推しアイデア
心の声が漏れる! 心理戦の可視化!
心の声が漏れる! 心理戦の可視化!
心理戦を可視化する かぐや様は告らせたい!
webrtcの無駄使い AIの無駄遣い 心の声の可視化の検証報告
校則 => 学校 => かぐや様は告らせたい
使った技術 Emoch:リポジトリ Speech-Emotion-Analyzer:リポジトリ
 (サンプル.wavからapprehensiveな表情と分析)
(サンプル.wavからapprehensiveな表情と分析)
0.定義
import tempfile from django.views.decorators.csrf import csrf_exempt from django.http import JsonResponse # Importing other libraries import joblib import numpy as np # Audio Imports import pyaudio import wave import librosa # Opening Model MLP = joblib.load("C:/Users/yoko1/workspace/sample_svelte/back/emotion_app/assets/MLP.joblib") # Audio Capture Parameters CHUNKSIZE = 1024 RATE = 44100 p = pyaudio.PyAudio() def start_stream(index=1): """Initializing PyAudio Capture Stream""" global stream stream = p.open(format=pyaudio.paInt16, channels=1, rate=RATE, input=True, frames_per_buffer=CHUNKSIZE, input_device_index=index) def stop_stream(): """Terminate stream.""" stream.stop_stream() stream.close()
1.音響データから特徴量を抽出
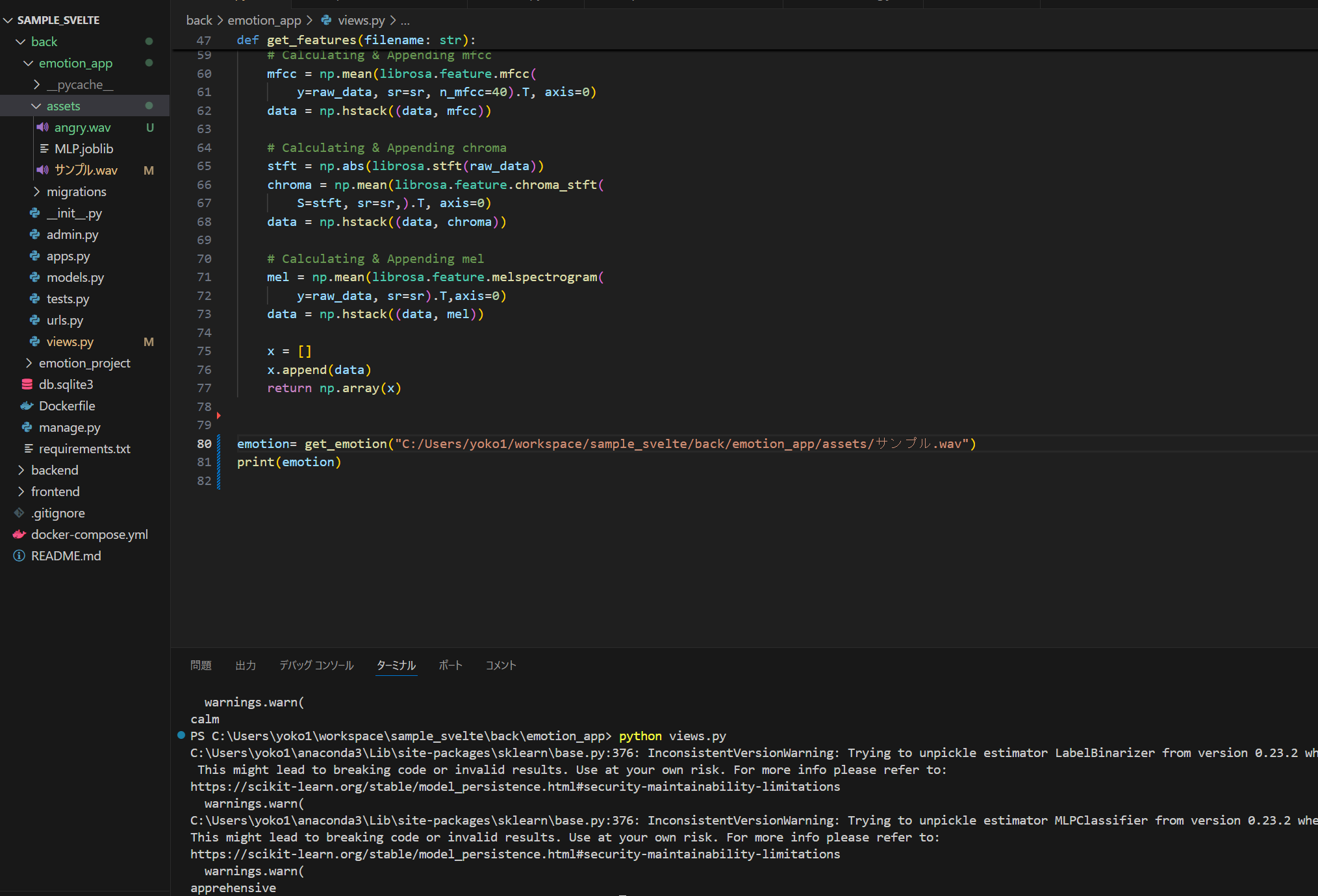
def get_features(filename: str): """ Extract features from audio required for model training. return in required format. """ # Reading the file in and extracting required data raw_data, sr = librosa.load(filename) # Creating an empty numpy array to add data later on data = np.array([]) # Calculating & Appending mfcc mfcc = np.mean(librosa.feature.mfcc( y=raw_data, sr=sr, n_mfcc=40).T, axis=0) data = np.hstack((data, mfcc)) # Calculating & Appending chroma stft = np.abs(librosa.stft(raw_data)) chroma = np.mean(librosa.feature.chroma_stft( S=stft, sr=sr,).T, axis=0) data = np.hstack((data, chroma)) # Calculating & Appending mel mel = np.mean(librosa.feature.melspectrogram( y=raw_data, sr=sr).T,axis=0) data = np.hstack((data, mel)) x = [] x.append(data) return np.array(x)
2.特徴量から感情を分析
def get_emotion(filename:str): """Predict emotion.""" global stream start_stream() frames = [] for _ in range(0, int(RATE / CHUNKSIZE * 1)): data = stream.read(CHUNKSIZE) frames.append(data) with wave.open(filename, 'wb') as file: file.setnchannels(1) file.setsampwidth(p.get_sample_size(pyaudio.paInt16)) file.setframerate(RATE) file.writeframes(b''.join(frames)) features = get_features(filename) emotion=MLP.predict(features)[0] stop_stream() p.terminate() return emotion
上手くいかなかった...(tensorflowのバージョン情報がコンフリクトした)