












推しアイデア
機械学習 X クラウドが今やばい! メンタルを機械学習でさらに支えちゃうの!
機械学習 X クラウドが今やばい! メンタルを機械学習でさらに支えちゃうの!
やる気って中々出ないよね <ーそれな
AWSの構成を全てコードで管理しているところ 再現性が高く、Ops・MLの視点で非常に便利。 MLもディープなだけじゃなく、職人的にモデル改善にも励みました。
Shift + Control +J ボタンで入力が止まるの早く直してください!(全角変換キーなので、、、)
こんなことありますよね

やる気スイッチがあればいいのに… →地味に辛い課題。。。
そこで

を作りました。
次のような、ものでこの課題の解決を私たちは目指します。

対話ができて、ひとりの時も、偉人から刺さる一言を貰えます!
対話スペースで、励ましてもらいたいときは、話を聞いてもらってやる気を上げましょう↑↑↑ あなたが元気になったら、やる気スイッチを押しましょう。 そのデータが、さらにあなたのやる気を刺激してくれることになりますよ。 元気を上げたいときは、誰かの背中も押してあげてくださいね。
それだけだと、利用者的にも、開発者的にも物たりさすぎるので、、、
ディープラーニングモデルや、最適化アルゴリズムを適用したり、 その仕組みに対して、フルサーバレス x インフラコード管理という ー UX向上の目論見 ー データ解析 x データ運用 の仕組みを実現して…

もう1つの角度から、テーマにひっかけてみました!
構成は次の通りです。
ディープニューラルネットワークのモデルも含めて、全ての機械学習モデルがクラウド上にサーバレス構成になっていて、運用コスト、学習コスト、データコストなど、多くの面から優れたML運用が可能となっています。
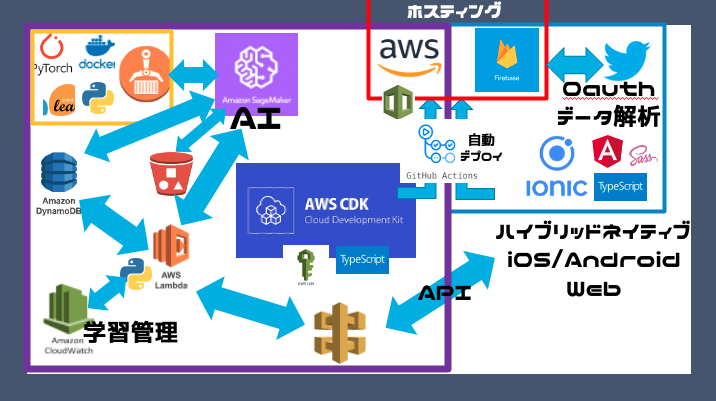
Webだけでなく、ネイティブとしてもデプロイが可能。 拡張性や、情報量を考えて選択。
Authorizationだけでなく、いいね情報を取得でき、ユーザの嗜好情報
通信トラフィックを監視。Lambdaへのルーティングを担う
MLや行列計算のタスクがあるため、Pythonで実装。
機械学習データ、解析データ運用の観点からNoSQLを採用。 めっちゃ勉強になった。 (DynamoDB Streamsで発火して、色々データを扱えるみたいなので興味津々)
boto3経由で手軽にMLのタスクを発行出来る。 手軽にLambda経由などから発行出来るだけでなく、うまく扱えばディープな機械学習モデルも安価に運用できた。 S3やECRとも連携して、巨大データ運用、実行環境管理とも相性がいい
特に、SageMakerで運用しているため、アルゴリズムを考案する段階では、ガッツリローカルでも触った。 しかし、全てクラウド上でサーバレスで実装できている。 BERTを用いたいいねツイートの8つのマルチラベル感情分類を実装し、そのユーザ特性から、行列分解と合わせたブースティングを実現している。
ディープなモデルに対して、思い処理+近似処理で、疎行列補完推定モデルをさらに高めている。 当然サーバレスで運用可能。
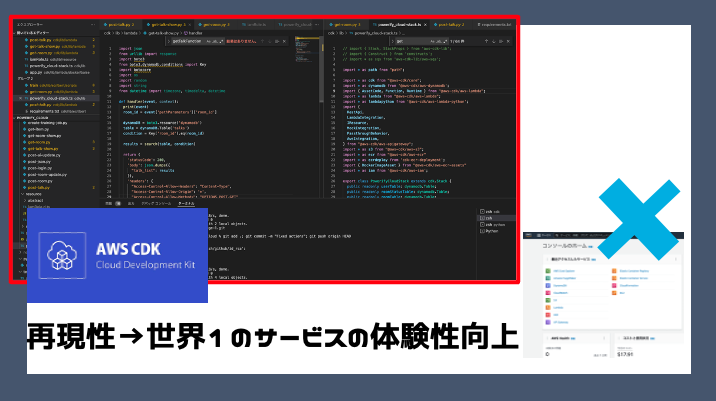
ここまでサーバレス・フルクラウドを強調してきたのはこいつのため。 cdkならコードだけで、AWSのインフラを管理できる。 GUIを扱うより圧倒的に便利で、依存関係のために無茶な構成がしづらい。 再現性もあるため、他のプロダクトへの展開性も高く、非常に重要な技術。
cdkとionicはマージと同時に自動でデプロイされるようにしていた。







NoSQL -> 学習モデルとの相性◎
研究の文脈ー>5ー10%が疎行列の前提 スタートアップならもっと少なくても価値をあたる必要がある
→ブースティングモデル(BERT/行列分解)
cdk -> 特筆すべきは再現性の高さ。誰でも10分程度で今回のインフラ環境を再現でき、運用環境のもとで、サーバレスなデータ運用、MLOpsが可能!!



