












推しアイデア
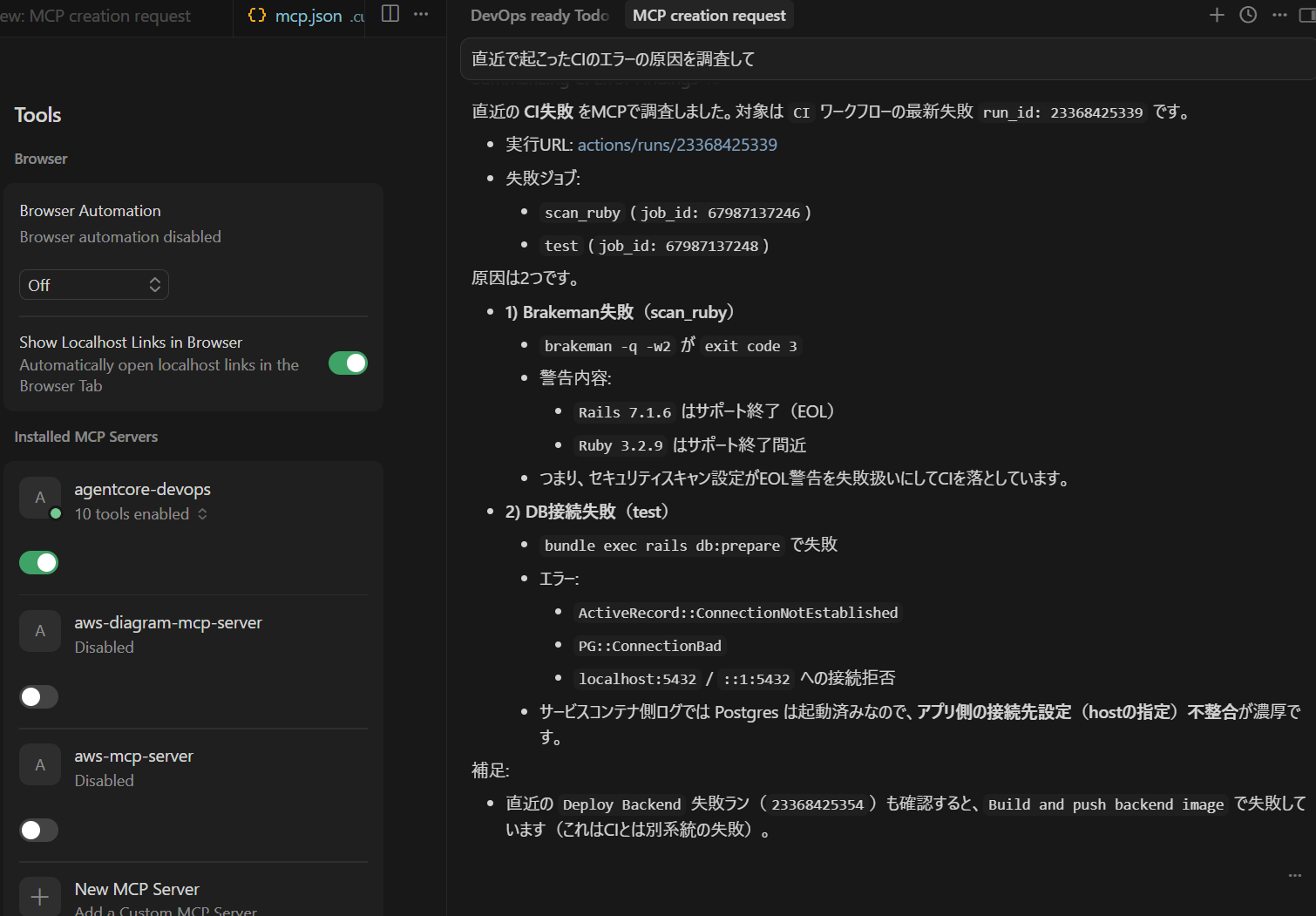
開発者が「なぜ障害が起きたのか?」を自然言語で質問すると、ログ・メトリクス・デプロイ履歴・CI/CD情報を統合し、AIエージェントが原因を推論するしてくれる。
開発者が「なぜ障害が起きたのか?」を自然言語で質問すると、ログ・メトリクス・デプロイ履歴・CI/CD情報を統合し、AIエージェントが原因を推論するしてくれる。
システムの障害調査を行う際に、開発者は ログ、メトリクス、デプロイ履歴、CI/CDなど複数ツールを横断する必要があり、原因特定に時間がかかる。 →Agnetがツールを横断して隅々まで情報を取得、統合し原因を特定できると楽なのでは?
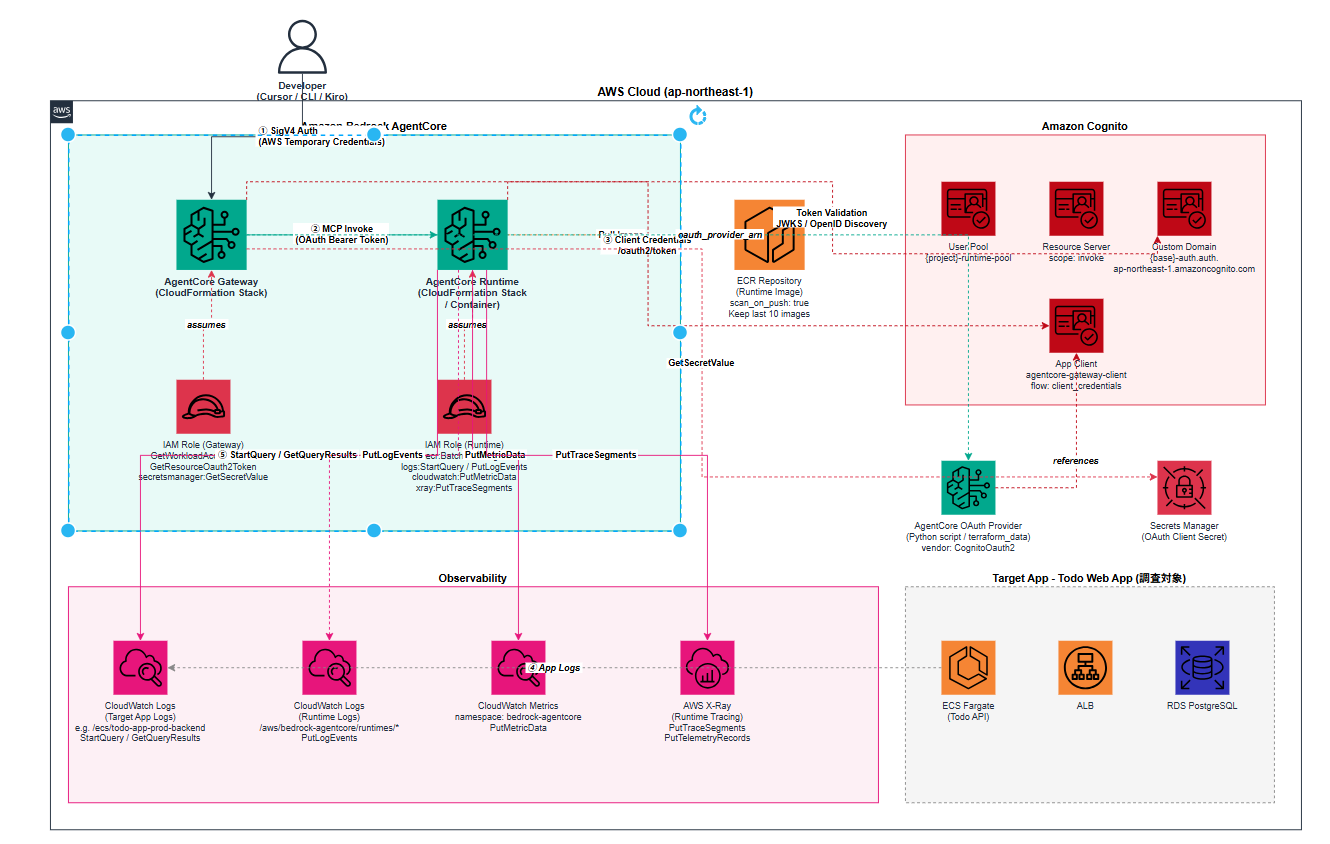
Amazon Bedrock AgentCoreを中心に、ログ・メトリクス・デプロイ履歴など複数のDevOpsデータを統合したこと。 AgnetCore、Kiroなど使ったことないサービスを利用したこと。
本プロジェクトでは、システムの開発者に対して ログ・メトリクス・デプロイ履歴・CI/CDなどの情報を統合し、AIエージェントが障害原因を分析する DevOps障害調査支援プラットフォームを提案する。
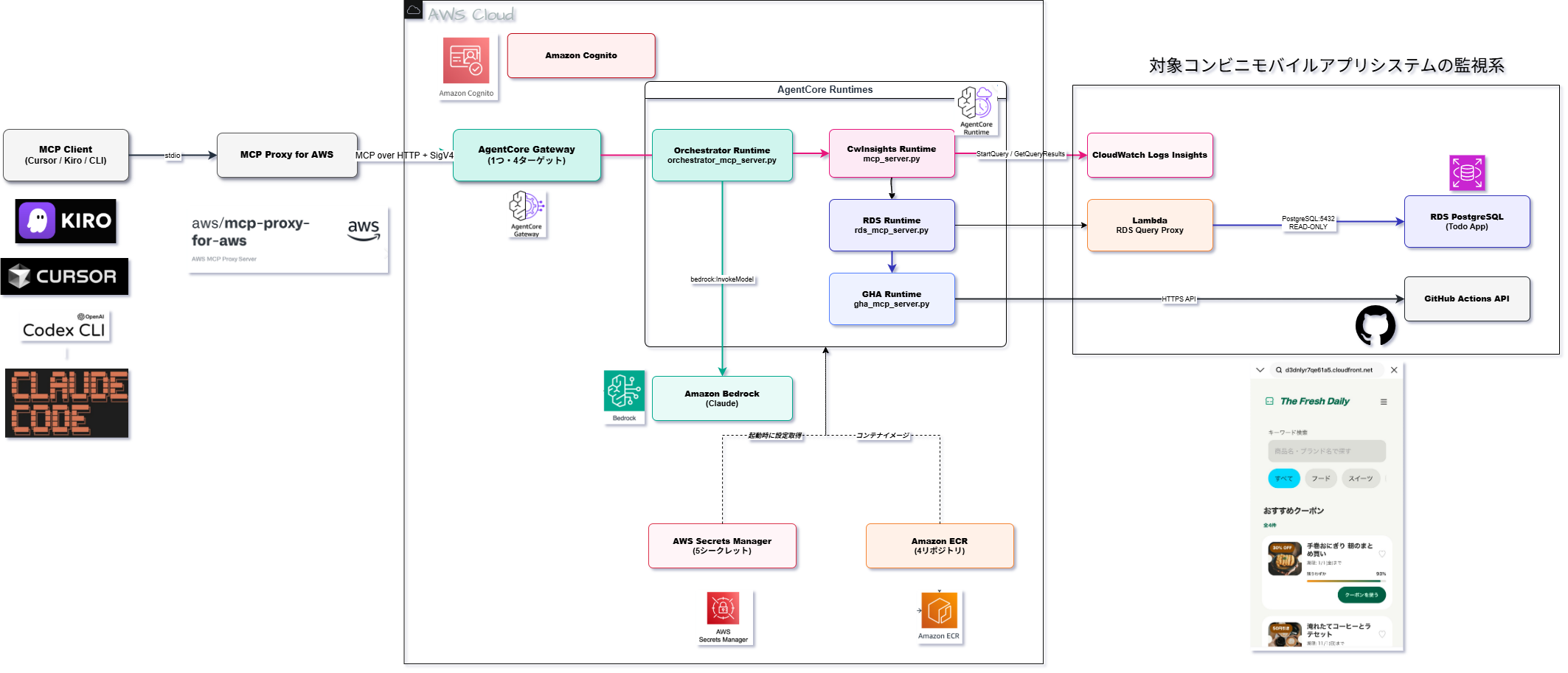
自作MCPサーバー×AWSAgnet→おまけで拡張機能も作りました 開発者は IDE や CLI から自然言語で質問することで、「なぜこの障害が発生したのか」を即座に取得できる。
・AWS Observability Kiro Power ・AWS DevOps Agent ・Datadog AI ・NewRelic AI システム全体を横断した原因分析は依然として開発者の手作業に依存している。
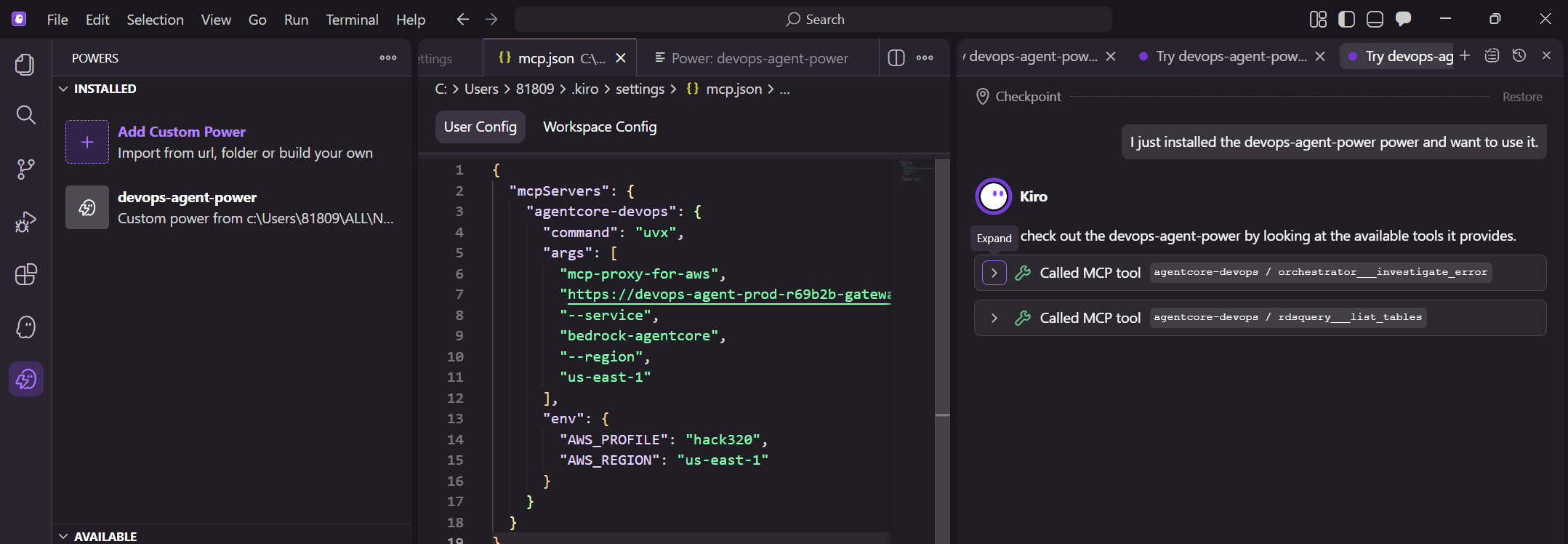
前提条件:対象ののシステムにAWS Observability Toolsがはいっていること ➀開発者がクレデンシャルを登録 ➁MCP設定ファイルを設定 ➂Agnet Terraformを導入(対象システムのタグを設定)
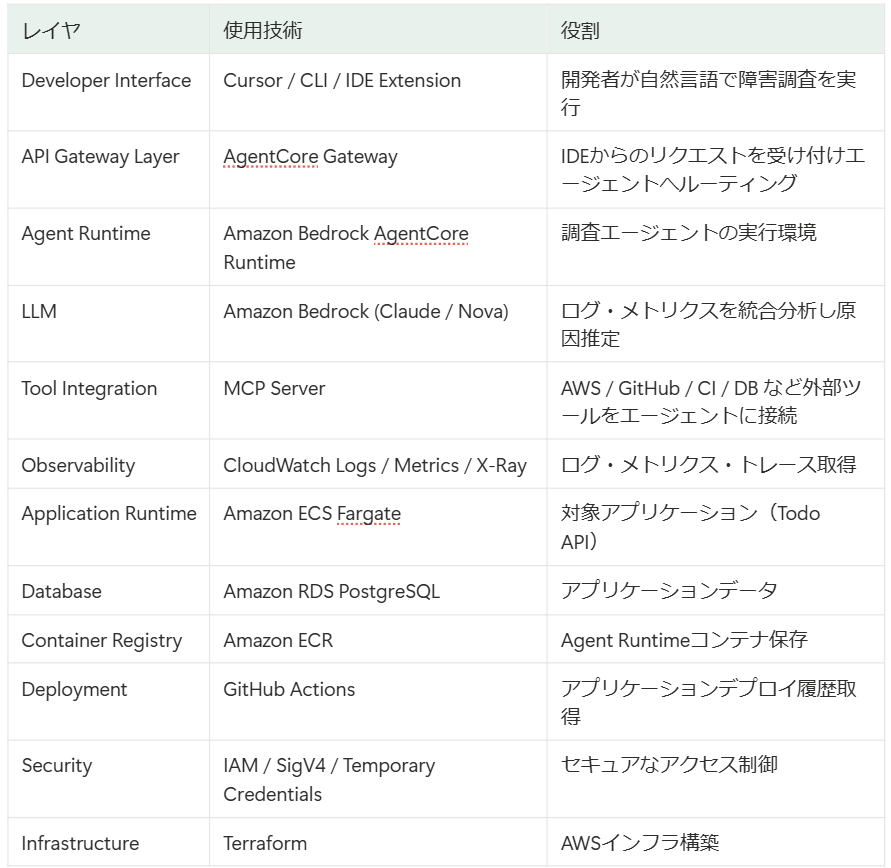
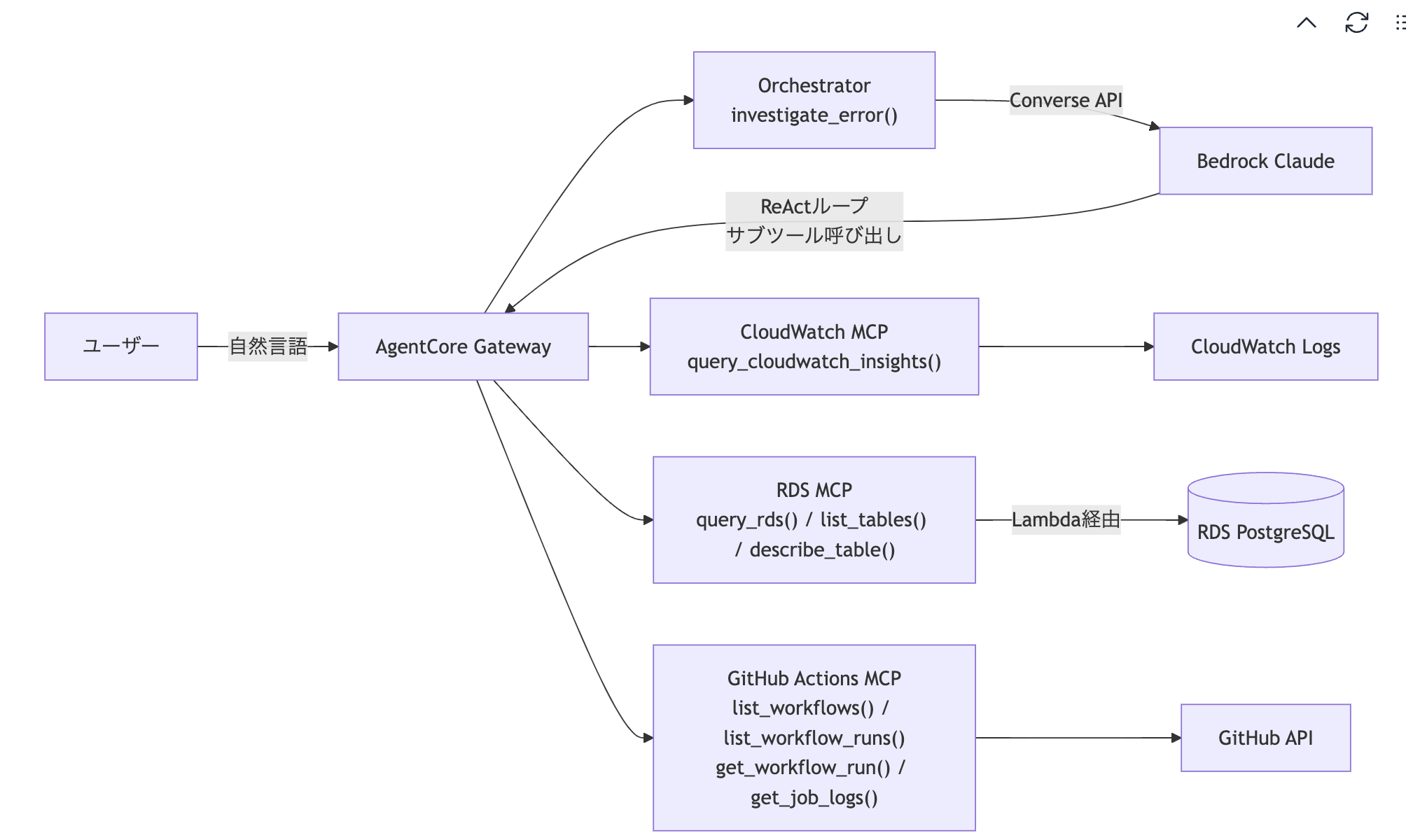
※参照:https://files.speakerdeck.com/presentations/eaeafe27138c454f97f2047aa28d785c/slide_26.jpg
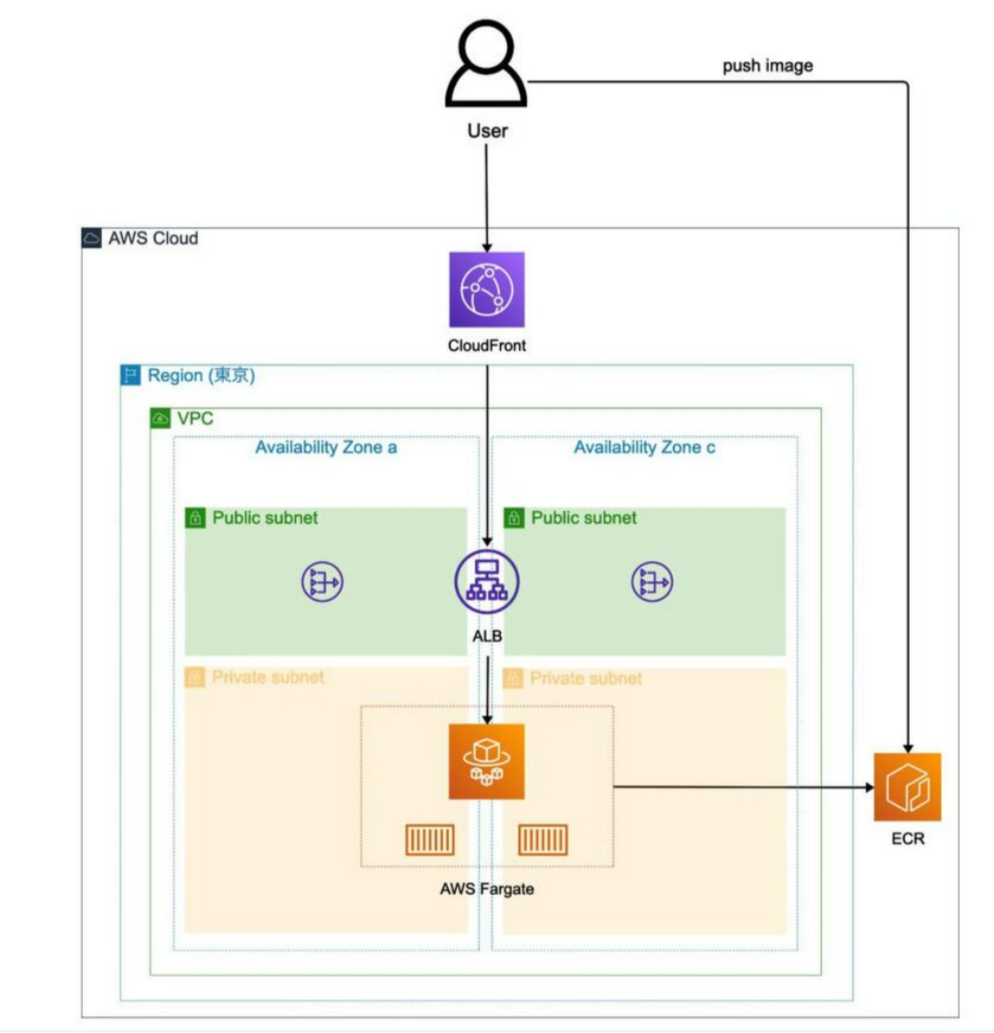
・認証周りの強化 ・MCP追加(CloudTrail/CloudWatch Logs/Datadog) ・IDEにMDとして調査結果をまとめる拡張機能 ・トークン消費量をいかに抑えるか ・A2Aで原因調査の精度を上げる ・AgnetCoreのベストプラクティスの学習 ・EventBridgeによるAgnetの自動実行からMD出力
・こうめい(AgentCore内部実装+対象アプリ開発) ・マシュー(MCPツール実装+拡張機能) ・岸(全体設計+認証周り)
・アプリとインフラの部分を分けないで一括でTerraformで管理してしまった →今回でいうとアプリの部分のECRは分けるべきでした
https://drive.google.com/file/d/1jlYbmIQg7-3ltulugvyemfTc9UZqlju1/view?usp=sharing
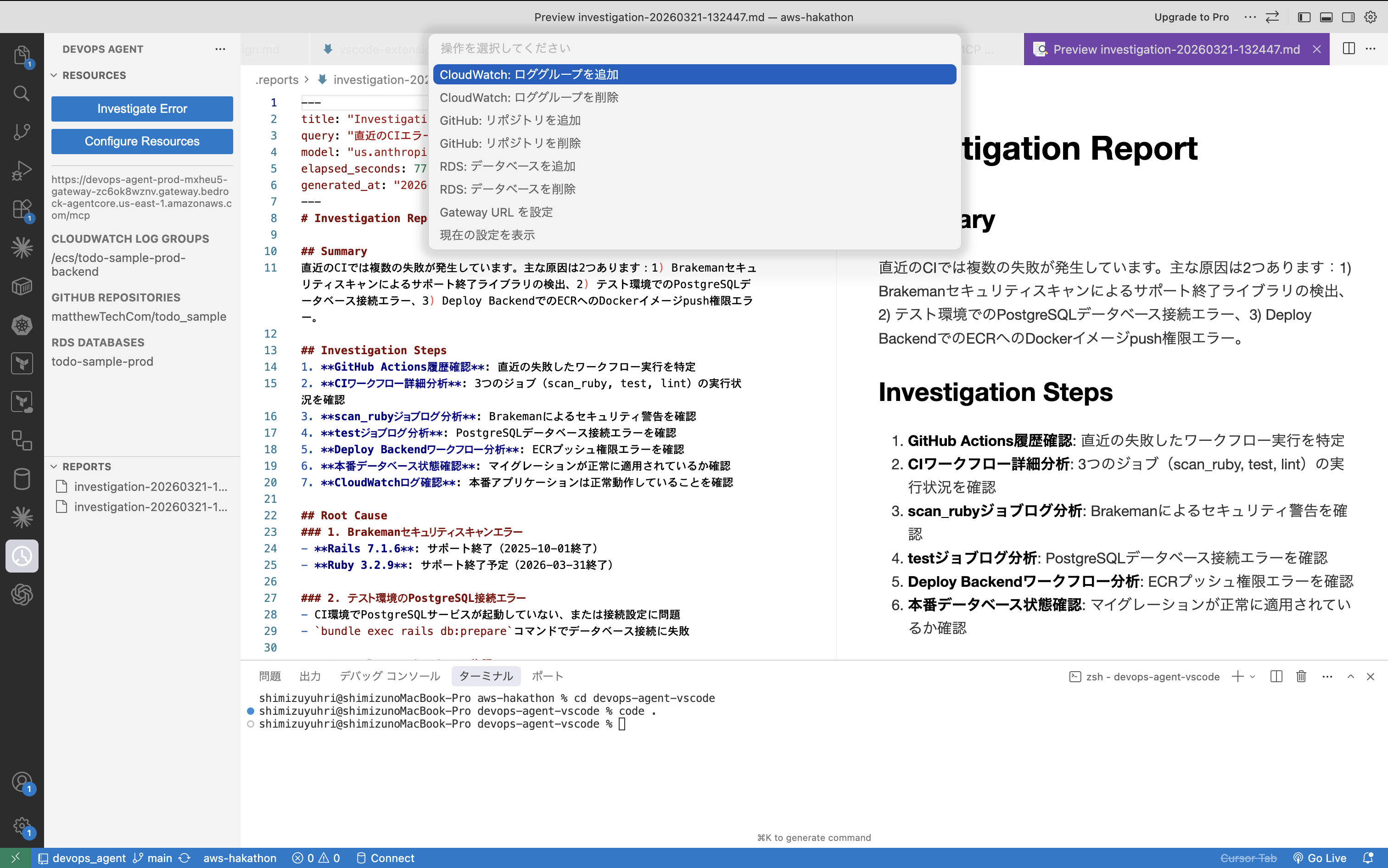
リソース指定画面




{kind=link}