









推しアイデア
クローラーをメモリ単位で効率化して、激エモイケイケスーパーパーリナイ
クローラーをメモリ単位で効率化して、激エモイケイケスーパーパーリナイ
面白そうだったから
オーバーエンジニアリング’最高 Pythonだけどめっちゃ型堅牢、FastAPIからTSのクライアントへの型共有を実装
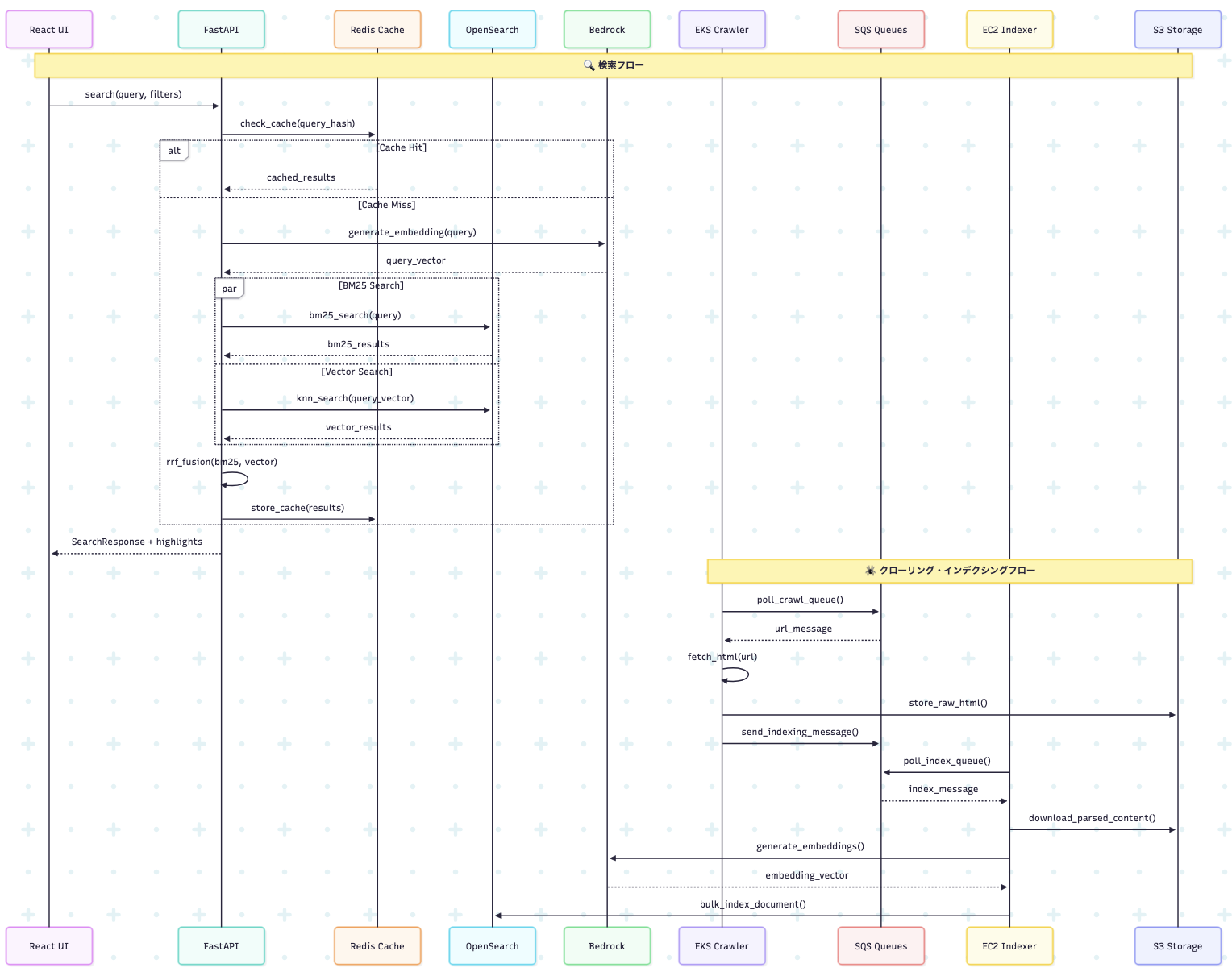
このプロジェクトは、Web クローリング、ベクトル埋め込み生成、ハイブリッド検索を組み合わせた次世代検索プラットフォームです。Amazon OpenSearch と Bedrock 埋め込みを活用し、BM25 とベクトル検索の RRF(Reciprocal Rank Fusion)統合により、従来のキーワード検索では実現できない高精度なセマンティック検索体験を提供します。
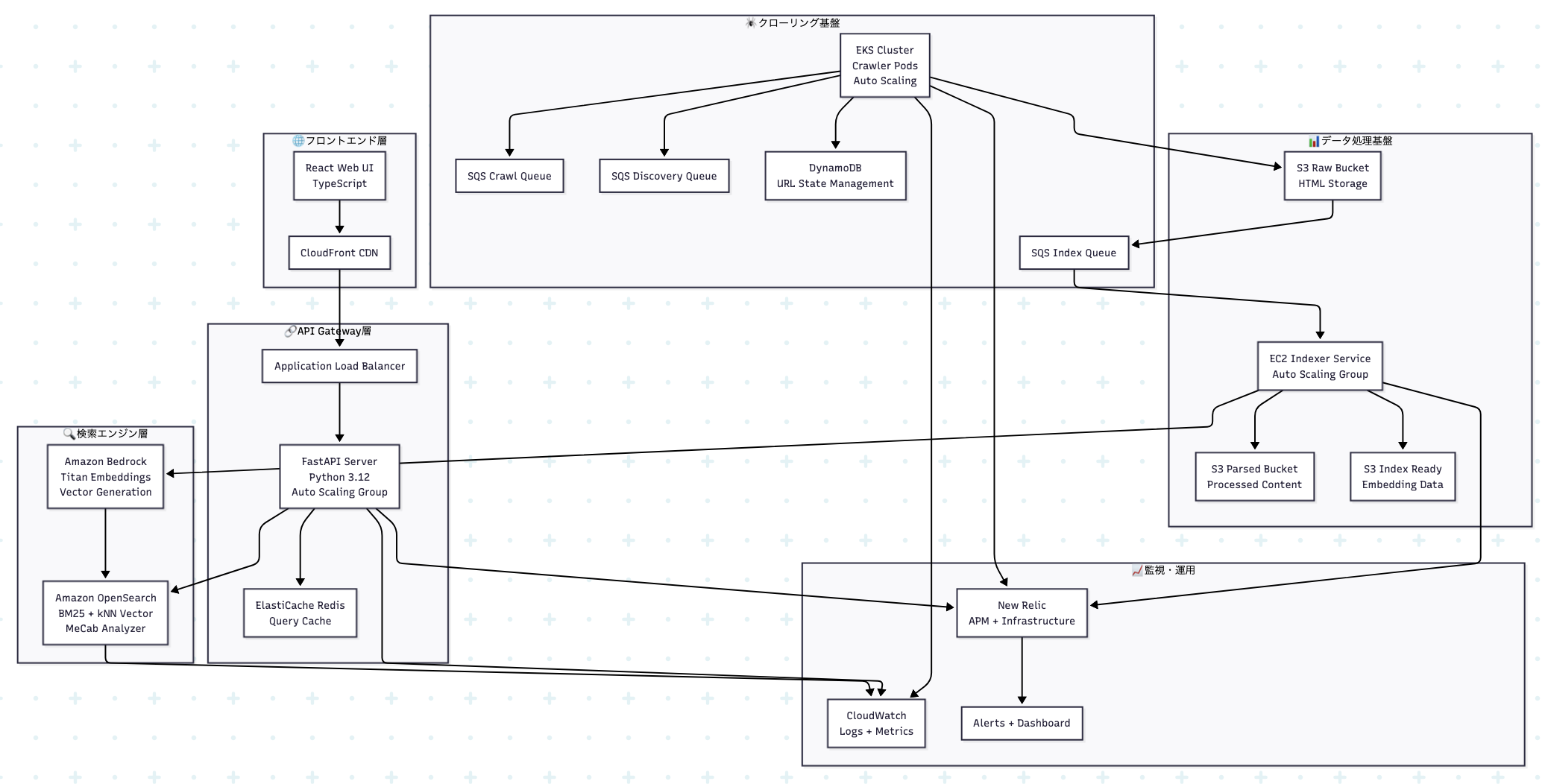
app/crawler/)実行環境: Amazon EKS (Kubernetes)
技術詳細:
# 主要コンポーネント - CrawlerWorker: メインワーカー実装 - RobotsTxtParser: robots.txt解析 - SitemapParser: sitemap.xml処理 - RateLimiter: ドメイン別QPS制御 - StateManager: 分散状態管理 - ContentProcessor: HTML解析・言語判定
主要機能:
設定例:
# crawler/config/prod.yaml max_concurrent_requests: 10 request_timeout: 30 default_qps_per_domain: 1 max_retries: 3 acquisition_ttl_seconds: 3600
app/indexer/)実行環境: Amazon EC2 Auto Scaling Group
技術詳細:
# 主要コンポーネント - IndexerService: メインサービス - BedrockClient: 埋め込み生成クライアント - OpenSearchClient: 検索エンジン統合 - DocumentProcessor: ドキュメント前処理 - TextChunker: テキスト分割処理 - DLQHandler: デッドレターキュー処理
主要機能:
処理フロー:
async def process_message(self, message): # 1. S3から解析済みコンテンツ取得 content = await self.download_s3_content(message.s3_key) # 2. ドキュメント前処理 document = await self.processor.process(content) # 3. 埋め込み生成 (Bedrock) if self.bedrock_enabled: embeddings = await self.bedrock.generate_embeddings(document.text) document.embedding = embeddings # 4. OpenSearch投入 await self.opensearch.bulk_index([document])
app/backend/)実行環境: Amazon EC2 Auto Scaling Group + ALB
API エンドポイント:
# 主要エンドポイント GET /rpc/search?q={query}&page={page}&size={size} GET /rpc/suggest?q={query}&size={size} GET /health
レスポンス形式:
interface SearchResponse { total: number; hits: SearchHit[]; page: number; size: number; } interface SearchHit { id: string; title: string | null; url: string; site: string; lang: "ja" | "en"; score: number; snippet?: string; highlights: Highlight[]; }
app/frontend/)技術詳細:
主要コンポーネント:
// 主要React コンポーネント - App.tsx: メインアプリケーション - SearchBox: 検索入力フォーム - SearchResults: 結果一覧表示 - ResultItem: 個別結果アイテム - Pagination: ページネーション
型安全性:
// 自動生成された型定義 import { SearchResponse, SearchHit } from './types/search'; import { RPCClientImpl } from './rpc-client'; const rpc = new RPCClientImpl(baseURL); const results: SearchResponse = await rpc.search(query, page, size);
実装済み機能:
app/schema/)Pydantic データモデル:
# 検索関連モデル class SearchQuery(BaseModel): q: str page: int = Field(1, ge=1) size: int = Field(10, ge=1, le=100) lang: Optional[Lang] = None site: Optional[str] = None sort: Optional[Literal["_score", "published_at", "popularity_score"]] = None class SearchHit(BaseModel): id: str title: Optional[str] = None url: str site: str lang: Lang score: float snippet: Optional[str] = None highlights: List[Highlight] = Field(default_factory=list) # ドキュメントモデル class Document(BaseModel): id: str url: HttpUrl site: str lang: Lang title: Optional[str] = None body: Optional[str] = None published_at: Optional[datetime] = None crawled_at: Optional[datetime] = None content_hash: Optional[str] = None popularity_score: Optional[float] = Field(default=None, ge=0) embedding: Optional[EmbeddingVector] = None
infra/)Terraform構成:
# 主要リソース module "network" { # VPC・サブネット・セキュリティグループ source = "./modules/network" } module "opensearch" { # Amazon OpenSearch cluster source = "./modules/opensearch" } module "storage" { # S3 buckets (raw/parsed/index-ready) source = "./modules/storage" } module "queue" { # SQS queues (crawl/discovery/index) source = "./modules/queue" } module "eks" { # EKS cluster for crawler workloads source = "./modules/eks" }
リソース概要:
https://github.com/yomi4486/progate-aed-hackathon.git cd progate-aed-hackathon
# uv (推奨) または pip を使用 curl -LsSf https://astral.sh/uv/install.sh | sh uv sync --dev
make run # docker-compose up LocalStack
make tf-init # terraform init make tf-apply # terraform apply (LocalStack向け)
cd app/frontend pnpm install pnpm dev # http://localhost:5173
cd app/backend uvicorn server:app --reload --port 8000 # http://localhost:8000
# PydanticモデルからTypeScript型定義を生成 make pydantic2ts # FastAPI RouteからRPCクライアント生成 make routes2rpcc
# Python テスト uv run pytest # フロントエンド テスト cd app/frontend && pnpm test
# Python uv run ruff check --fix uv run ruff format # TypeScript cd app/frontend && pnpm lint --fix
基盤インフラストラクチャ
Webクローラー
インデクサーサービス
共通ライブラリ・スキーマ
検索API
React Webアプリ
# k8s/crawler-deployment.yaml (抜粋) apiVersion: apps/v1 kind: Deployment metadata: name: crawler-worker spec: replicas: 1 template: spec: serviceAccountName: crawler-service-account containers: - name: crawler image: 978888632917.dkr.ecr.us-east-1.amazonaws.com/aedhack-crawler:v5 command: ["./.venv/bin/python", "-m", "app.crawler.worker"] args: ["run", "--environment", "prod"] resources: requests: memory: "128Mi" cpu: "50m" limits: memory: "256Mi" cpu: "200m"
# k8s/crawler-scaledobject.yaml (抜粋) apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: crawler-scaler spec: scaleTargetRef: name: crawler-worker minReplicaCount: 1 maxReplicaCount: 10 triggers: - type: aws-sqs-queue metadata: queueURL: https://sqs.us-east-1.amazonaws.com/.../crawl-queue queueLength: '5' awsRegion: us-east-1
# Dockerfile (抜粋) FROM python:3.12-slim AS base # uv installation for fast dependency management RUN curl -LsSf https://astral.sh/uv/install.sh | sh ENV PATH="/root/.local/bin:$PATH" # Virtual environment creation and dependency installation RUN uv sync --frozen --no-dev # Health check with custom command HEALTHCHECK \ CMD python -m app.crawler.worker health || exit 1 # Production command CMD ["./.venv/bin/python", "-m", "app.crawler.worker", "run"]
# .github/workflows/terraform-lint.yml (抜粋) name: Terraform Lint on: pull_request: paths: ['**/*.tf', '**/*.tfvars'] jobs: tflint: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: hashicorp/setup-terraform@v3 - name: Run tflint run: | tflint --init tflint --format=compact
tools/pydantic2ts/)機能: PydanticモデルからTypeScript型定義を自動生成
# tools/pydantic2ts/__main__.py の機能 def process_file(file_path: str, output_dir: str): """ Pydanticモデルを解析してTypeScript型定義を生成 - Union型 → TypeScript Union - Optional[T] → T | undefined - List[T] → Array<T> - Literal → 型リテラル - BaseModel → interface """
使用方法:
make pydantic2ts # または uv run pydantic2ts ./app/schema ./app/frontend/src/types
生成例:
# app/schema/search.py class SearchHit(BaseModel): id: str title: Optional[str] = None score: float lang: Lang
↓ 自動生成 ↓
// app/frontend/src/types/search.ts export interface SearchHit { id: string; title?: string; score: number; lang: Lang; }
tools/routes2rpcc/)機能: FastAPI ルートからTypeScriptクライアントコードを自動生成
# Makefile 主要コマンド run: # LocalStack起動 tf-init: # Terraform初期化 tf-apply: # インフラ構築 tf-destroy: # インフラ削除 pydantic2ts: # 型定義生成 routes2rpcc: # RPCクライアント生成



