













推しアイデア
エンジニアで「きせい」といえば一つしかないですよね!
エンジニアで「きせい」といえば一つしかないですよね!
世間体などを気にせず、奇声を発することで報酬を与えてストレス解消出来るツールがあれば良いなと思ってこのツールを開発しました。
はじめて音声認識を取り入れました。はじめてK8sを使いました。はじめてAuthのSaaSを使いました。
私たちがしたかったことは以下のことです。
まず、"良い奇声"の定義を説明します。
音量が大きいかつ日本語化不可能な声
これで納得出来ない人はこちらの定義を!
Voice2Textしたときの文字列長が低いかつdbが大きい場合
これでも納得出来なければこれで!
以下の2条件を十分に満たすものを「良い奇声」と定義する
- 単位時間の発声ワード数k(=6)、音声データ長l(s)、音声データからの抽出ワード数rとしたときX = r / (l * k)が0に近い
- 8bitの音声データを[-1,1]にマッピングし、一定フレーム長の区間でrmsを計算する。総フレーム数をn、単位区間のrms値をaとする時、Y = Σa_i / nについてYが1に近い つまり。Xを0に近い値にし、Yを1に近い値にするような音源データを「良い奇声」と定義する
この定義に従ってPython側で奇声のスコアリングを行っています。 なお、余りに条件が厳しいのでデモ版では係数の調整を行って高得点を出しやすくしています。 プログラムは以下の通りである。アップロードされたwavファイルは添付ファイルとして保存し、そのファイルを読み込んで処理を行っている。 34行目からのプログラムはVoice to textを行なっている。ライブラリの都合上、全くテキスト認識が出来なかったら例外を出すので、その場合はpassしている。
# rmsを計算 def calc_rms(filename): # 情報取得 # 読み込みモードでWAVファイルを開く with wave.open(filename, 'rb') as wr: fr = wr.getframerate() fn = wr.getnframes() # 表示 # print("チャンネル: ", ch) # print("サンプルサイズ: ", width) # print("サンプリングレート: ", fr) # print("フレームレート: ", fn) print("再生時間: ", 1.0 * fn / fr) wave_data, fs = wav_read(filename) rms = librosa.feature.rms(y=wave_data) # 音量の計算 return {"rms": rms, "duration": 1.0 * fn / fr} # rmsの平均を計算 def calc_ave_rms(datas): ave_rms = 0.0 array_len = 0 for data in datas: array_len = array_len + len(data) for rms in data: ave_rms += rms * 2**(0.5) # rmsの調整 ave_rms = ave_rms / (array_len - (0.15 * array_len)) if ave_rms > 1.0: ave_rms = 1.0 return ave_rms # voice to text def voice_recognition(filename): r = sr.Recognizer() with sr.AudioFile(filename) as source: audio = r.record(source) try: text = r.recognize_google(audio, language="ja-JP") except BaseException: text = "" pass print("Text:", text) return text
ユーザーのスコアとPod数の増減は並行処理で実装しています。 panicやdeadlock対策をがっちりやっているわけではないので、場合によっては死ぬ可能性がありますがハッカソン想定の50コネクションでの接続テストはクリアしたので大丈夫だと思います。
func startJob(config *rest.Config) { // WebSocketに良い感じに流すジョブ go func() { for range time.Tick(30 * time.Second) { fmt.Println("Socket Job is called") //母数の計算 score := calcAllScore() if score <= 0.0 { continue } //ユーザーリストの取得 userList, err := redis.SMEMBERS(CONNECTION_PATH) if err != nil { log.Println(err) continue } fmt.Println("Current target num:", len(userList)) podNum, _ := k8s.GetPodsCount(config, "default", POD_NAME) cost := K8S_COST * podNum for _, userId := range userList { // 各ユーザーのスコアを取得 userScore, err := redis.HGetInt(STORE_USER_SCORE, userId) if err != nil { log.Println(err) continue } //ユーザー負担額の計算 userCost := int(float64(cost) * (1.0 - (userScore / score))) connections, _ := redis.DBSize() callback := SocketResponse{ Cost: int64(userCost), Action: "SCORE_DATA", Count: connections, Score: userScore, Pods: podNum, } log.Println("Response: ", callback) response, err := json.Marshal(callback) if err != nil { log.Println(err) continue } m := message{response, userId} h.broadcast <- m } } }() //全ユーザーのスコアが1000nに達したらpodを増やす const threshold = 810 const minNum = 1 // Podの監視ジョブ go func() { for range time.Tick(10 * time.Second) { fmt.Println("Pod Job is called") score := calcAllScore() podNum, _ := k8s.GetPodsCount(config, "default", POD_NAME) log.Println("Score is", score) newNum := int64(score/threshold) + minNum log.Println("Pod num is ", newNum) if newNum < int64(podNum) { continue } _, err := k8s.UpdatePodCount(config, "default", POD_NAME, int(newNum)) if err != nil { log.Println(err) } } }() }
Socket.ioでは当たり前かもしれませんが、インメモリでID毎のSocket通信を実現しています。 idの検証を挟めば、有効なID内で完結するSocket通信を実装出来るのでチャットツールが作れたりします。
router.GET("/ws/:userId", func(c *gin.Context) { userId := c.Param("userId") serveWs(c.Writer, c.Request, userId) })
私たちは今回開発の中でDockerfileのチューニングを行ない、圧倒的な軽量化を実現した。 GoのAPIサーバーは950MBから60MB程度に、Pythonのサーバーも1.48GBから1.09GBに圧縮することが出来た。 Dockerfileのチューニングは以下の効果をもたらす
つまり、良いDockerfileは財布にも優しくメンタルにも優しい存在である。 全人類、最初に良いDockerfileを作るべき!
では、この過程について簡単に説明する。
最初に作った音声処理APIのDockerfileが以下の通りである
FROM python:alpine WORKDIR /api ENV LANG ja_JP.UTF-8 ENV LANGUAGE ja_JP:ja ENV LC_ALL ja_JP.UTF-8 ENV TZ JST-9 RUN apk add --no-cache build-base openssl openblas-dev ffmpeg sox libffi-dev libsndfile-dev COPY requirements.txt . COPY *.pem . COPY ./app /api/app RUN pip install -r requirements.txt CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000","--ssl-keyfile=./key.pem" ,"--ssl-certfile=./cert.pem"]
まあ、見ての通り無駄なパッケージがたくさんある。 そしてビルド時間も非常にかかり、ビルド中に午後のティータイムが出来る程度である。 進捗を生やす度にティータイムをしていては血中カフェイン濃度が急上昇してしまう。 さらに、このDockerfileにlibrosaを入れるとm1環境だとビルドに失敗してしまう。 よってDebianベースのコンテナで再構築することにした。 チューニング後のDockerfileは以下の通りである。
FROM python:3.10-slim-buster as build-stage COPY ./requirements.txt /root/ RUN pip install -r /root/requirements.txt FROM python:3.10-slim-buster WORKDIR /api RUN apt update && apt install libopenblas-dev ffmpeg libffi-dev libsndfile-dev -y && apt autoremove && apt clean && rm -rf /var/lib/apt/lists/* COPY /usr/local/lib/python3.10/site-packages /usr/local/lib/python3.10/site-packages COPY /usr/local/bin/uvicorn /usr/local/bin/uvicorn COPY ./app/main.py /api/app/ CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]
requirements.txtを変更しない限りパッケージは不変なので毎回行なうと時間の無駄である。 そこで、pipインストールを別ステージにしキャッシュ化することに成功した。 初回こそビルドに時間がかかるものの2回目以降は高速にビルドを行なうことが出来る。 あとは本当に必要なライブラリを調べ上げ、それをインストールすることで容量の削減を行なった。 また、別ステージにすることで並列ビルドも可能になる。
以上によりPythonコンテナの高速化の結果を示す。
Goはバイナリを実行する形式なので上手くチューニングすると高い効果を期待出来る。 では、まず最初のDockerfileを示す。
# FROM notchman/opencv:latest as builder-cv # WORKDIR /banana FROM golang:latest as builder WORKDIR /workdir COPY ./src ./ RUN go mod tidy # Set Environment Variable ENV CGO_ENABLED=0 ENV GOOS=linux ENV GOARCH=amd64 # Build RUN go build -o app FROM golang:bullseye WORKDIR / # RUN apt update && apt install -y \ # g++ build-essential libeigen3-dev libtbb-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev \ # libjpeg-dev libpng++-dev libtiff-dev libopenexr-dev libwebp-dev \ # libhdf5-dev libopenblas-dev liblapacke-dev \ # && rm -rf /var/lib/apt/lists/* ENTRYPOINT ["/app"]
何故か色々な物をインストールしている。これは何処かのサンプルを元にしたものだが非常に無駄が多い。そこで諸々を軽量化し以下のようなDockerfileを作った。
FROM golang:latest as builder WORKDIR /workdir COPY ./src ./ COPY ./docker/app/config ./config RUN go mod tidy # Set Environment Variable ENV CGO_ENABLED=0 ENV GOOS=linux ENV GOARCH=amd64 # Build RUN go build -o app FROM gcr.io/distroless/base WORKDIR / COPY /workdir/app /app COPY /workdir/config /root/.kube/config ENTRYPOINT ["/app"]
Googleが提供しているdistrolessを活用することで不必要なパッケージを全て削減することが出来た。これによりイメージサイズを950MBから約60MBに削減し大幅な軽量化を実現した。
小さく素早くビルドが出来るコンテナは開発者体験を向上させる。 是非とも、Dockerfileのチューニングの知見を広めていきより良いDockerライフを過ごしましょう!
ユーザーを一意に識別するためにAzure Static Web Appsに標準で備わっている認証サービス(Authentication)を用いました。Hostingされるアプリケーション内で特定のエンドポイントを叩くだけで認証ができます。例えばTwitterログインをするためには/.auth/login/google?post_login_redirect_uri=/をクライアント自身にリクエストするだけです。
今回は認証プロパイダーとしてGoogle、Twitter、GitHubを用意しました!
インフラ構成図は以下の通りです。
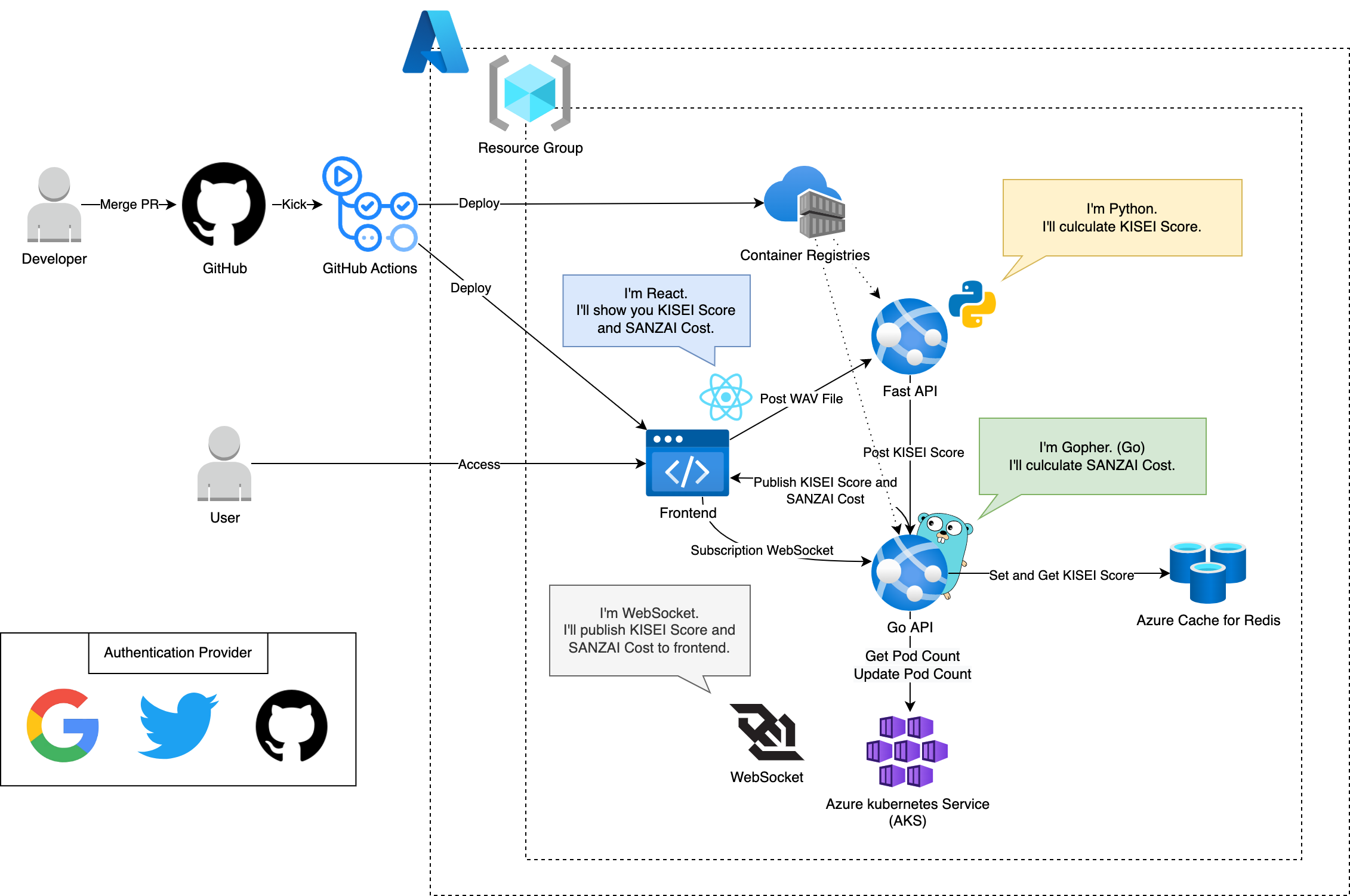
GitHub Actions上でコンテナやフロントアプリをビルドしたりAzureへデプロイを行ったりしています。
GitHub Actions内でコンテナのビルドを行なっています。その際にイメージタグとしてGitHubのコミット番号を用いています。
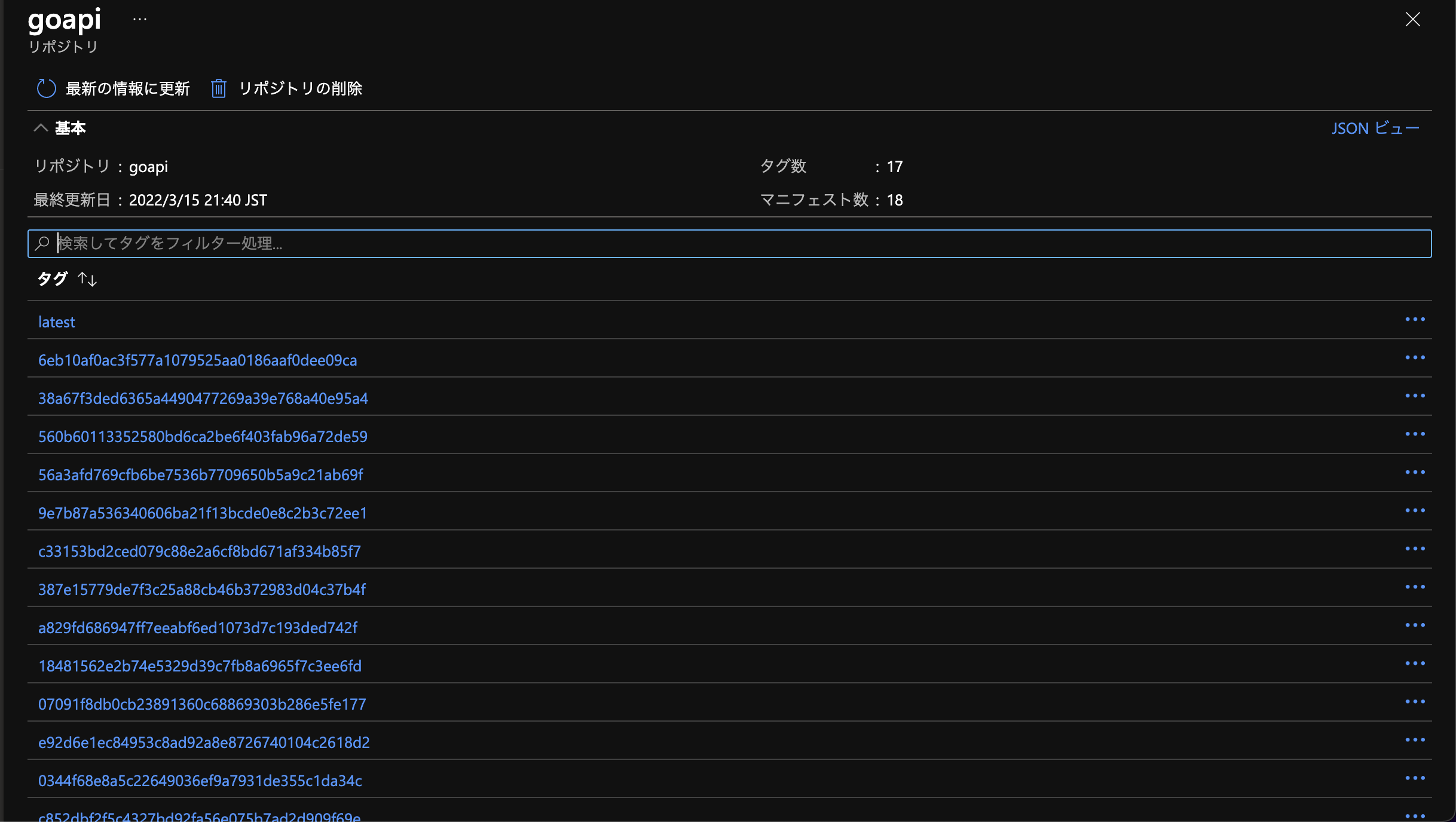 そのため、管理画面から特定のコミットのイメージにロールバックすることを可能にしています。
そのため、管理画面から特定のコミットのイメージにロールバックすることを可能にしています。



