









推しアイデア
面接してる時に、優劣を客観的に表示できたら便利。 さらにエンタメ的なUIなら面白い
面接してる時に、優劣を客観的に表示できたら便利。 さらにエンタメ的なUIなら面白い
面接が苦しい!
Electron / React (electron-vite環境) TS
「メン・トライアル」では、面接中の優勢・劣勢をリアルタイムに可視化するために、表情解析・音声解析・音声認識・LLM評価を組み合わせたマルチモーダル解析基盤を構築した。
electron-vite)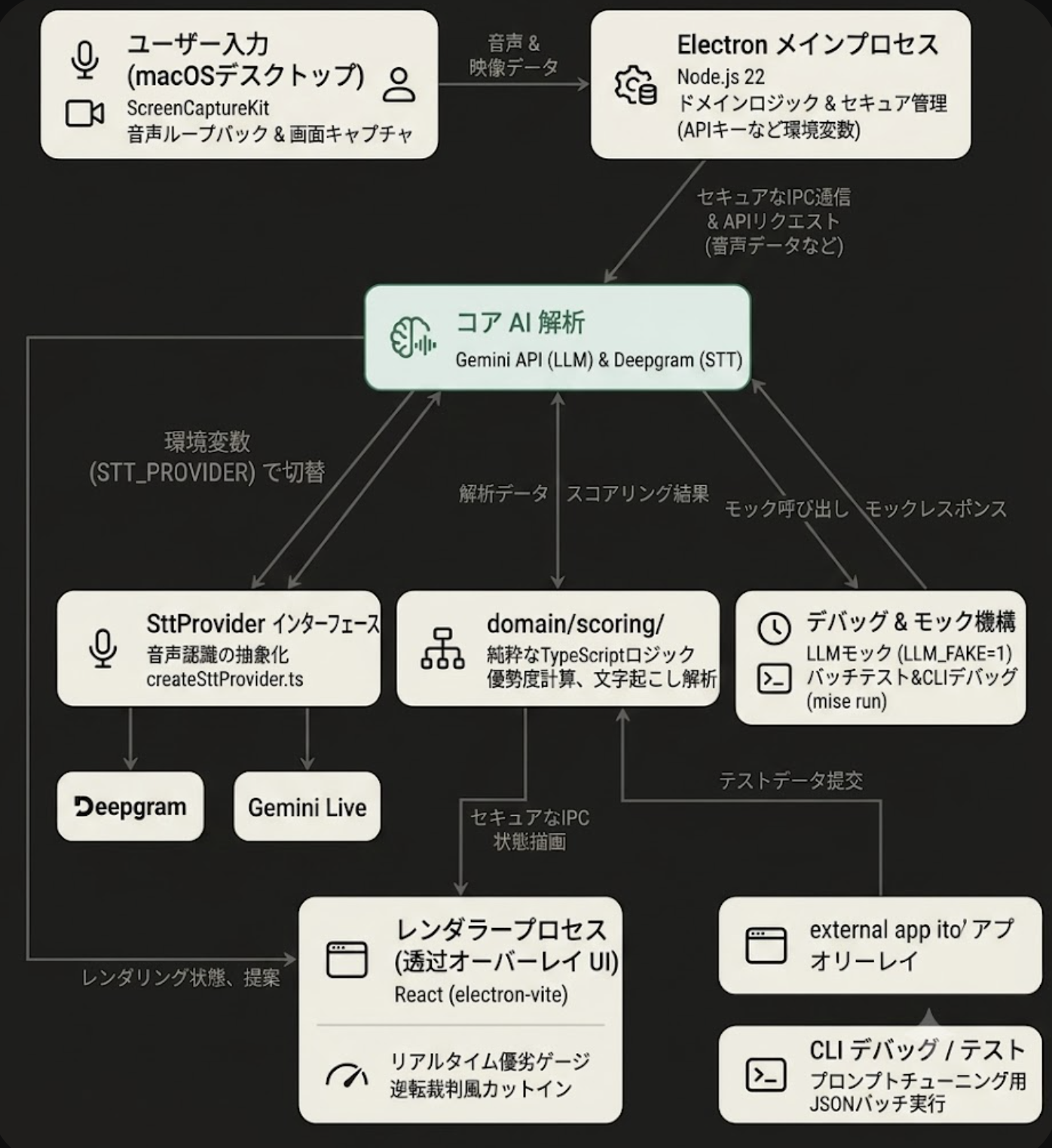
本プロダクトはZoomやGoogle Meet上で利用することを前提としている。単なるWebアプリやブラウザ拡張では、以下の処理が困難である。
そこでElectronを採用し、ネイティブアプリとして動作させることで以下を実現した。
ScreenCaptureKitを利用したmacOS音声ループバック取得本システムでは、以下の状態がリアルタイムで変化する。
そのため状態管理との親和性が高く、ライブラリ資産が豊富なReactを採用した。 また、サーバーサイドレンダリング不要、ルーティング不要の単一画面アプリ(SPA)であることから、Next.jsではなく軽量なVite構成を選択した。
MediaPipe Face Landmarker WASMを利用し、以下を並列解析する。
取得した468点の顔ランドマークから、表情変化、顔領域、視線の安定度を推定する。
顔解析はCPU負荷が非常に高い。毎フレーム解析するとUI描画が阻害されるため、解析処理を非同期化しFPSを制限した。
これにより、オーバーレイ演出の滑らかさを維持している。
顔ランドマークから外接矩形を算出し、顔の位置や大きさに応じて切り抜き領域を自動調整する。さらに余白率を設けることで、ユーザーが前後に移動しても安定した顔ポートレートを生成できる。
Web Audio APIとMeydaを利用し、リアルタイムで以下の特徴量を抽出する。
単純な早口判定ではなく、理想的な発話速度を基準として「どれだけ離れているか」を評価する。そのため、早口・詰まり気味の遅口の双方を焦りとして検知できる。
解析用のAudioNodeと出力ノードを分離し、GainNodeを利用してループバックを抑制。利用者自身にマイク音声が返らない設計としている。
音声認識エンジンへの依存を避けるため、共通インターフェースである SttProvider を定義している。実装はファクトリパターンによって切り替えられ、Deepgram と Gemini Live を環境変数のみで変更可能。将来的なプロバイダ変更時もUI側の修正は不要となる。
認識テキストに対し、「えっと」「あのー」「そのー」などを抽出する。
質問と回答のペアをGeminiへ送信し、回答品質、論理性、説得力を評価する。
APIキーはRenderer側へ公開せず、Main Process内でのみ保持する。RendererはIPC経由で評価依頼を行い、結果のみ受け取る。これによりDevTools経由のキー漏洩を防止している。
Geminiの responseSchema を利用し、以下のJSON形式を強制している。これによりパースエラーを排除し、安定した評価基盤を実現した。
{ "score": 0, "reason": "" }
同一の質問・回答ペアを記録し、重複リクエストを自動的にスキップする。ハッカソン環境でのAPI利用量削減とレスポンス改善に寄与している。
UIとビジネスロジックを明確に分離している。
renderer/ # 描画のみを担当 components/ pages/ domain/ # 優勢度計算や判定ロジックを集約 scoring/ interview/ main/ # 音声認識やLLMなどの基盤処理 stt/ llm/
RendererはAPIキー、STT接続情報、Geminiクライアントへ直接アクセスできない。すべてMain Process経由で実行することで安全性を確保している。
LLM_FAKE=1
を指定することで、実際のGemini APIを利用せず固定値を返す。これにより、API課金削減、オフライン開発、CI実行を可能にした。
mise run judge -- "質問" "回答"
でGemini評価のみを実行可能。Electronを起動せずにプロンプトチューニングや評価精度の改善を行える。
本プロダクト最大の特徴は、「顔」「声」「話し方」「回答内容」という複数の情報源をリアルタイムに統合し、面接状況を可視化するマルチモーダル解析基盤を短期間で実現した点である。
単なるAI利用にとどまらず、
を組み合わせることで、面接支援という新しい体験を実現している。
面接官「webの技術について教えてください」 「Web技術は、主にフロントエンド、バックエンド、そして両者をつなぐ通信の3つで構成されています。 ユーザーが目にする画面や操作を構築するフロントエンドと、サーバー側でデータの処理や保存を行うバックエンド。これらがHTTPなどの通信プロトコルを介してデータをやり取りすることで、Webサービスは成り立っています」
面接官「Webサイトが表示される仕組みを、簡単に説明してください」 変な人「ええっとですね……Webサイトが表示されるのは、要するにGoogleの偉い人たちが裏で高速で画面を切り替えているからなんです。 あ、あと電波の状態が良いと、画面の解像度が勝手に上がって4K画質になります。やっぱりWi-Fiのルーターって、家に2台くらい置いておくとネットが2倍速くなるのでおすすめですよ!」
全体の流れは以下になっています。 いい回答→悪い回答→飛び切りの笑顔
質問と回答を取得するのに苦戦した 前提として、質問とその回答を1セットとしてLLMに渡してます 元々、2.5秒以上の沈黙があると、新たなセッション、つまり次の質問のターンが始まったと認識するようにしていました。 これだと、短文の質問に対して長文で回答するときに、息継ぎすると別のセッションとして認識される、という問題がありました。
そこで、面接官が声を発すると別のセッションが始まった、と認識するようにしました。 しかし、これだと面接官が相槌を打つだけでも別セッションとして認識されます。
そこで、面接官がある程度長時間話さない場合は同一セッションとして認識するようにしました。
また、回答が長文の場合、息継ぎすると、新たな回答として認識される問題があったので、回答が続いてる間は、回答文を連結する処理にしてます。
そして、面接官がある程度まとまった質問をしたら、次のセッションとして認識するように変えました。
LLMに回答の精度を判定させてます。これだとサーバ通信に時間がかかり、リアルタイム処理が実現できなくなります。
そこで、ブラウザ上で完結するものをその間に表示するようにしてます。 具体的には以下の内容です。
また、以下のアニメーションを入れてます。
これらを普段の処理にしておき、質問と回答の1セッションごとにLLMを挟んで補正するといいう構成にしてます
スコアの精度が良いかどうかは、厳密にはデータセットで学習が必要です。ハッカソンでそれはできないので、いい面接と悪い面接を10回程度繰り返して、概ね正しいスコアとなるように重みを調整する作業を繰り返しました。 最後のPRがそれに該当します。



