











推しアイデア
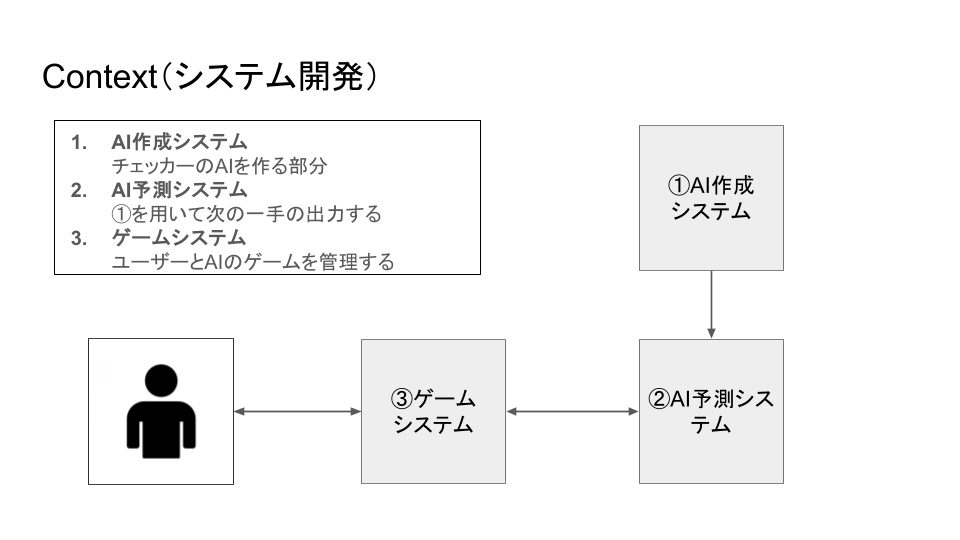
・Docker環境での機械学習モデル開発 ・C4モデルを用いた要件定義 ・Event bridgeによる自動モデル更新機能
―
・Docker環境での機械学習モデル開発 ・C4モデルを用いた要件定義 ・Event bridgeによる自動モデル更新機能
・将棋のようなボードゲームを作りたかった ・ゼミの教授の研究が強化学習に関するものだった
・Sagemaker ・pygame ・Alpha zero
https://ja.wikipedia.org/wiki/%E3%83%81%E3%82%A7%E3%83%83%E3%82%AB%E3%83%BC
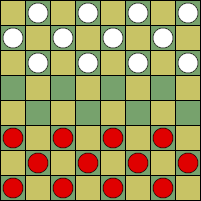 ※今回は6×6マスのものを使用
※今回は6×6マスのものを使用
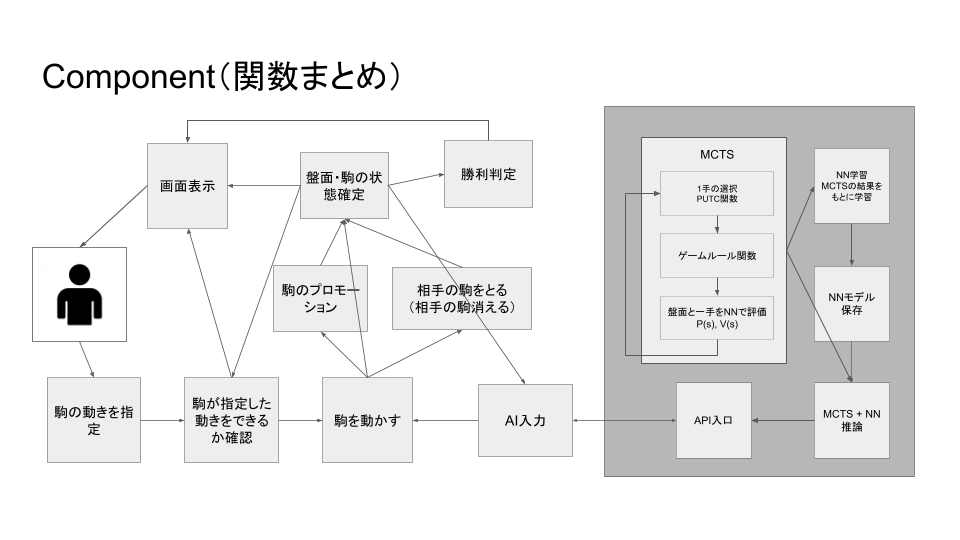
checker_ml/ ├── src/ │ ├── game/ # Pygameによるチェッカーゲーム │ │ └── checker.py │ ├── ml/ # AlphaZero実装 │ │ ├── checker_state.py │ │ ├── gameplay.py │ │ └── alpha_zero/ │ │ ├── dual_network.py # ニューラルネットワークモデル │ │ ├── pv_mcts.py # モンテカルロ木探索 │ │ ├── selfplay.py # セルフプレイ │ │ ├── train_network.py # ネットワーク学習 │ │ ├── evaluate_network.py # モデル評価 │ │ └── train_cycle.py # 学習サイクル │ └── infrastructure/ # インフラストラクチャ │ ├── aws/ # AWS連携(S3) │ └── fastapi/ # APIサーバー ├── sandbox/ # 実験・検証用 ├── requirements.txt # Python依存パッケージ ├── Dockerfile # Dockerイメージ定義 ├── docker-compose.yml # Docker Compose設定 ├── DOCKER_SETUP.md # Docker環境構築ガイド └── AWS_SETUP.md # AWS環境構築ガイド
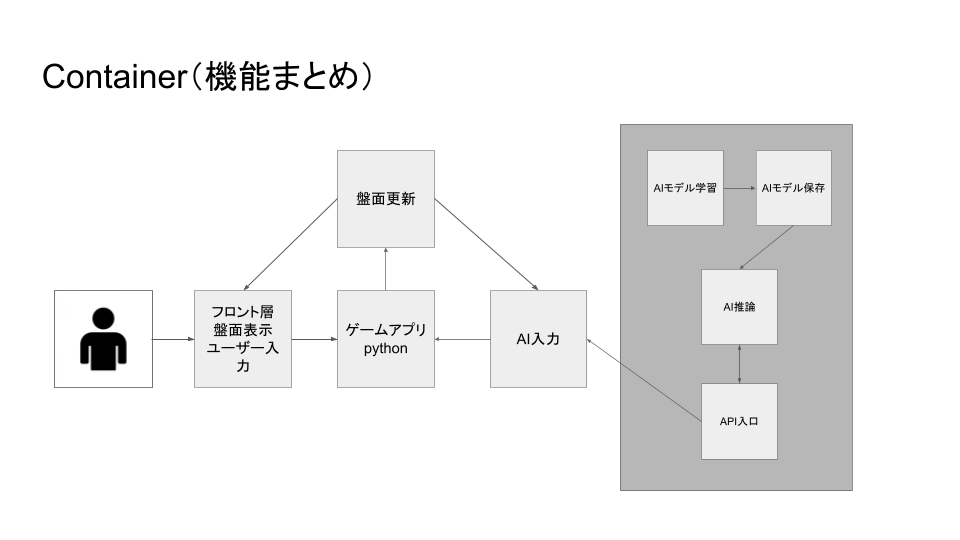
・チェッカーゲームの実装: Pygameを使用した6×6チェッカーゲーム ・AlphaZero学習パイプライン: ・セルフプレイによるデータ生成 ・ニューラルネットワークの学習 ・モデルの評価と更新 ・FastAPI APIサーバー: AWS SageMakerにデプロイ可能なRESTful API ・GPU対応: NVIDIA GPUを使用した高速学習 ・Docker対応: 環境構築が簡単で再現性の高い実行環境
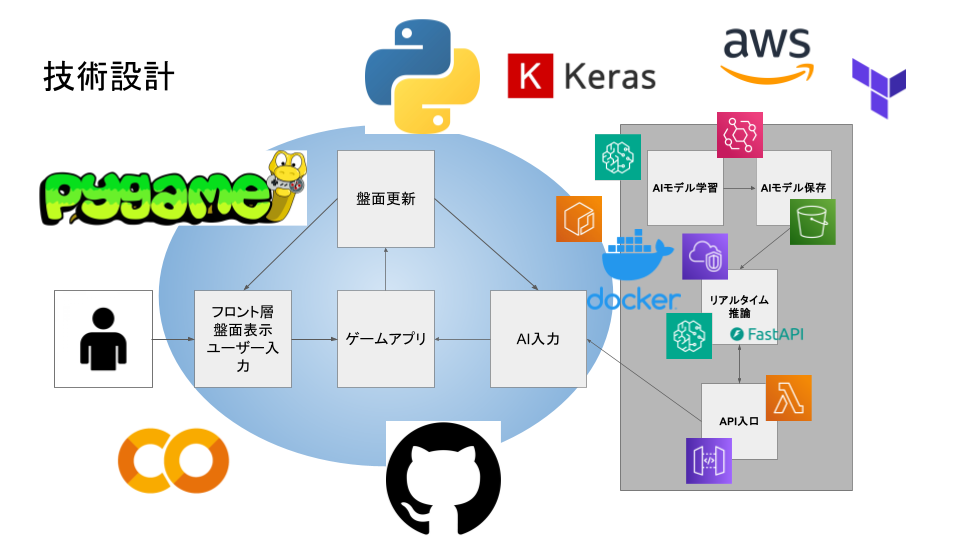
・ゲームエンジン: Pygame
・機械学習: TensorFlow 2.17.0 (Dockerベースイメージ), Keras 3.5.0 ・Webフレームワーク: FastAPI 0.118.0 ・コンテナ: Docker, Docker Compose ・クラウド: AWS (VPC, S3, Lambda, SageMaker, APIGateway) ・言語: Python 3.x
・src/ml/alpha_zero/dual_network.py: ニューラルネットワークモデルの定義 ・src/ml/alpha_zero/pv_mcts.py: PVモンテカルロ木探索の実装 ・src/ml/alpha_zero/selfplay.py: セルフプレイによるデータ生成 ・src/ml/alpha_zero/train_network.py: ニューラルネットワークの学習 ・src/ml/alpha_zero/evaluate_network.py: モデルの評価と更新 ・src/ml/alpha_zero/train_cycle.py: 学習サイクルの管理
## src/gpt_ml/alpha_zero/pv_mcts.py # 子ノードが存在しない時(展開) if not self.child_nodes: # ニューラルネットワークでポリシーとバリューを取得 policies, value = predict(model, self.state)
Policy(行動確率分布)とValue(状態の価値)をニューラルネットワークから取得し、探索を進める。
## src/gpt_ml/alpha_zero/pv_mcts.py # モデルの学習 model.fit( x=xs, # 入力テンソル(N, H, W, 4) y=[y_policies, y_values], # 出力ポリシーと価値 batch_size=128, epochs=RN_EPOCHS, callbacks=[lr_scheduler, print_callback], verbose=0, )
xs: (サンプル数, 盤面高さ, 盤面幅, チャンネル数)のテンソル y: Policy, Value
・Docker Desktop: GPUを使用する場合は以下も必要 ・Windows: WSL2(Docker Desktopが自動でGPU対応) ・Linux: nvidia-container-toolkitまたは Python 3.x環境とTensorFlow 2.17.0
AWS_SETUP.md を参照してください。
DOCKER_SETUP.md を参照してください
https://4djo1pd0h8.execute-api.ap-northeast-1.amazonaws.com/
リクエスト:
{ "board": [ [0, 1, 0, 0, 0, 0], [1, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 1], [0, -1, 0, 0, -1, 0], [0, 0, 0, 0, 0, 0] ], "turn": 1, "turn_count": 10 }
0: 空マス 1: RED(赤)の通常駒 2: REDのキング -1: BLUE(青)の通常駒 -2: BLUEのキング
1: RED -1: BLUE レスポンス:
{ "version": "1.0.0", "action": { "selected_piece": [4, 1], "move_to": [3, 0], "captured_pieces": [] } }
ルートエンドポイント
レスポンス:
{ "Hello": "World" }
ヘルスチェック用エンドポイント
レスポンス:
{ "status": "ok" }
AIの次の手を取得
リクエスト:
{ "board": [ [0, 1, 0, 0, 0, 0], [1, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 1], [0, -1, 0, 0, -1, 0], [0, 0, 0, 0, 0, 0] ], "turn": 1, "turn_count": 10 }
0: 空マス 1: RED(赤)の通常駒 2: REDのキング -1: BLUE(青)の通常駒 -2: BLUEのキング
1: RED -1: BLUE レスポンス:
{ "version": "1.0.0", "action": { "selected_piece": [4, 1], "move_to": [3, 0], "captured_pieces": [] } }
5日 ~ 13日:設計(C4モデル) 13日 ~ 18日:事前準備(sandbox/) 18日 ~ 23日:開発(src)
・sandboxの使い方の勉強(使ったことがないメンバーいたので) ・参考資料を読んで、より小さいゲーム(三目並べ)で実装を練習
・プログラミング初心者のメンバーおり、分からないことが多かった ・SageMakerのデプロイ ・AWSの費用
スッキリわかるAlphaZero: https://horomary.hatenablog.com/entry/2021/06/21/000500



