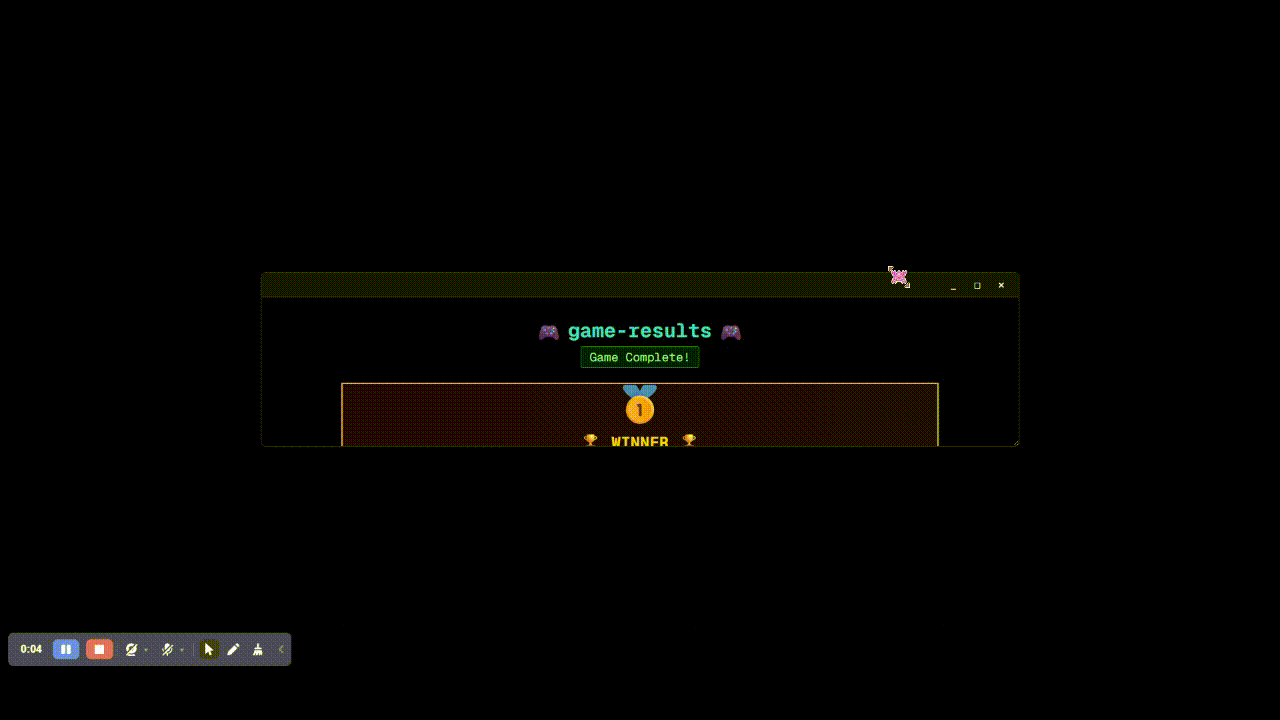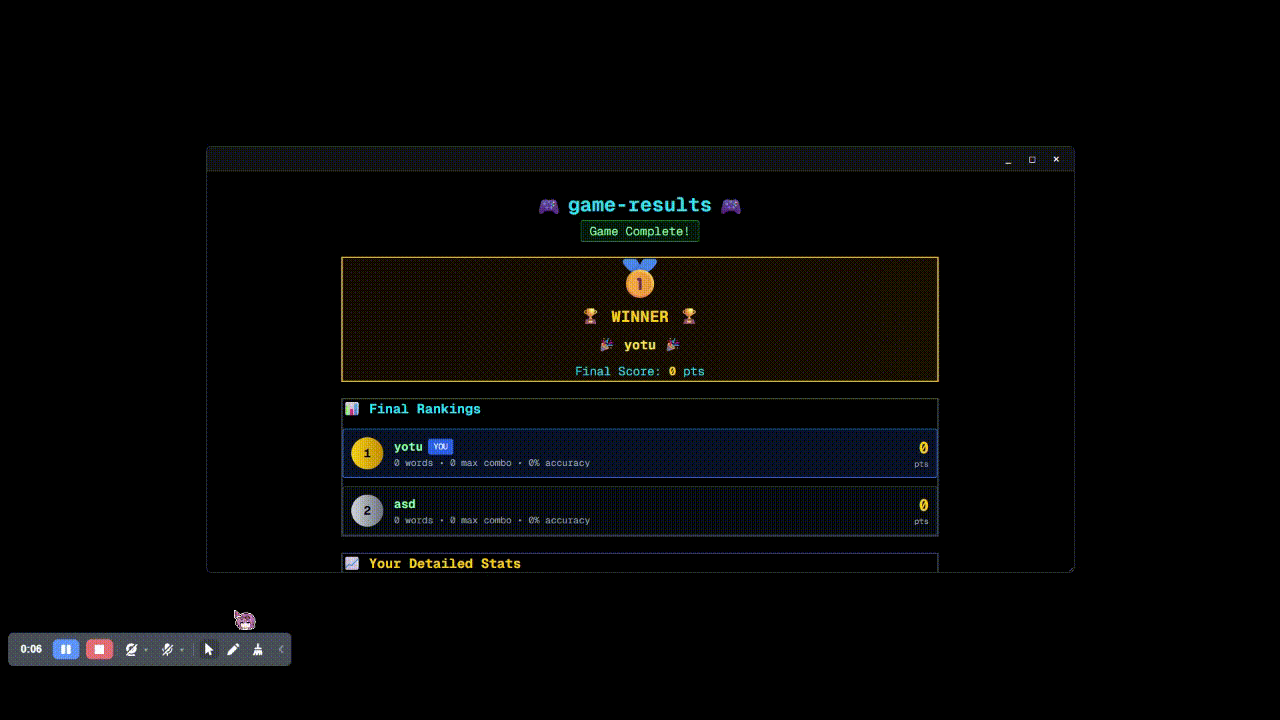
終了したらこんなかんじのリザルトが出てきます。
ターンによって違います。 「難易度」は単語の認知度に相当します。各単語の難易度設定については後述。
単語文字数 × 難易度 × 速度係数 × コンボ
速度計数は「どれだけ早く入力できたか」を指します。
単語文字数 × 難易度 × 制約係数 × コンボ
制約係数は「制約の難易度」を指します。 現在は文字縛りしか設けてないので、よく出る文字は低めに、なかなかない文字は高めに設定してます。
Vercel + supabase の超シンプル構成です。 バックエンドについてはいわゆるサーバレス構成(開発者がサーバーを管理せず、クラウドサービス等を利用して機能を実装管理する方式)でもあります。
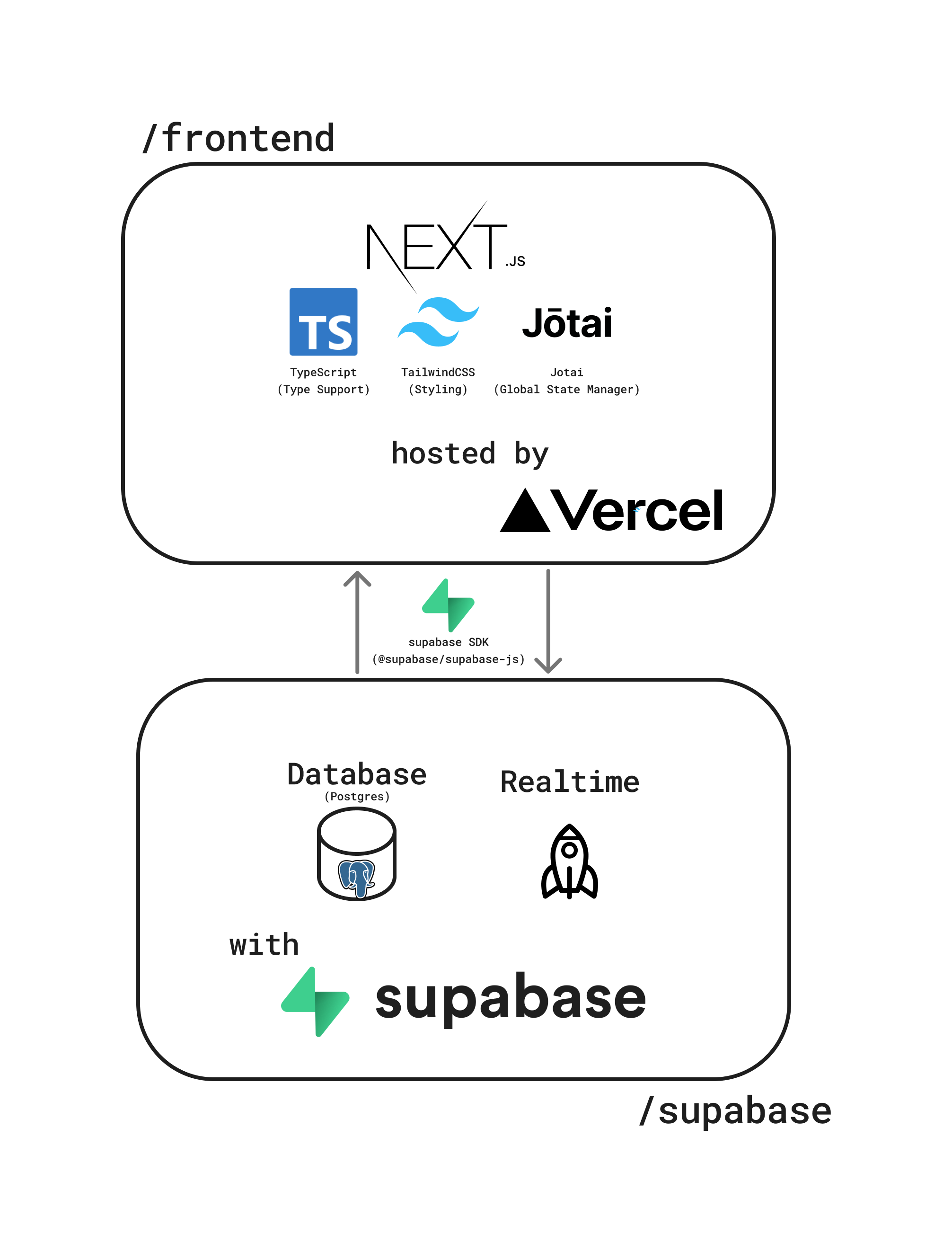
各技術について軽く解説します。
言わずと知れたフロントエンド構成です。 ハッカソンでの使用率は高めですが、バックエンド村の自分にとってはしっかりと使用した経験がなく、改めて使用したかったので採用しました。
JavaScript に型を追加した、上位互換の プログラミング言語 です。 今回はアプリ内のすべてを TypeScript で開発しています。小~中規模開発にはオススメ。
用意されたクラス名(例:font-16)を付与することで、CSS を書くことなくスタイルできる CSSライブラリ です。
Next.js 14 に tailwind v4 を導入予定でしたが、設定が悪かったのかうまく反映されず。やむなく v3 を使用しています。
グローバル状態を管理する、状態管理ライブラリ です。React に明るくない方向けに言い直すと、「ページをまたいで使いたいデータを一時保存するためのツール」といった具合でしょうか。 Web ブラウザは、ページを遷移するたびに必要のないデータを失います。そのため、サービス全体で使いたいようなデータ(例:ユーザーのidや名前)はどこかに保存しておく必要がありますね。こうした際に状態管理ライブラリを使用することで、どこからでも保存・取り出しが可能なデータ管理ができるというわけです。
React におけるグローバル状態の管理は
useContext()あたりが択としてありましたが、もっともシンプルかつ必要最小限の機能を持っている Jotai が安牌だと思ったので採用。
Next.js の開発元である Vercel 社が運用する PaaS(Platform as a Service) です。 GitHub リポジトリを連携することで、メインブランチの変更を自動検知してデプロイしてくれます(いわゆるCD)。
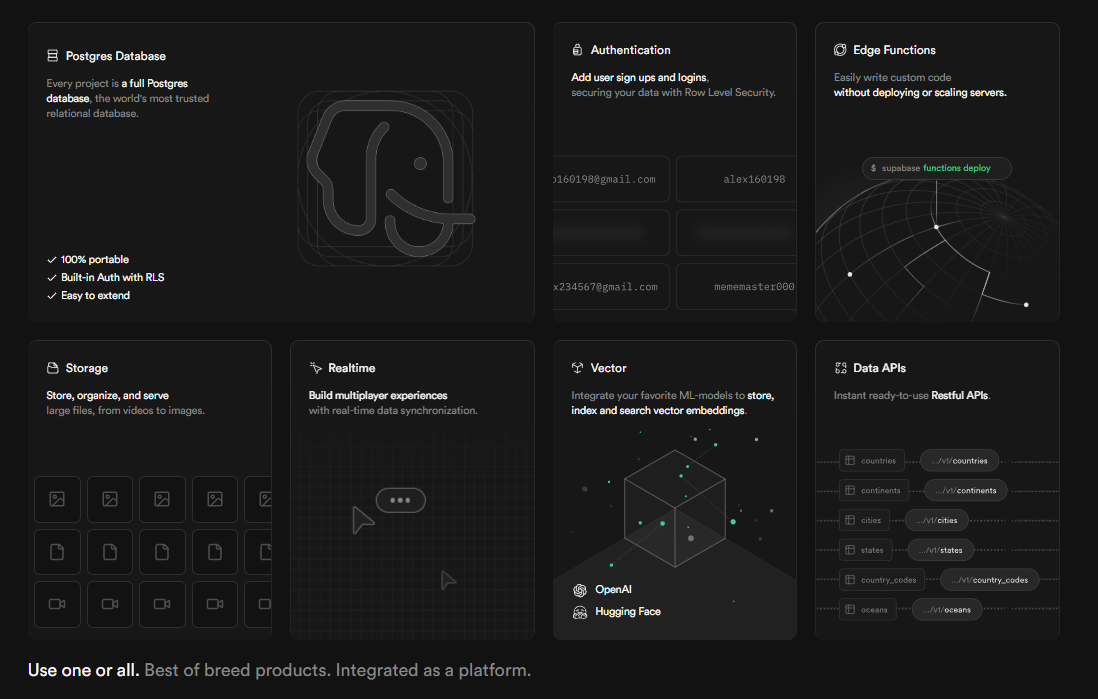
データ管理・リアルタイム通信の橋渡し の2つを解決するために使用した、PaaS(Platform as a Service) です。
supabase は、PostgreSQLをベースにした新しめのバックエンドサービスです。一応 Firebase の代替にあたります。 コア機能はデータベースの提供ですが、最近は認証機能・ストレージ(ファイル保存)・VectorDB などなど、各種拡張機能の強化が続いています。今回はその拡張機能からリアルタイム通信機能(supabase realtime)を使用した形になります。
余談ですが、初期構想として単語の管理をファイル形式で行おうとしていました(実装上の懸念から断念)。こうした仕様変更にも手が届くのが supabase のうれしみでもあります。
supabase typegen の型をリアルタイム通信に使いまわす一番やりたかったことです。
リアルタイム通信を行うにあたり、その通信の形式をどこかに定義する必要があります。これにより意図しないデータ構造のミスを防ぐことができますが、仕様の追加や変更にあたり、型を新しく定義したり変更したりする必要があります。
この手間をなくすため、通信データの型をDBのテーブル型と同じにすることで解決しました。
supabase のテーブル構造は、公式が出している CLI を使用することで TypeScript の型として抽出できます(supabase typegen)。抽出したものが以下。
// database.types.ts export type Database = { public: { Tables: { difficulties: { Row: { created_at: string description: string | null id: number ... } Insert: { created_at?: string description?: string | null id?: number ... } Update: { created_at?: string description?: string | null id?: number ... } Relationships: [] } game_sessions: { Row: { created_at: string current_constraint_char: string | null current_constraints: Json | null ... } Insert: { created_at?: string current_constraint_char?: string | null current_constraints?: Json | null ... } Update: { created_at?: string current_constraint_char?: string | null current_constraints?: Json | null ... }
not null などの条件に応じて、Insert や Updates などの場合の型定義もしてくれて超便利です。
が、このままでは使いづらいので、僕は分解してます。
// supabase.ts // 型安全なヘルパー型 export type Tables<T extends keyof Database['public']['Tables']> = Database['public']['Tables'][T]['Row'] export type Inserts<T extends keyof Database['public']['Tables']> = Database['public']['Tables'][T]['Insert'] export type Updates<T extends keyof Database['public']['Tables']> = Database['public']['Tables'][T]['Update'] // 使いやすい型エイリアス export type Room = Tables<'rooms'> export type RoomPlayer = Tables<'room_players'> export type GameSession = Tables<'game_sessions'> export type WordSubmission = Tables<'word_submissions'> export type ItTerm = Tables<'it_terms'>
こうすることで、以下のように使用時の記述量がちょっと減ります。
// before const { data } = await supabase.from('rooms').select('*') const rooms: Database['public']['Tables']['rooms']['Row'][] = data ?? [] // after const { data } = await supabase.from('rooms').select('*') const rooms: Room[] = data ?? []
勘のいい方ならお気付きかと思いますが、このデータベース型はリアルタイム通信に再利用できます。
channel.on('postgres_changes', { event: 'INSERT', schema: 'public', table: 'room_players', filter: `room_id=eq.${roomId}` }, (payload) => { debugLog('👥 realtime: プレイヤー参加イベント受信', payload.new) const newPlayer = payload.new as RoomPlayer onPlayerJoin(newPlayer) } )
こうすることでデータベースの変更にリアルタイム通信の型が自動で追いついてきてくれるので、開発体験がめっちゃよくなりました。
全体的にターミナルっぽい感じのデザインにしてみました。

こうした理由はほどんど趣味ですが、一応あとで UI をマルチウィンドウに分割する案がありました。例えばゲーム内の各コンポーネント(入力部分、ランキング、スコア表示...)を書くウィンドウに分割し、いい感じに並べたらカッコイイんじゃないかなと。 その名残として、ウィンドウのサイズ調整機能だけあったりします。
余談ですが、最初はすべてを CLI ツール(完全にテキストだけの表示)にしようとしてました。 さすがにシンプルすぎて絵面が終わっていたので最低限のコンポーネントを追加しましたが、その際に入れた絵文字がユーザ体験を底上げしているように見えてよかったです。メンターさんとのデバッグでは表示揺れ等ありませんでしたが、将来的にアイコン用ライブラリへの移行を検討したいな~とおもっています。

メインシステムからは反れますが、今回は用語も収集する方法を工夫してます。
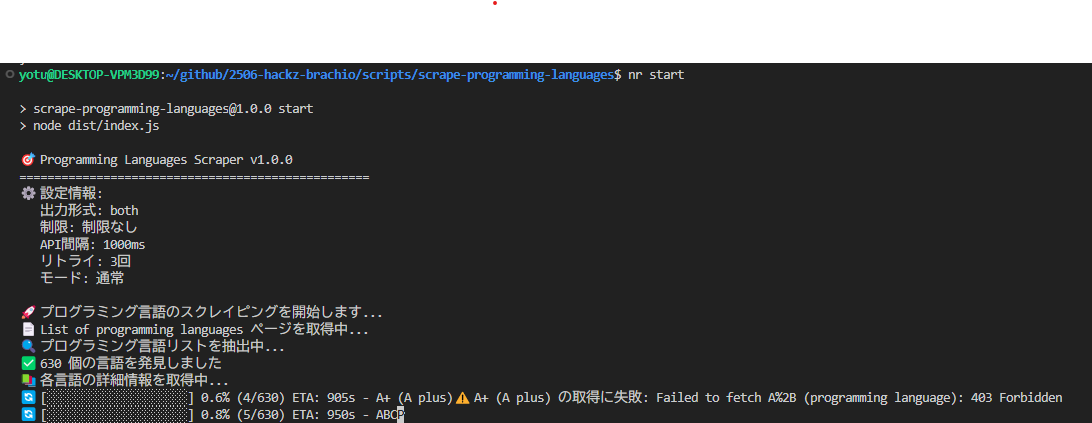
まず、単語を集める必要があります。今回は wikipedia API から拝借しました。
参照: List of Programming Langages | https://en.wikipedia.org/wiki/List_of_programming_languages
このページ内の各言語ページに対する URL (の情報を取得する API)に対し、順にリクエストを飛ばして取得しています。
(一部 403 エラーが出ますが、恐らくページが存在しない言語だと思います)

取得したデータは CSV に格納しています。言語の名前だけでなく、各ページの説明(上から3文)、年代等を追加で取得しています。
今回のゲームには学び要素を入れたかったので、以下のように説明文を入れる必要がありました。ただし、膨大な単語データに対して人間が入力するのは不可能に近いですし、私は全知全能ではないので各単語について解説する知識はありません。 また、同様に難易度も分析する必要があります。
ココに Gemini を投入しました。さきほど取得した wikipedia からの情報を渡すことで、日本語訳と難易度分析をまとめて解決しました。
Gemini 2.0 Flash には無料枠が存在するため、なるべくその範囲内におさまるように使用しました。
最終的に、こんな感じで正解後に表示されるようにしました。(用語の下に出したほうが良かったかも)
一人開発だと、時間と体力のリソース管理がマジで大事になってきます。 そのための工夫を紹介。
世間では Cloude Code やら Cursor やら Devin やらが流行っていますね。ちょうど先日も Google I/O で Jules が発表されたり、Xcode にも Agent モードがきたりと進化が続いています。
しかし、すべて有料 です。日々の食費にすら喘ぐ金欠学生にはそんなものは使えません。
ということで、学割で無料で使用できる GitHub Copilot for Agent を極限まで使用するためのスキームを用意して開発しました。
.github/copilot-instructions.md にプロンプトを書き込んでおくと、指示のたびにこのファイルに書かれたことを AI が認識します。
今回はこの機能を用いて、何度も実行するようなタスクを定型化しておき、動作を安定させるようにしました。
作業を以下のように定義する - 「調査」と指示された場合、都度 docs/reports に記載すること - 「計画」と指示した場合、tasks.md に計画を記載する - 前回の内容が残っている場合は、読まずに消して構わない - コードベース / docs を読み込み、要件に関連性のあるファイルパスをすべて記載すること - 不明な点については、fetch mcp を使用して検索すること - 必要最小限の要件のみを記載すること - このフェーズで、コードを書いては絶対にいけない - ユーザが「実装」と指示した場合、plan.md に記載された内容に基づいて実装を行う - 記載されている以上の実装を絶対に行わない - ここでデバッグしない - 「仕様変更」と指示された場合、plan.md, requirements.md を更新する - 「デバッグ」と指示された場合、直前のタスクのデバッグ「手順」のみを示す
このようにしておくことにより、
余談ですが、以下の指示をボイラープレートとして差し込んでおくと細かい場面でうまく動いてくれます。
- 日本語で応答すること - 必要に応じて、ユーザに質問を行い、要求を明確にすること - 作業後、作業内容とユーザが次に取れる行動を説明すること - 作業項目が多い場合は、段階に区切り、git commit を行いながら進めること - semantic commit を使用する - コマンドの出力が確認できない場合、 get last command / check background terminal を使用して確認すること
GitHub Copilot には、mcp tool を追加できる機能が存在します。これは言うなれば「AI 専用ツールを用意してあげる」と表現できます。
たとえば fetch MCP。これは AI が何かしらの検索タスクを行う際、実際に Web 検索を使用して情報を収集することができる機能です。
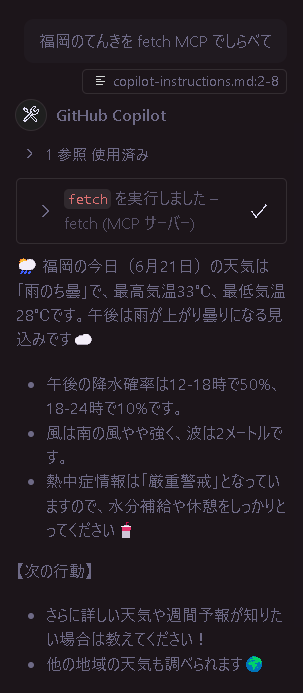
これと前述のプロンプトを組み合わせ、効率的に調査タスクを実行できるようにしています。
- 「調査」と指示された場合、都度 docs/reports に記載すること - 不明な点については、fetch mcp を使用して検索すること
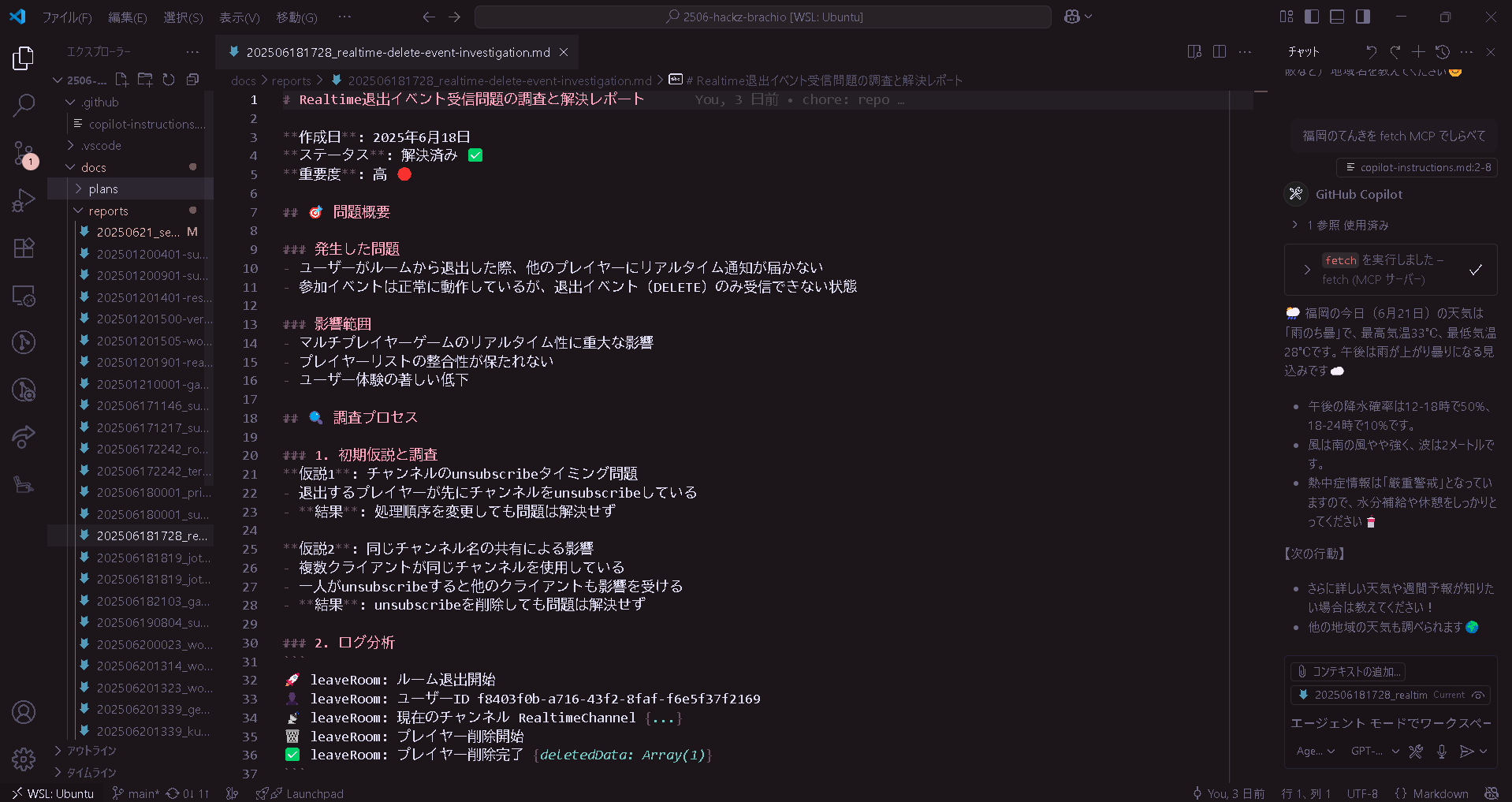
レポートはこんな感じ。実装方法の比較検討、バグの前例探し、コスト比較調査などなど、使いどころは無限にあります。
これが一番早いと思います。 左がホワイトゴレイヌ、右がブラックゴレイヌです。




