













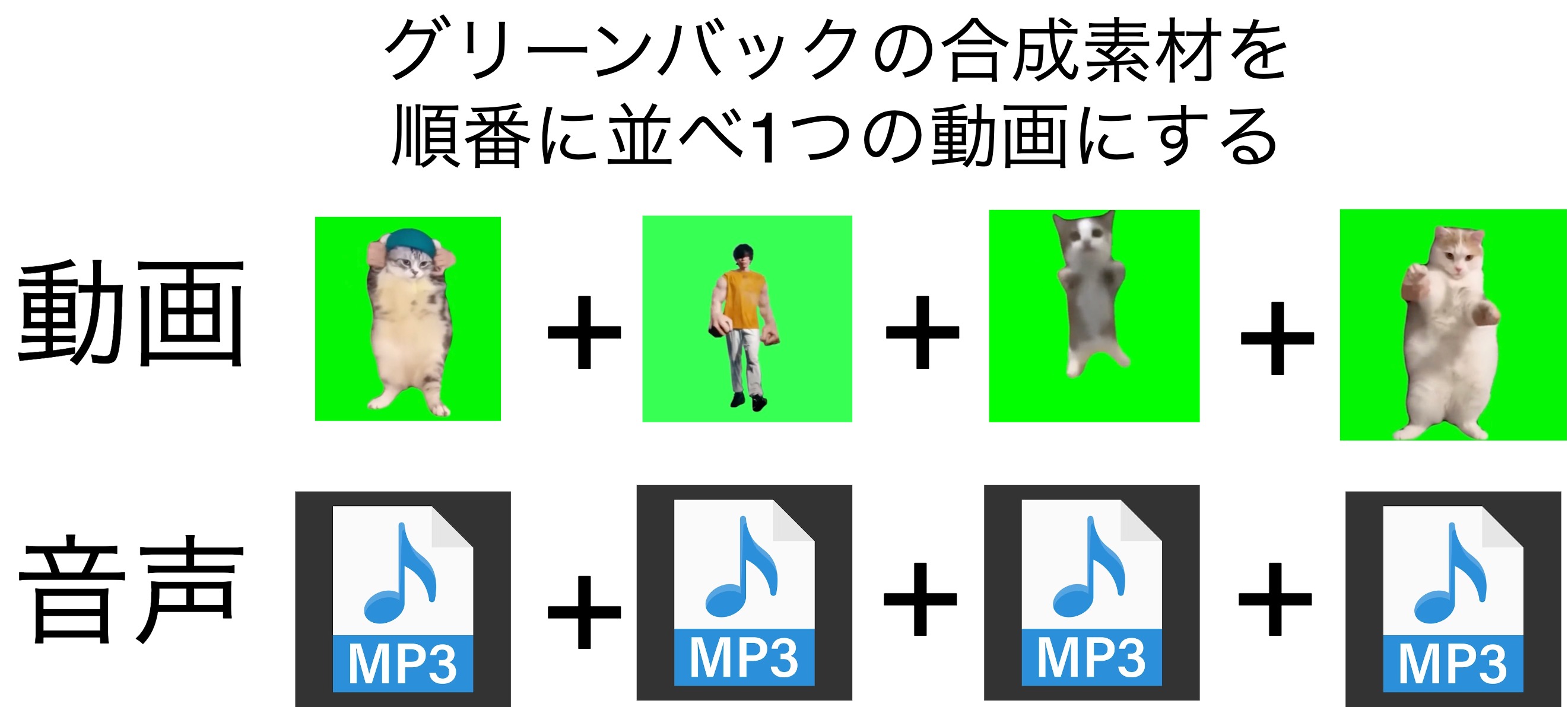
推しアイデア
人間のダンスから猫ミームを生成!
人間のダンスから猫ミームを生成!
猫ミームってなんか癒されませんか?
wasm,webGL,cloudFlare, 自作猫ミーム判定AIなどモリモリ技術をできるだけフロントエンドで動かしてます!
とにかく、CloudFlare + Remixのフロントエンドでできる限りの処理を行う。→ ハイスペックPCでしか動かないかもしれないけどブラウザで全部動いてるってめっちゃ面白くないですか?
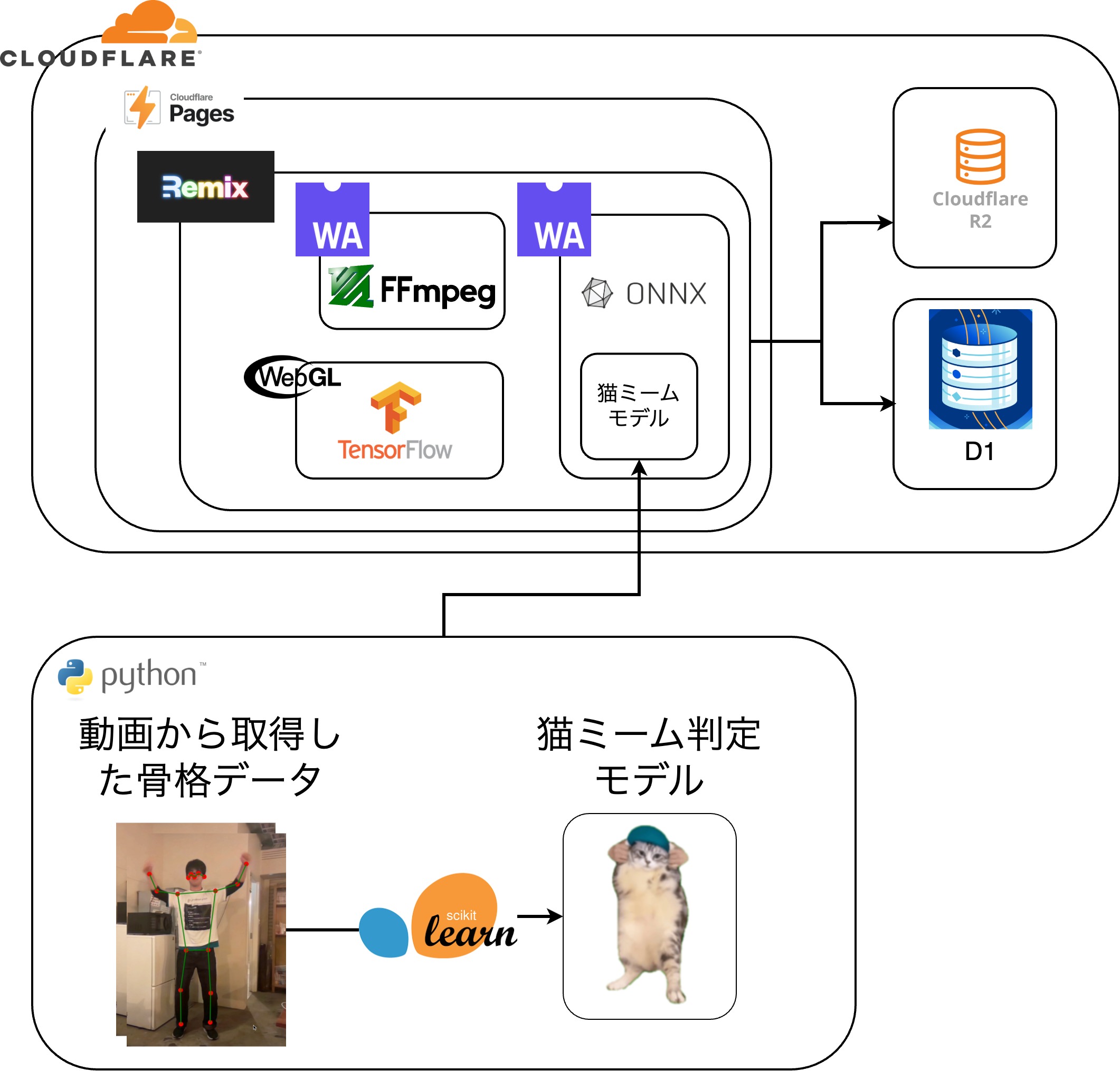
実際には当初予定していた、フロントエンドに全部詰め込む!のコンセプトは力不足で一部しか達成できませんでした。 逆境を跳ね返すべき、より技術の無駄遣いをします!
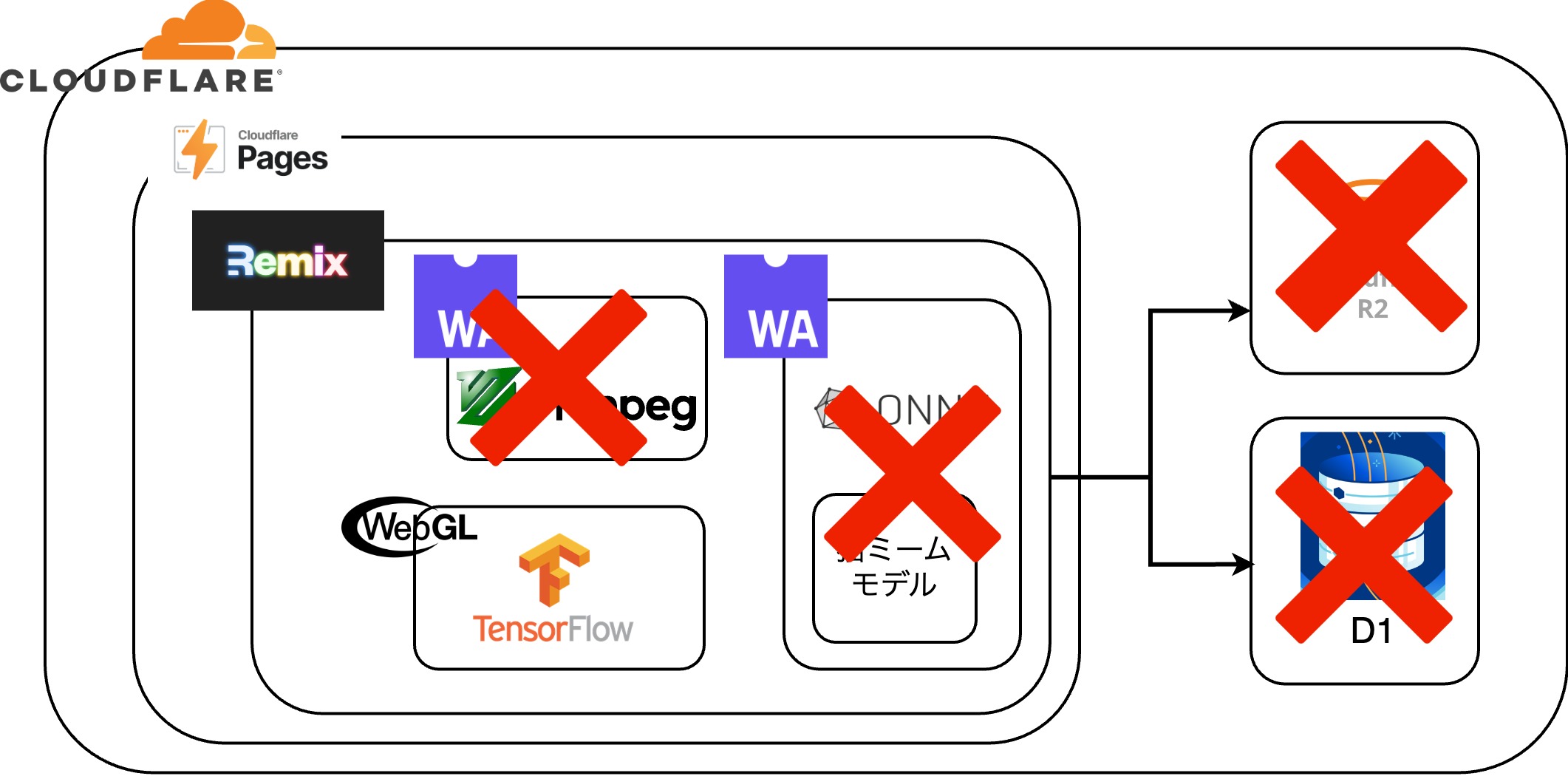
ほぼほぼ結局フロントエンドでやってます!web系技術の無駄使い!これが動かないPCで開発してるって???それは買い替え時だね!
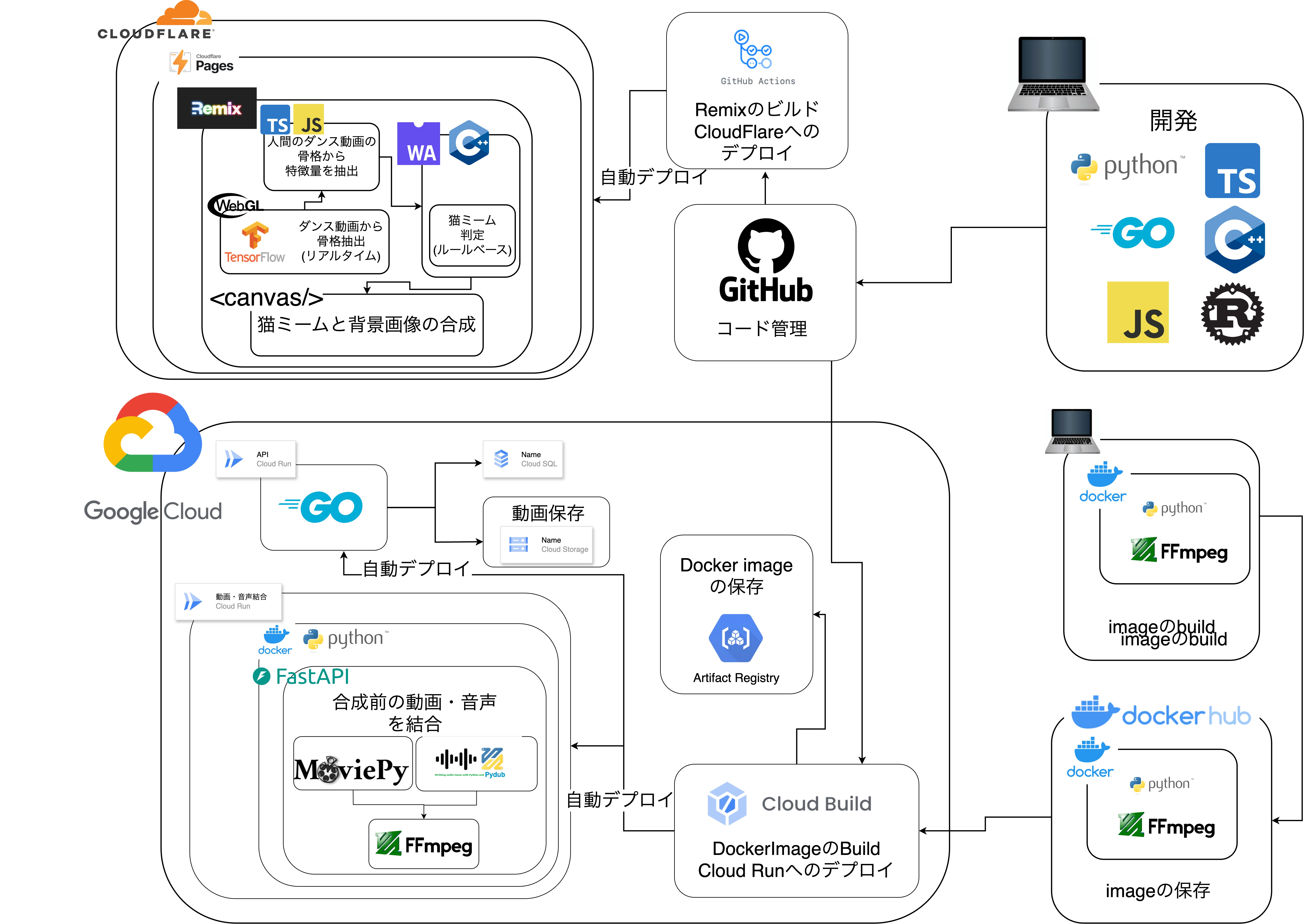
基本的にはffmpegを使っているが、MoviePyとPydubというffmpegをライブラリをWrapしたライブラリを使用している
ffpmegを使えば背景画像の合成もできますが、そこはフロントエンドでやることで技術の無駄遣いしてます😭😭😭
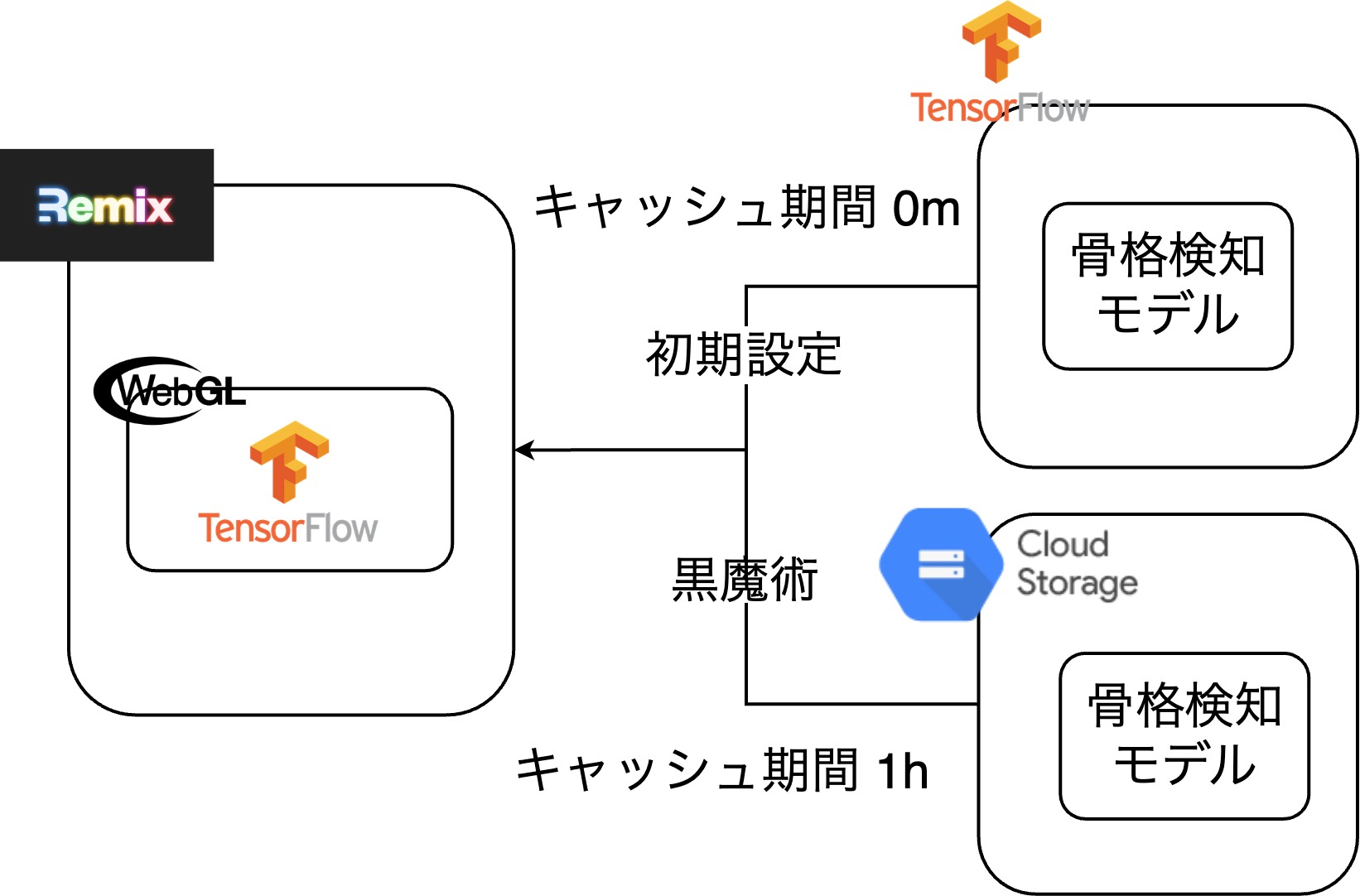
骨格検出では、TensorFlowでopenpose-multiと呼ばれるモデルを用いている。このモデルはデフォルトの設定では、TensorFlow側が準備しているサーバからモデルをロードするのだが、headerのmax-ageが0に設定されており、ブラウザ側でのキャッシュが効かないため、毎回20秒ほどロード時間があった。
そこで、モデルのロード先を独自にホスティングしたサーバに変更し、max-ageを長く設定することでブラウザキャッシュが効き初回ロード時以外はキャッシュがあるためロードがほぼ0msとなった
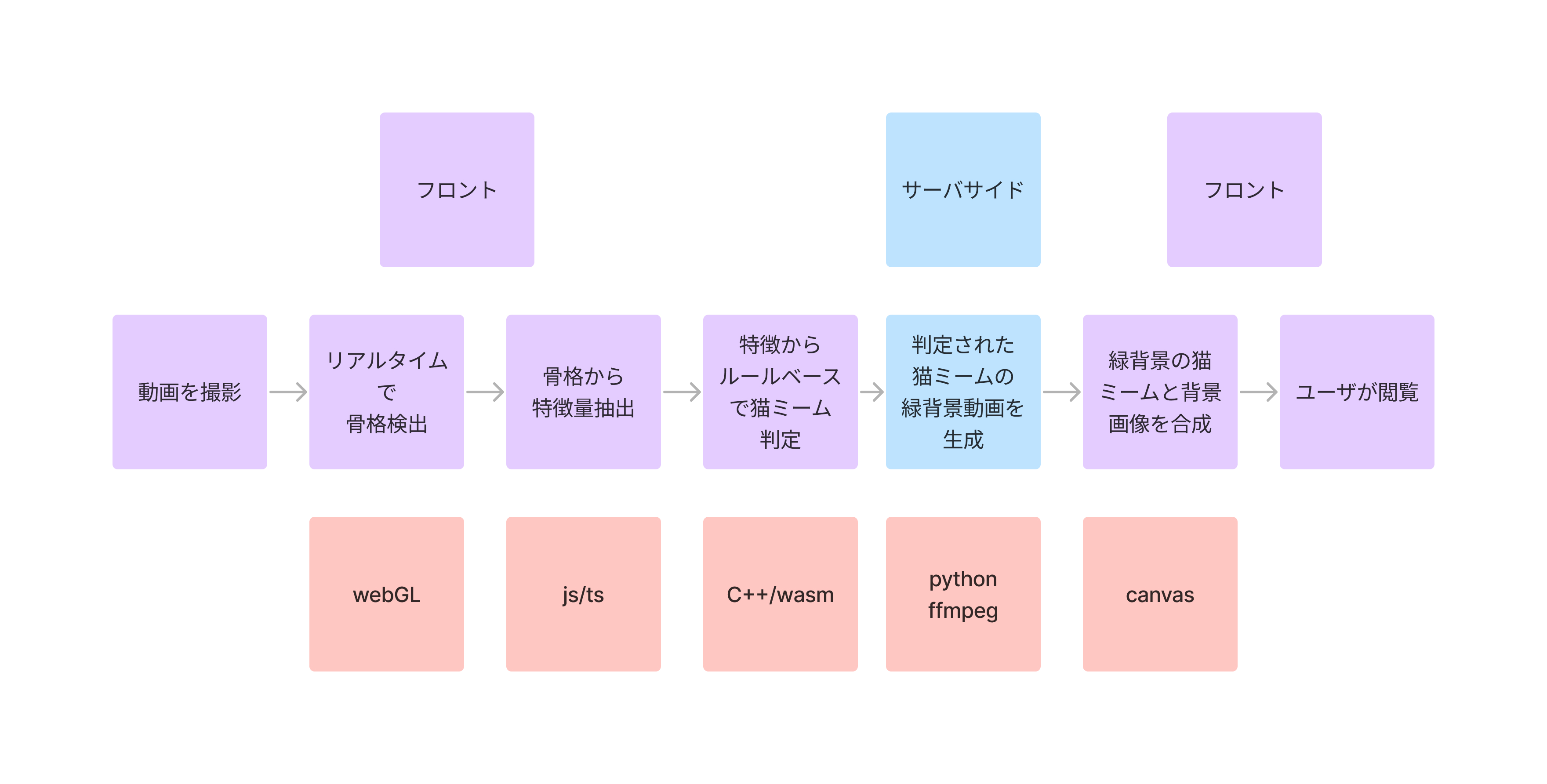
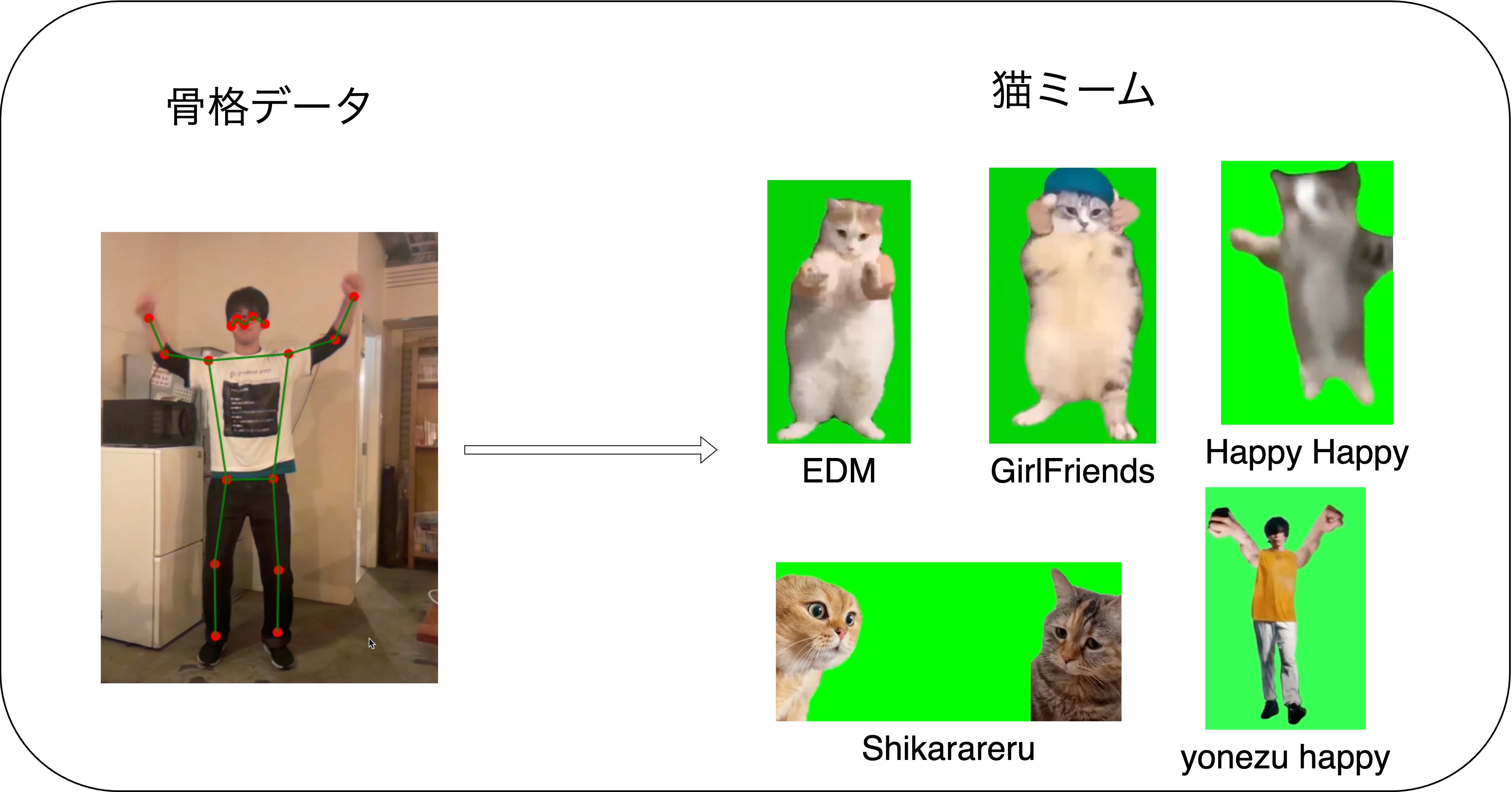
猫ミームは動画から取得できる骨格データを元にルールベースで判定しています。骨格検出にはwebGL、特徴抽出にJS,TS、ルールベースの判定にwasm化したC++を利用しています
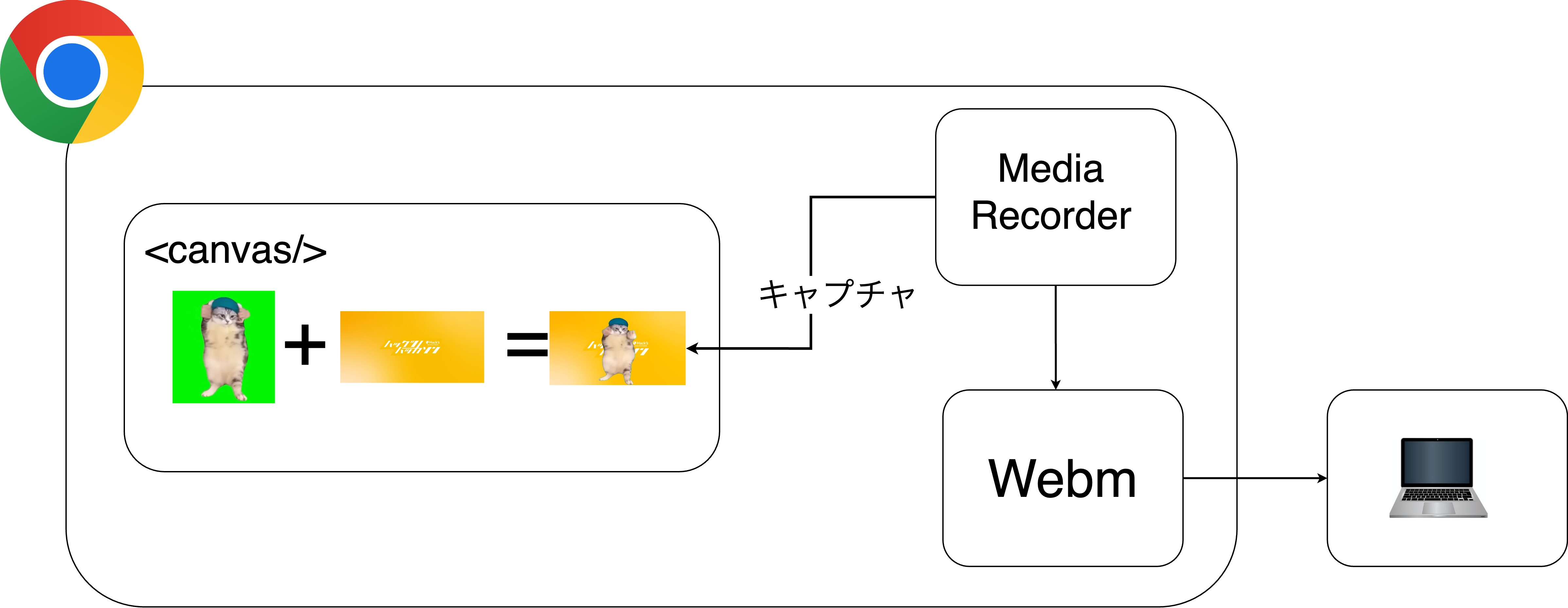
クロマキー合成にはffmpegを代表とするかなり重めのツールやライブラリが有名であるが、どんなにハイスペックなPCを使ったとしてもクロマキー合成に数秒から数十秒かかってしまう。 そこで、ブラウザ標準のcanvasでクロマキー合成をすることで、軽量で待ち時間0でクロマキー合成を行えるようにした。 また。canvasでの描画はブラウザ標準のMediaRecorderで動画として保存されており、ユーザはcanvasで作成された猫ミームをダウンロードすることができる。
動画の結合がcanvasでできなかっため、クロマキー合成前の動画の結合をPython製サーバで行っている。また、問題2のために、結合せした音声ファイルも生成している。
音声がなくなってしまう問題については、上述した結合した音声データをMediaRecorderが収録する音声として設定することで、canvasで消えてしう音声データを再度結合している
今回のアプリケーションではCSRを利用しています。気づいた方もいるかもしれませんが、このアプリは最初のロード以外はブラウザのローディングアイコンが微動だにしません。 CSRを使っているため、通常のアプリケーションよりも少ない通信量で、かつシームレスなアプリ体験が出来ます。今回の猫ミームのようなインタラクション性の強いアプリケーションではロード時間がどうしても気になったり、アプリが重い!といってユーザがいらいらすることもあるでしょう。しかし、CSRではその課題を解決しています。 皆さんもリンクをポチポチ押して、このアプリケーションのシームレスな体験の良さをぜひ味わってみてください。
骨格検知はTensorflowのmovenetというモデルを利用しました。 https://github.com/tensorflow/tfjs-models/tree/master/pose-detection/src/movenet このTensofflow jsというものがあり、今回のモデルはwasm版とwebGL版がありました。 GPUを利用しながら処理してくれるwebGL版の方が実行速度が早かったので、こちらを採用しました。 このライブラリは骨格検知を行い、そのキーポイントの座標とキーポイントの名称と、推論の信頼度を取得できます。 このフレームワークの最も重いモデルを利用し、複数人検知ができるようにしています。そのため、アプリケーションの実行にはある程度のPCスペックが必要です。可愛い猫ミームが見られるので、そこはご了承ください。
Cloud Runでは常時インスタンス数1以上にすれば、大量のリクエストが来ない限りコールドスタート問題が起こることはないが、大学生はお金がないので最小インスタンス数を0に設定したい!なのでコールドスタートを特に高速化する必要があります。
下記のようにデプロイするDockerコンテナ内で、baseimageに含まれないffmpegを使おうとすると、コンテナ起動時にffmpegのinstallが走ってしまい、かなり大きいffmpegのダウンロードに時間がかかってしまう 公式で、ffmpeg+pythonが含まれたimageが公開されておらずffmpegのinstallは基本的には必須事項である
# ビルドステージ FROM python:3.10-slim AS build-stage WORKDIR /app # 必要なパッケージのインストール COPY requirements.txt . RUN pip install -r requirements.txt # アプリケーションのソースコードをコピー COPY . . # 本番環境用のDockerイメージ FROM python:3.10-slim AS production-stage WORKDIR /app # FFmpegのインストール RUN apt-get update && \ apt-get install -y ffmpeg && \ rm -rf /var/lib/apt/lists/* # ビルドステージから必要なファイルをコピー COPY --from=build-stage /app /app COPY --from=build-stage /usr/local /usr/local # ポートの公開 EXPOSE 8080 # コンテナが起動するたびに実行されるコマンド CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8080"]
# ビルドステージ FROM --platform=linux/amd64 python:3.10-slim AS build-stage WORKDIR /app # FFmpegのインストール RUN apt-get update && \ apt-get install -y ffmpeg && \ rm -rf /var/lib/apt/lists/*
# ビルドステージ FROM python:3.10-slim AS build-stage WORKDIR /app # 必要なパッケージのインストール COPY requirements.txt . RUN pip install -r requirements.txt # アプリケーションのソースコードをコピー COPY . . # 本番環境用のDockerイメージ FROM 独自イメージ:1.0 AS production-stage WORKDIR /app # ビルドステージから必要なファイルをコピー COPY --from=build-stage /app /app COPY --from=build-stage /usr/local /usr/local # ポートの公開 EXPOSE 8080 # コンテナが起動するたびに実行されるコマンド CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8080"]
Go,Python,Remix,C++,Rustなどなど今回使った技術やコードは全て https://github.com/punaten/Punaten レポジトリに入っています。 ハッカソンでは、バックエンド、フロントエンド、インフラなど役割分担を分けがちですが、全員がバックエンド、フロントエンド、インフラなどをレポジトリの移動なく、スムーズに開発できるように全てを1つのレポジトリ(モノレポ的)に管理しています
今回は、レポジトリをpunatenというOrganization保有にしています。こうすることで、チームメンバーなら、自由にPaaSやSaaSとレポジトリを連記したり、レポジトリにSeacretを登録したりすることができます。個人保有のレポジトリだとレポジトリのオーナーだけしかこのような設定ができないため、開発効率の低下につながると考え、Organization保有にしました。
得意分野 : バックエンド、インフラ
26卒

得意分野 : フロントエンド
25卒

得意分野 : フロントエンド
24卒




