














推しアイデア
コンビニは毎日定期的に行くことに気づき、マッチングのサービスを掛け合わせた
―
コンビニは毎日定期的に行くことに気づき、マッチングのサービスを掛け合わせた
メンバーが既存のマッチングアプリに不満を持っていた
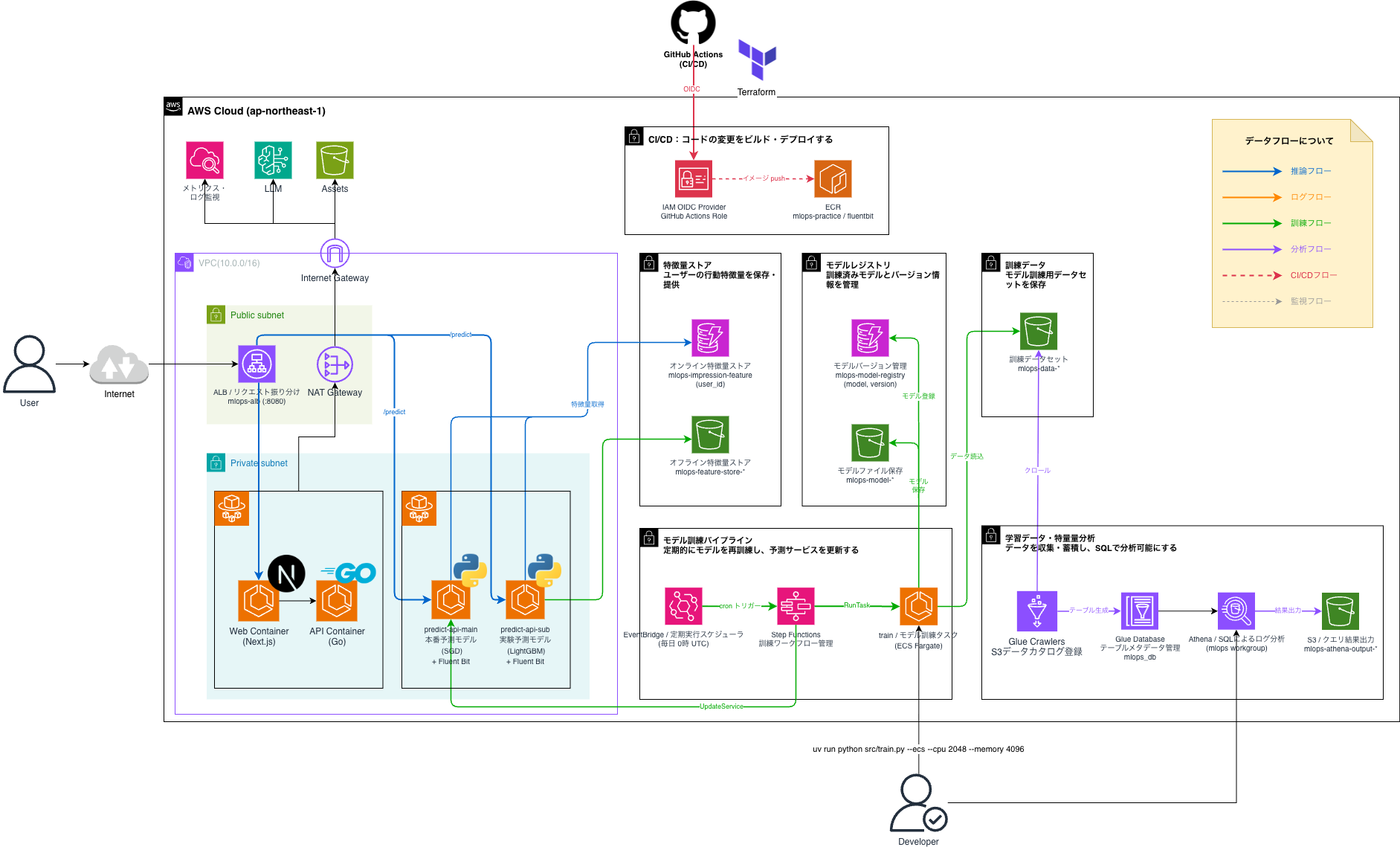
コンビニに入ったら誰かとマッチング、MLOpsを使ったガチ機械学習パイプラインの開発
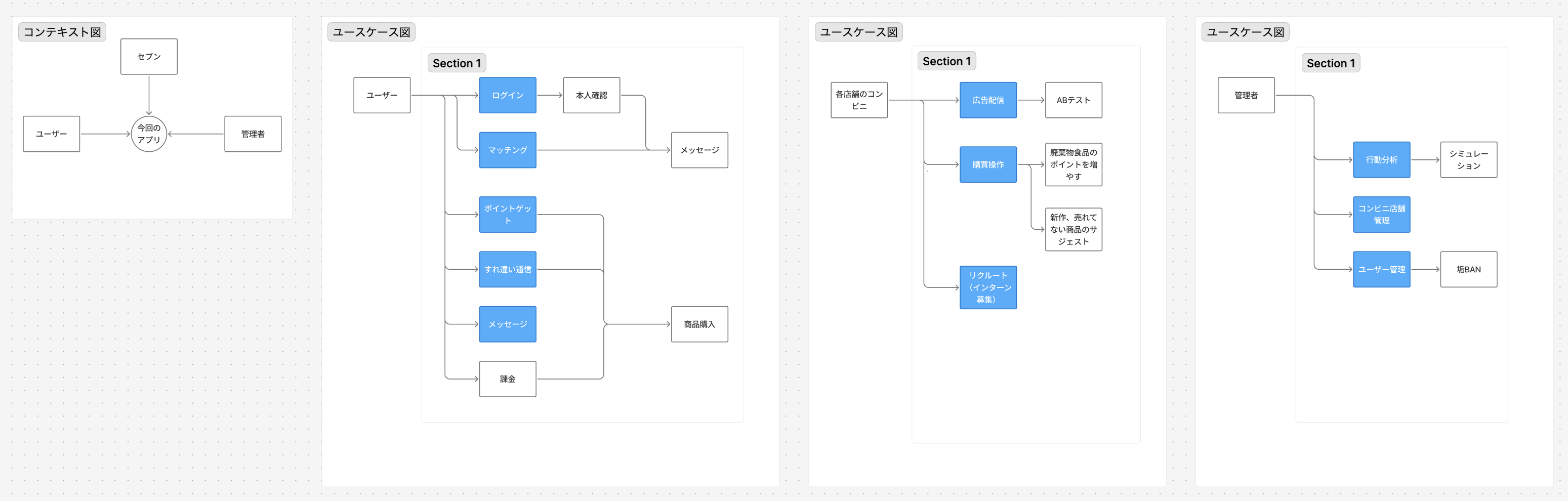
従来のマッチングアプリは「プロフィールだけ」で相手を選びます。Auroraは**「同じ時間帯に近くのコンビニにいた」**という偶然の接点をきっかけにマッチングする、新しい出会いの形を提案します。
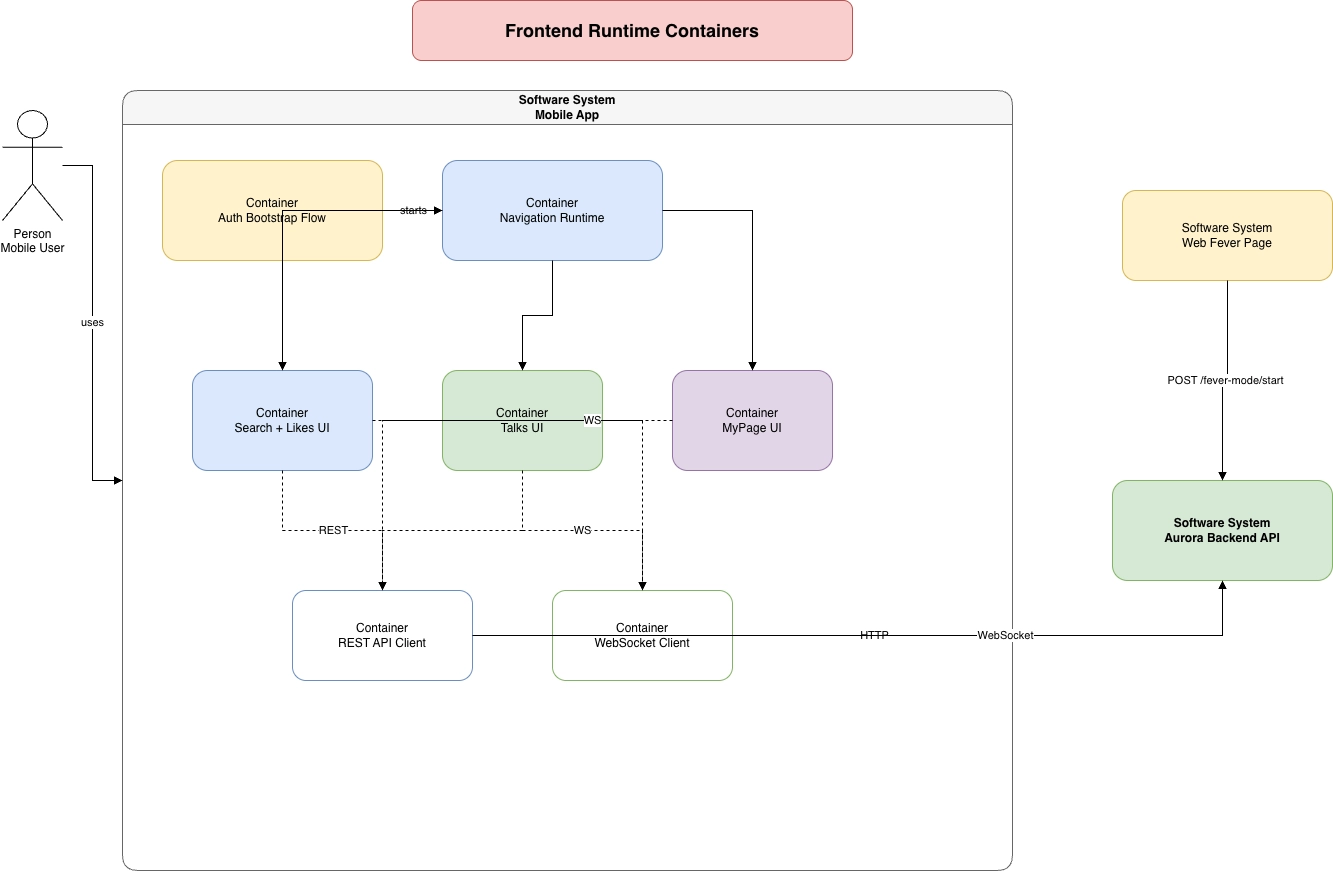
CloudFront (CDN) ↓ ALB (public subnet) ↓ ECS Fargate (private subnet) ├── Go API コンテナ └── Next.js 管理画面コンテナ ↓ RDS PostgreSQL (private subnet) ↓ S3 (プロフィール画像・アセット) ↓ Bedrock Claude (レシートOCR)
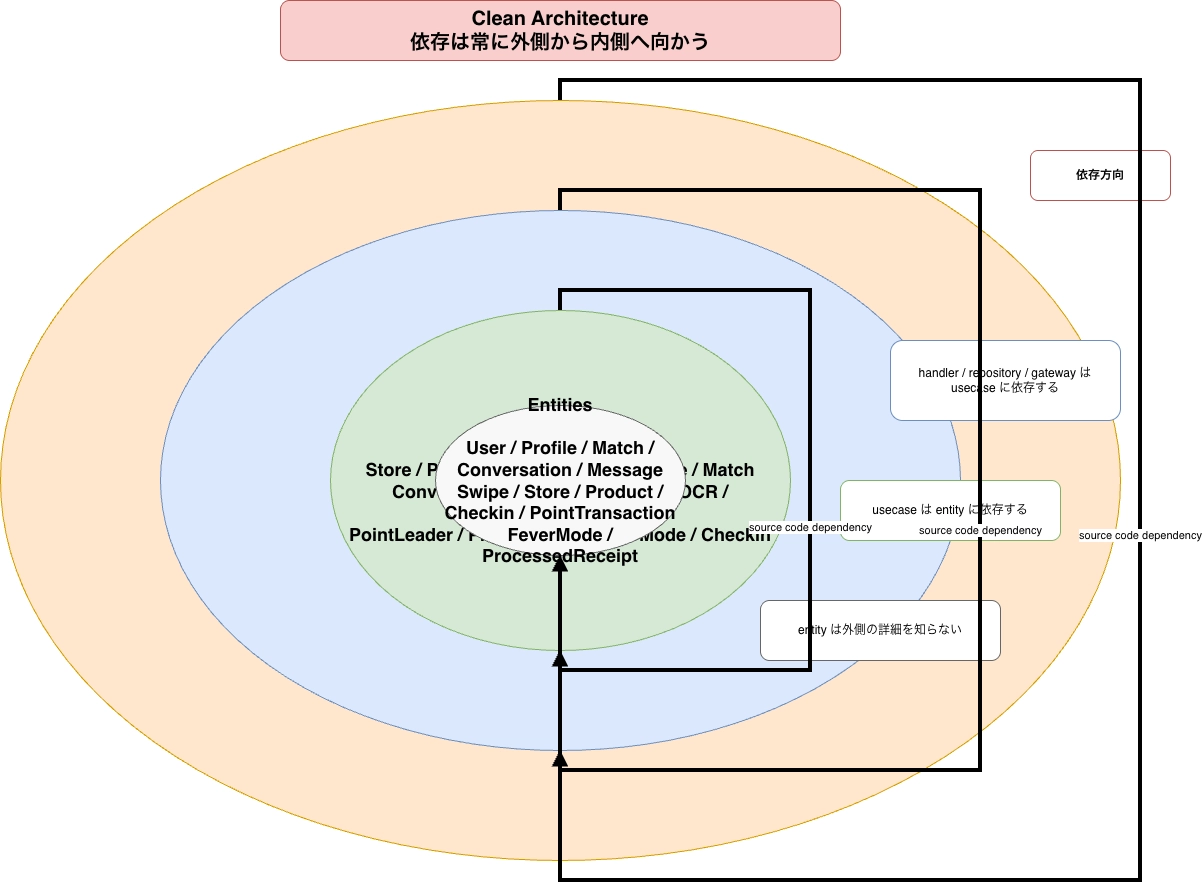
terraform apply 一発で環境構築完了Handler (HTTP) → Usecase (ビジネスロジック) → Repository (DB) → Entity (ドメインモデル)
各レイヤーがインターフェースで疎結合になっており、テスト・変更・拡張が容易。
Dependencies構造体パターン
type Dependencies struct { UserUsecase usecase.UserUsecase ProfileUsecase usecase.ProfileUsecase SwipeUsecase usecase.SwipeUsecase MatchUsecase usecase.MatchUsecase CheckinUsecase usecase.CheckinUsecase // ... 機能追加時も引数の順序を気にせず拡張可能 }
TDD(テスト駆動開発)
go test ./... で全テスト一括実行レイヤーごとの責務分離
| レイヤー | 責務 | テスト方法 |
|---|---|---|
| Entity | ドメインモデル定義 | - |
| Usecase | バリデーション・ビジネスロジック | モックrepoでユニットテスト |
| Repository | DB操作・SQL | 統合テスト(実DB) |
| Handler | HTTP ↔ Usecase変換 | httptestでユニットテスト |
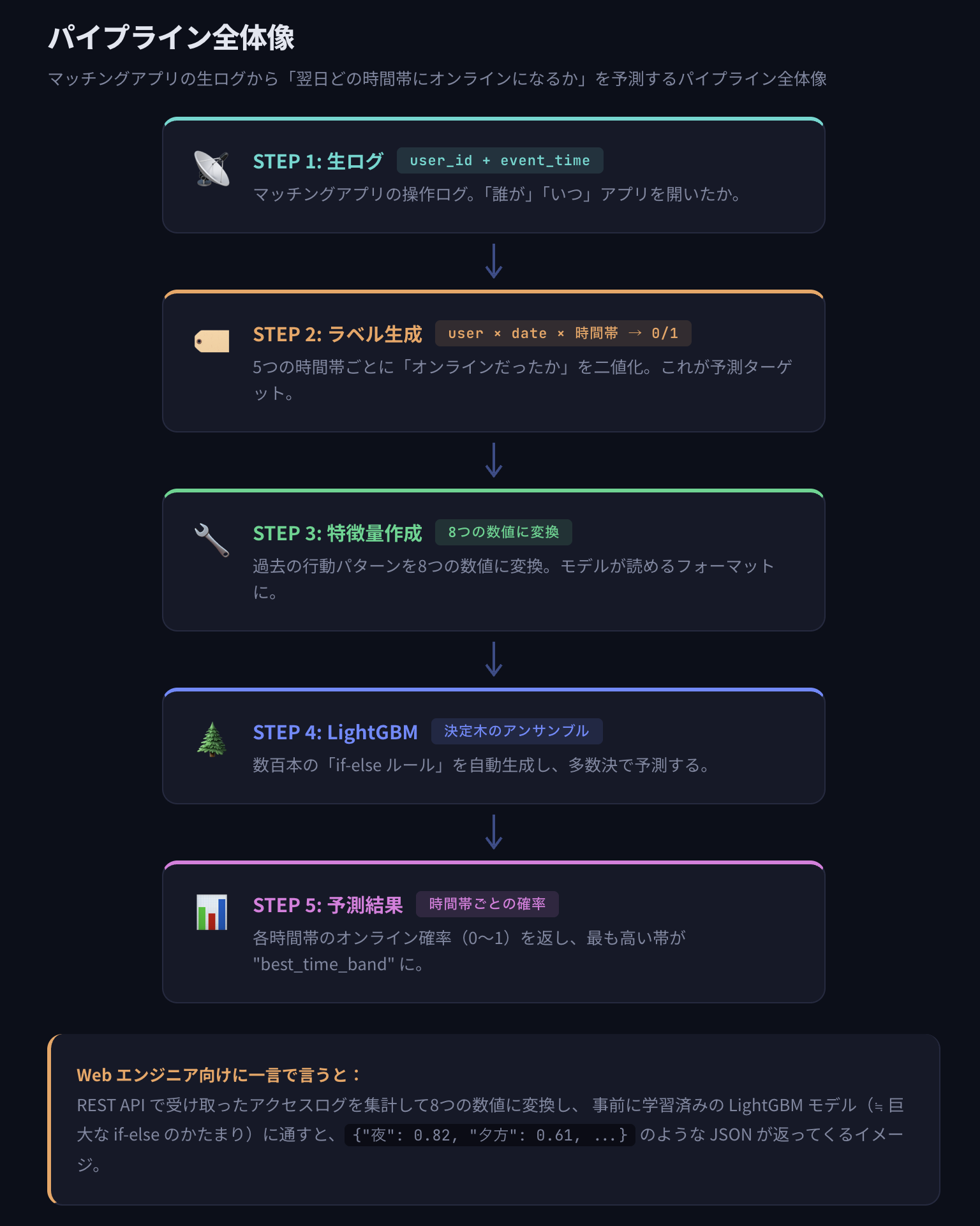
レスポンスが0.1秒ぐらいで爆速
リアルタイム推論
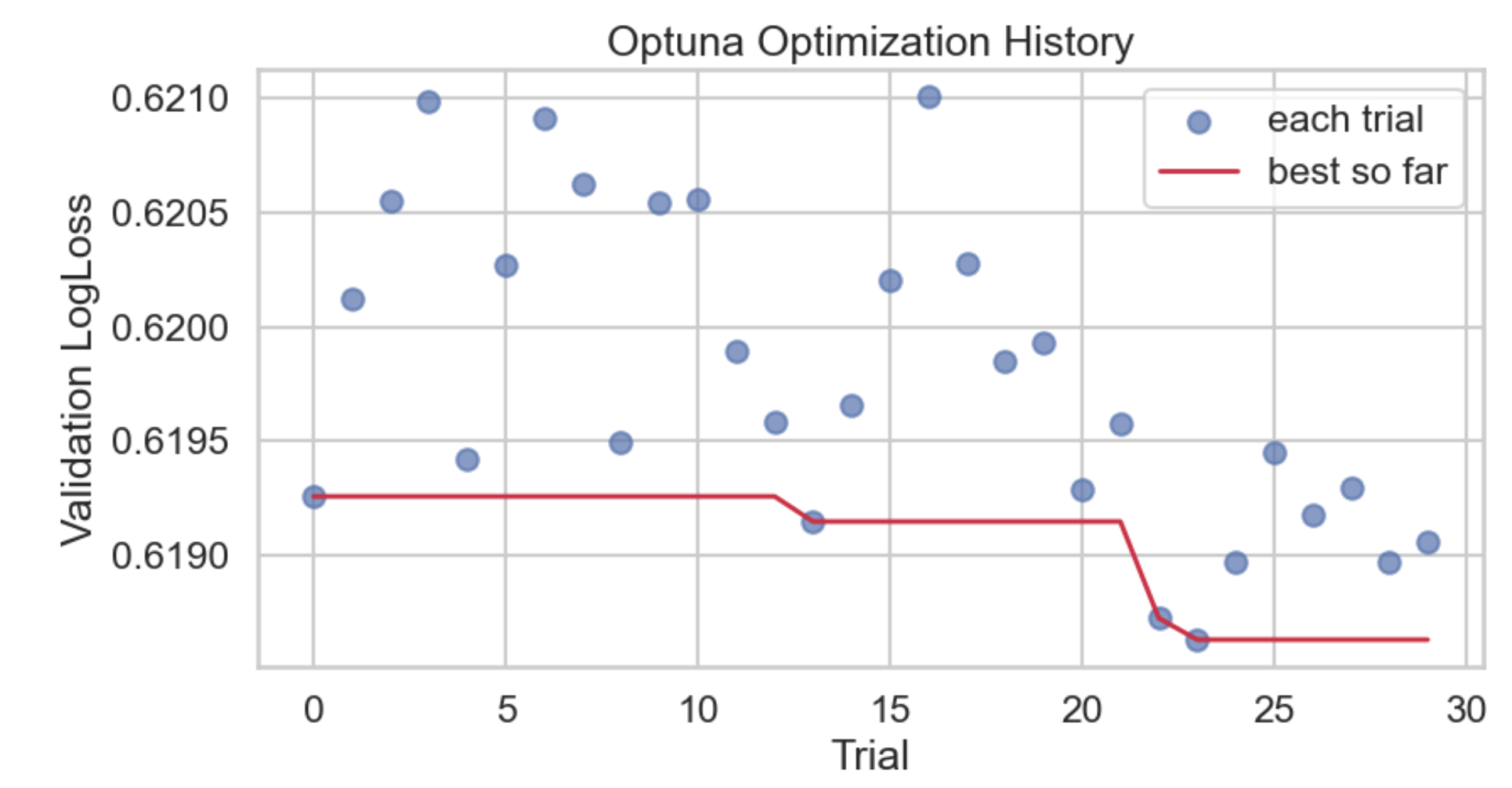
Optunaを使ったブラックボックス最適化
サービス運営に必要なMLOpsの各コンポーネントをフルスクラッチ実装した
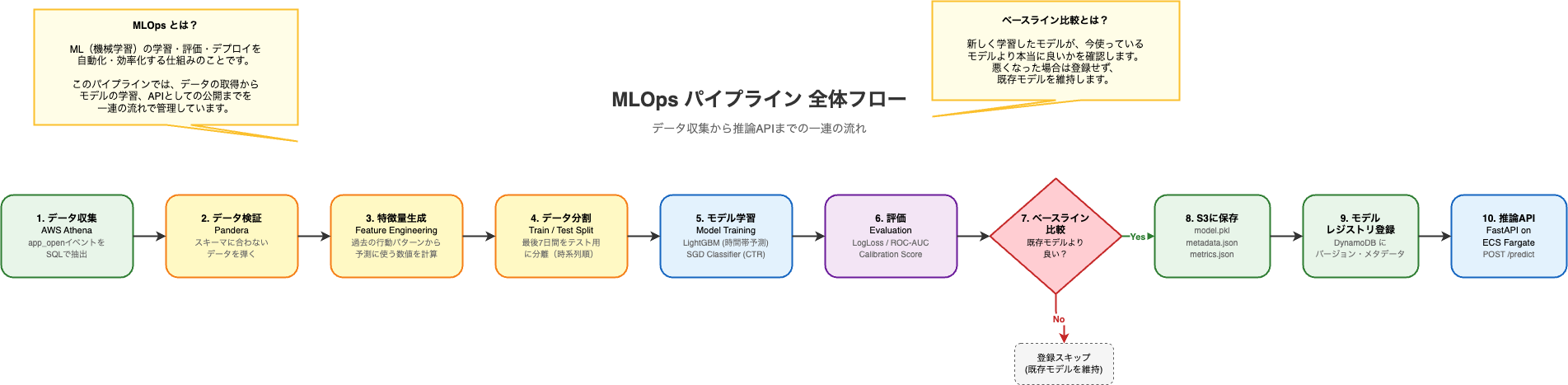
要件
採用技術
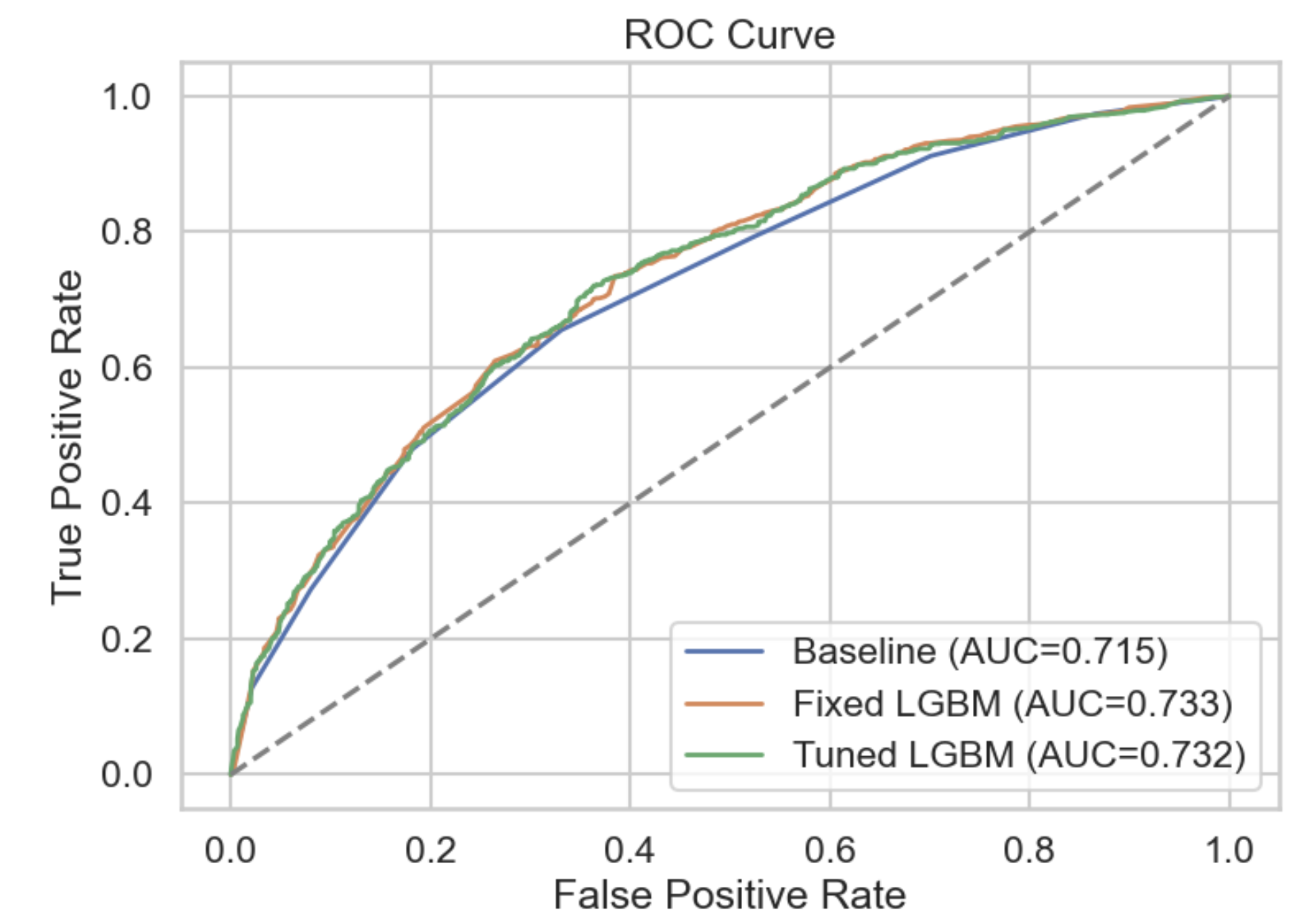
本番主軸は online_time_band(LightGBM)で、sgd_classifier_ctr は代替/実験系の構成です。
勾配ブースティング決定木(GBDT, 二値分類)
LGBMClassifier): 目的変数は online_flag(オンライン有無の0/1)。多数の弱学習器(決定木)を勾配方向に逐次追加して損失(logloss)を下げる方式。非線形性・特徴量相互作用を自動で拾えるのが強み。time_band_enc や prev_7d_* のような時系列由来特徴量の非線形境界学習。線形オンライン学習(確率出力のロジスティック損失)
loss=log_loss): 実質ロジスティック回帰をSGDで最適化。大規模・高次元で軽量に回せる。sgd_classifier_ctr)のベースライン/高速学習用途。ハッシュトリック(高次元カテゴリ特徴の圧縮)
col=value 文字列を固定次元(2**18)に写像。One-Hotを明示的に作らず疎→密変換で扱う。時系列分割(リーク防止)
shuffle=False、または「最後N日をテスト」)で分離。履歴特徴量エンジニアリング(ローリング統計)
prev_1d_same_band_onlineprev_3d_same_band_online_rate, prev_7d_same_band_online_rate, prev_7d_any_online_rateactive_days_last_7d評価アルゴリズム
sum(y_pred)/sum(y_true) を1に近づける判定。確率総量の過大/過小を監視。ハイパーパラメータ最適化
alpha, learning_rate, eta0 を探索し、neg_log_loss を最大化(= logloss最小化)。log=True)で広い範囲を効率探索。合成データ生成(デモ/検証用)
モデル学習
lightgbm: 本番主力の二値分類器。木ベースで前処理負荷が比較的低い。scikit-learn: SGDClassifier、train/test split、CV、各種メトリクス、calibration curve。最適化・AutoML寄り
optuna: SGD系モデルのハイパーパラメータ探索。試行管理とベスト探索を担う。データ処理・特徴量計算
pandas: join/groupby/rolling/日時処理で特徴量作成の中核。numpy: ベクトル演算、確率計算、クリッピング、乱数生成。データ品質保証
pandera: OnlineEventSchema などで列型・NULL・制約を厳格検証。入力ドリフト/破損検知に有効。可視化・解析
matplotlib, seaborn: ROCやcalibration可視化、探索分析に利用。モデル永続化
joblib: 学習済みモデルやハッシャーを pkl 保存/読込(推論時再利用)。推論サービング
fastapi: /predict API提供、入力バリデーション、レスポンス整形。uvicorn: ASGIランタイムとしてFastAPIを本番実行。AWS連携(MLOps基盤)
awswrangler: Athena SQL実行結果をDataFrameとして取得。boto3: S3/DynamoDB/ECS周辺のAWS操作(artifact保存、model registry参照など)。開発補助(品質/運用)
pydantic: APIリクエストモデル定義。tqdm, psutil: 進捗・リソース監視系の補助。pytest, mypy, ruff: テスト・型安全・静的品質の維持。!


