











推しアイデア
水見式ならぬ球見式 選手とのマッチングサービス
水見式ならぬ球見式 選手とのマッチングサービス
「ファン創出」できそうだから
LangChainによる本格的念能力診断と高性能マッチング機能
LangChainを活用したランダムQ&Aで、あなたの“念タイプ”と相性の良い選手を診断するよ! 診断の最後には、あのネテ〇会長からのありがたいお言葉も!?!?
わずか 10問の質問に答えるだけ! 質問はすべてランダムに出題されるため、毎回ちがった結果を楽しめるよ! 各画面にローディング画面が挟まるから楽しみに待っててね!
1 スタートボタンを押す!

2 答えを選ぶ! 10問あるよ!
3 念能力タイプと相性のいい選手がわかる!


React / JavaScript
FastAPI+LangChain で LLM にリクエストを投げるための API サーバを用意してます。単に LLM の API 叩くだけなら Next.js で API Route 生やせばよかったんですが、LangChain を使うことでPydantic によるデータ型の表現と、それに沿った出力の強制などをやってます。 モデルは Gemini にしてます。安いので。
(今回は触ってませんが、本来は RAG・LCEL・複数LLMのオーケストレーションとかをやるための拡張性がほしかったのでこの構成にしました)
なお、lambda で動かすために後述する Mangum をアダプターとして使用してます。
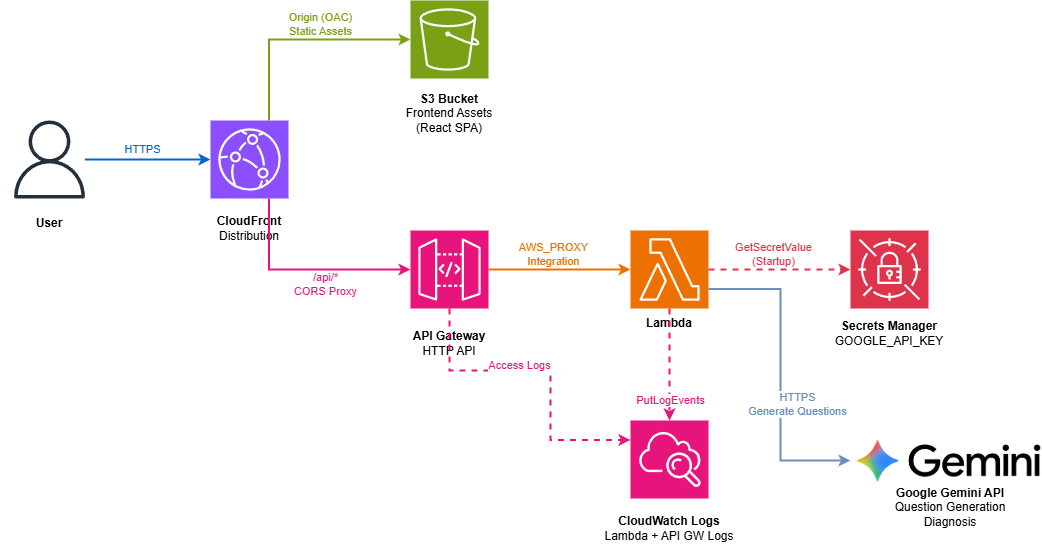 Terraform を使用して AWS へデプロイしてます。全体的にサーバレスな構成にしてみました。
フロントは S3 に置いた静的ファイルを Cloudflont からディストリビューションしてます。API サーバは Lambda を API Gateway を介して公開してます。そのままだと FastAPI が動かないので、アダプターとして Mangum というライブラリを使用しました(参照)。
Terraform を使用して AWS へデプロイしてます。全体的にサーバレスな構成にしてみました。
フロントは S3 に置いた静的ファイルを Cloudflont からディストリビューションしてます。API サーバは Lambda を API Gateway を介して公開してます。そのままだと FastAPI が動かないので、アダプターとして Mangum というライブラリを使用しました(参照)。
データ先 https://www.giravanz.jp/topteam/staff_player/
取得したデータ
{ "id": "01", "name": "Go ITO伊藤 剛", "birth": "1994-03-23", "height": 191, "weight": 86, "from": "埼玉県", "nickname": "ごう", "what_is_soccer": "頑張れる事", "jersey_number_commitment": "ゴールキーパーだけが付けれる番号だから", "pregame_ritual": "掃除", "look_at_my_play": [ "守備範囲の広さ", "足元の技術" ], "best_game": { "title": "2022年の全国社会人サッカー大会", "reason": "チームが1つになることを感じたから" }, "hero": "川口能活", "personality_one_word": "気分屋", "charm_point": "手が綺麗と言われます", "best_in_team_non_soccer": "頭の大きさ", "motto": "今日を頑張る", "message_to_fans": "熱い応援よろしく願いします。", "status": [ { "year": "2012", "club": "FK ZORA", "league": "モンテネグロ・ドルガ", "league_apps": 20, "league_goals": null, "cup_apps": null, "cup_goals": 20 } ], "_source": "https://www.giravanz.jp/topteam/staff_player/01.php" }
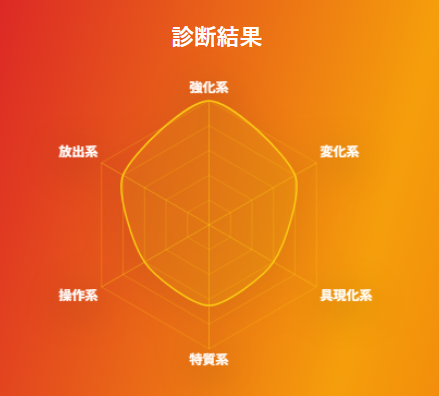
const labels = ["強化系", "変化形", "具現化系", "特質系", "操作系", "放出系"]; const values = [100, 80, 60, 65, 60, 80];
プロンプト回りの工夫をちょっとばかし。 複雑なことをさせるときに適当なプロンプトだと出力が安定しないのでいろいろやったよという話です。
LangChain を使用した最たる理由です。
with_structured_output() を使用することで、 Pydantic で表現した型で出力をチェックすることができます。
これによりデータを構造体として扱うことができたり、適合する出力でなければ再度出力させる、みたいなことがサクッとできました。
↓質問の型(Pydantic)
```python # api/models/question.py from pydantic import BaseModel, Field class Question(BaseModel): """サッカー診断用の質問""" question_text: str = Field(description="サッカーに関する質問文") choices: List[str] = Field( description="4つの選択肢", min_length=4, max_length=4 ) class QuestionSet(BaseModel): """サッカー診断用の質問セット(10個の質問)""" questions: List[Question] = Field( description="10個の質問", min_length=10, max_length=10 )
↓使用例
# api/services/question_generator.py llm = ChatGoogleGenerativeAI( model="gemini-2.5-flash", temperature=0.9, # 創造的な質問生成 google_api_key=api_key, ) # 構造化出力を使用 structured_llm = llm.with_structured_output(QuestionSet) # プロンプトとチェーン prompt = get_question_generation_prompt(seed=seed) chain = prompt | structured_llm # 実行 question_set: QuestionSet = chain.invoke({})
今回のアプリでは質問内容を LLM に投げて診断させてるんですが、そのまま結果を投げて「このユーザーの適性どんなん?」って聞いても出力に根拠を持たせるのが難しいです。 なので、思考のステップをこちらである程度書き出し、その手順によって施行させることで出力を安定させるようにしてみました。
↓診断まわりのプロンプト例
## 分析手順 以下の手順で段階的に分析してください: ### 1. 各質問の分析 質問1から質問10まで、それぞれについて: - この質問が測定している性格特性は何か? - ユーザーが選んだ選択肢はどの念能力系統を示唆するか? - この回答から読み取れる性格傾向は? ### 2. パターンの抽出 - 全体的な傾向(どの系統の選択肢を多く選んでいるか) - 特徴的な回答パターン - 一貫性の確認 ### 3. 判定結果の出力 - **primary**: 最も適性のある系統を1つ選択 - **specialist_score**: 特質系の適性を0-100で評価 - 0-30: 特質系の要素はほとんどない - 31-50: やや特質系の要素がある - 51-70: 特質系の要素が明確にある - 71-90: 強い特質系の適性 - 91-100: 圧倒的な特質系(primaryが特質系の場合のみ)
FastAPI を lambda で動かすアプローチは今回初めて行ったんですが、料金が安くなる代わりに 30秒のタイムアウト制限 がついてしまいました。 普通は問題にならないんですが、これが AI 生成とすこぶる相性が悪いです。実際、質問生成が 3割くらいの確率で失敗してます。
これを回避するには SQS を挟むか ECS とかに移行する必要があるっぽいですが、時間がないので断念。制約は事前に把握しようね。
Gemini 付属の nano-banana を使った2ショット機能を実装しようとしてたんですが、FastAPI のタイムアウト問題であえなく断念したので供養しておきます。




