












推しアイデア
面接をテキストの文字起こしだけで採点すると、話速や間、抑揚といった「どう話したか」がまるごと抜ける。 そこを音声から数値で拾って評価軸を足し、テキスト単体よりも面接を細かく見られるようにした。音声側のスコアは毎回同じ値が出るので、評価がブレないのもありがたい。
面接をテキストの文字起こしだけで採点すると、話速や間、抑揚といった「どう話したか」がまるごと抜ける。 そこを音声から数値で拾って評価軸を足し、テキスト単体よりも面接を細かく見られるようにした。音声側のスコアは毎回同じ値が出るので、評価がブレないのもありがたい。
自分が就活していたとき、面接を録画して文字起こしし、それをLLMに講評させていた。 やってみて気づいたのは、テキストに落とした瞬間に肝心の話し方が消えること。 声の情報こそ面接の良し悪しを分けるのに、と思ったのがそのまま動機になった。
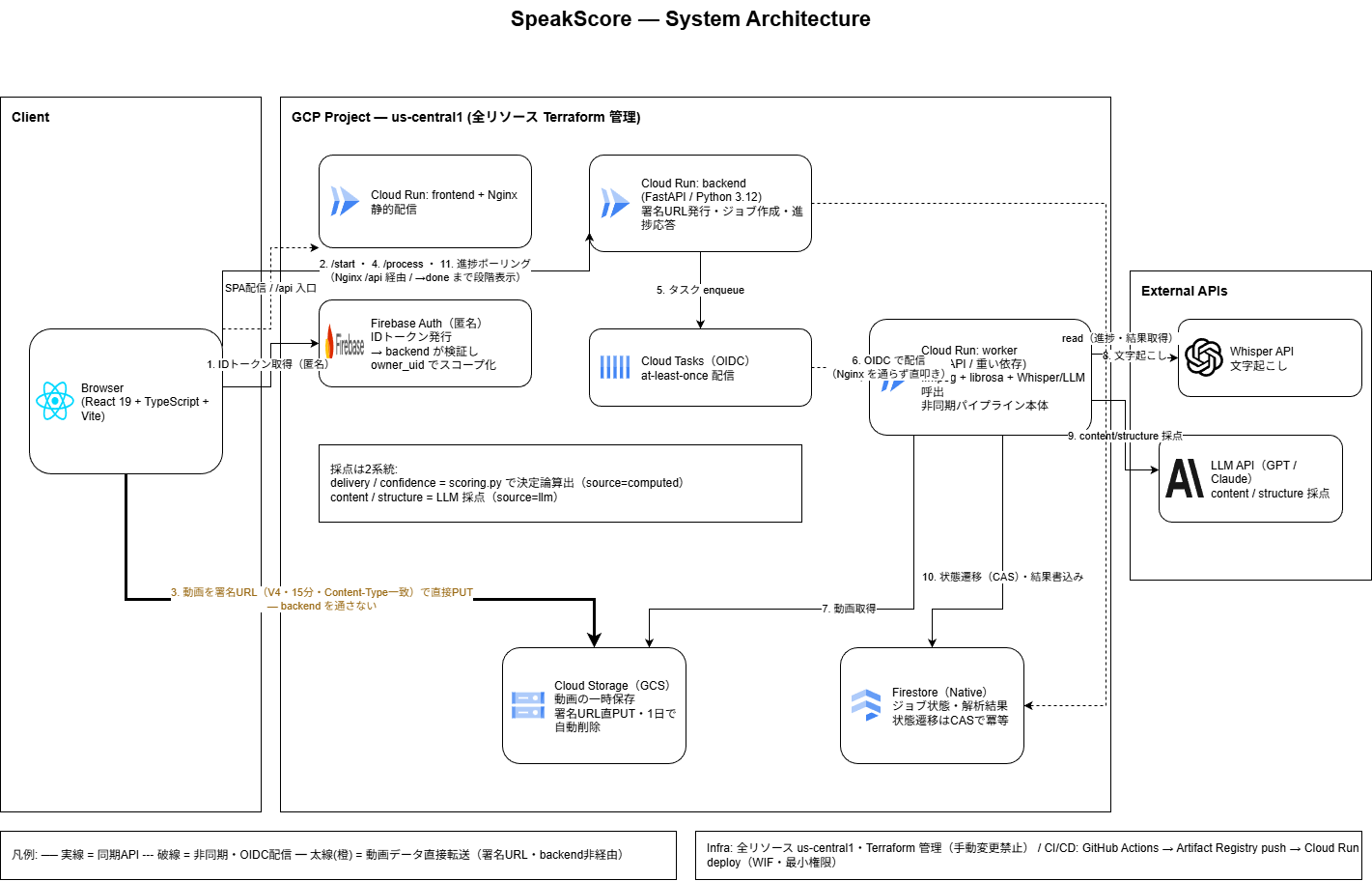
待機コストをゼロに保ったまま、ちゃんとした非同期処理を回す Cloud Tasks の worker パイプライン 音声特徴量(librosa)で測る軸とLLMで測る軸を分けたハイブリッド採点 動画はブラウザから署名URLでGCSへ直接アップロードし、バックエンドには一切通さない
SpeakScore は、就活の面接動画を上げると文字起こし・音声分析・スコア・改善点を返すツールです。テーマは「運に頼らず、実力で内定を掴む」。
面接は相手やお題、その日の調子に左右されやすく、しかも終わったあとに何が良くて何が悪かったのかが返ってきません。録画を自分で文字起こししてLLMに投げる手もありますが、運用が重いうえ、テキストにした時点で話し方の情報が落ちます。SpeakScore は動画1本でその手間を肩代わりし、加えて音声そのものを数値で評価して返します。
デプロイまで完了したので、ぜひお手元で触ってみてください。
 https://speak-score-frontend-ps6252xwfa-uc.a.run.app/jobs/690ec3f0c3924f35b02c1e3b9f1f92fd
https://speak-score-frontend-ps6252xwfa-uc.a.run.app/jobs/690ec3f0c3924f35b02c1e3b9f1f92fd
動画をアップロードすると、音声抽出・文字起こし・音声分析・評価がパイプラインで自動的に走ります。処理は数分かかるので、extracting_audio → transcribing → analyzing_audio → evaluating の各段階を画面に出して進捗が見えるようにしました。
結果は評価軸ごとのスコアをレーダーチャートやタイムラインで表示します。各スコアには source(computed=算出 / llm=LLM採点)を持たせていて、どうやって出した点なのかが分かるようにしてあります。改善点のコメントは、文字起こしやフィラー、無音区間と紐づけて返します。
ユーザーがやることは「動画を上げて、結果を見る」だけです。各画面で何が起きているかを順に追います。
面接の録画を選ぶだけ。このとき動画はバックエンドを通さず、ブラウザから保存先(GCS)へ署名付きURLで直接アップロードされます。
動画が保存先へ直送されている状態。バックエンドを経由しないので、大きな動画でもサイズ制限やタイムアウトに引っかかりません。
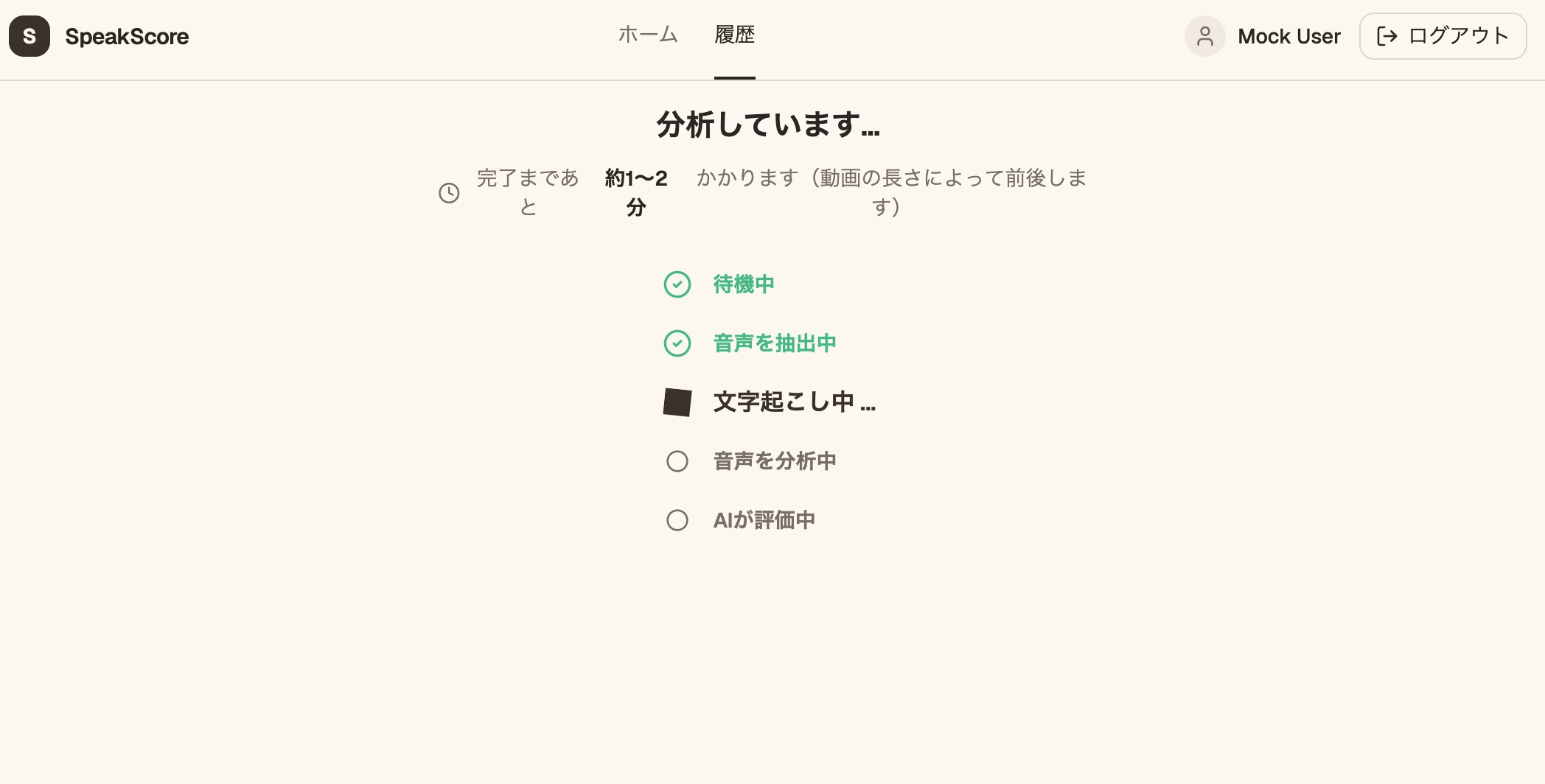
アップロードが終わると解析が自動で順番に走ります。数分かかるため、今どの段階か(音声抽出 → 文字起こし → 音声分析 → 評価)を画面に出して進捗が見えるようにしています。
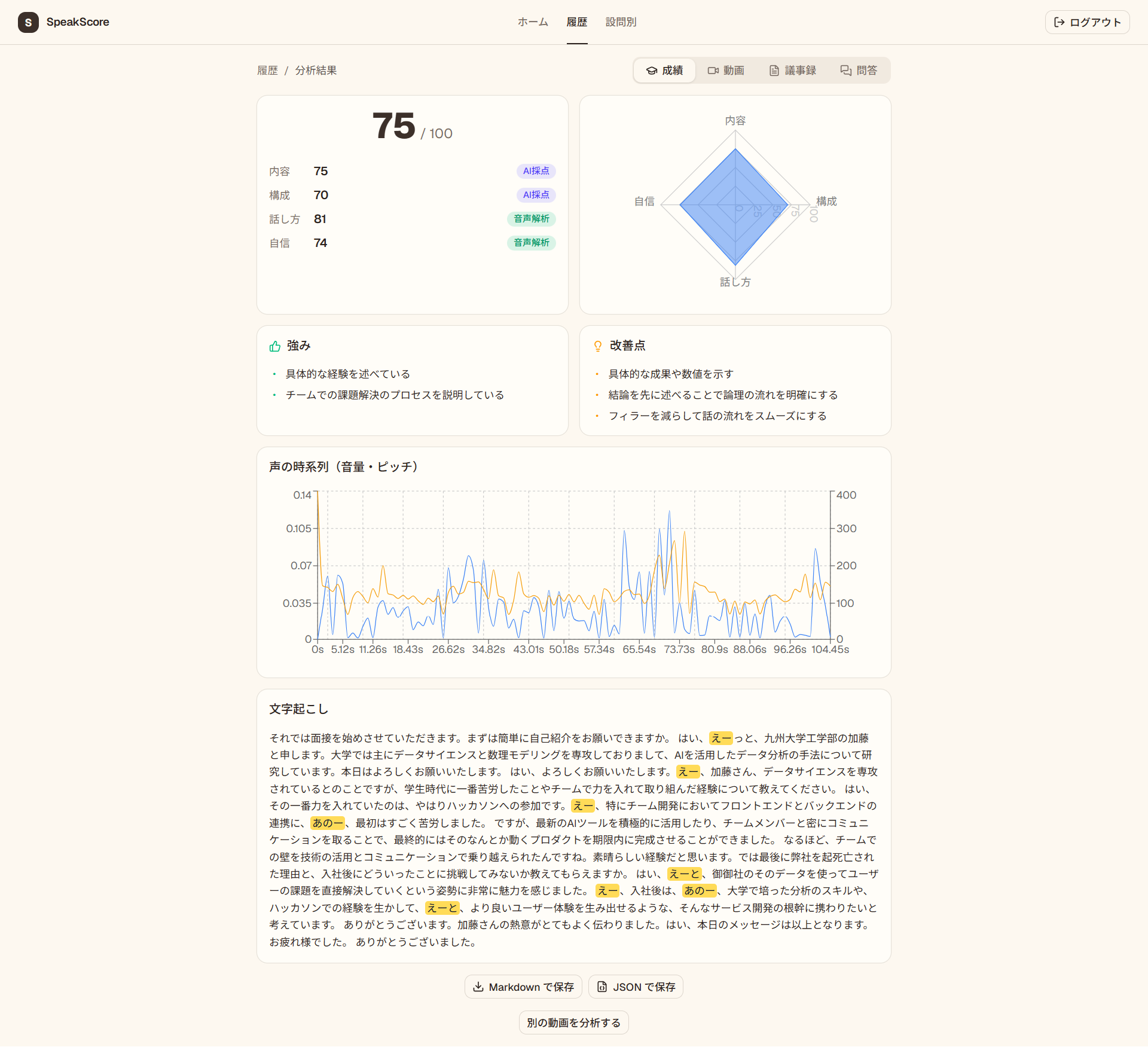 評価軸ごとのスコアをレーダーチャートで表示。各スコアには「音声から算出した点か、LLMが採点した点か」の印が付き、改善点のコメントは文字起こし・フィラー・無音区間と紐づきます。
評価軸ごとのスコアをレーダーチャートで表示。各スコアには「音声から算出した点か、LLMが採点した点か」の印が付き、改善点のコメントは文字起こし・フィラー・無音区間と紐づきます。
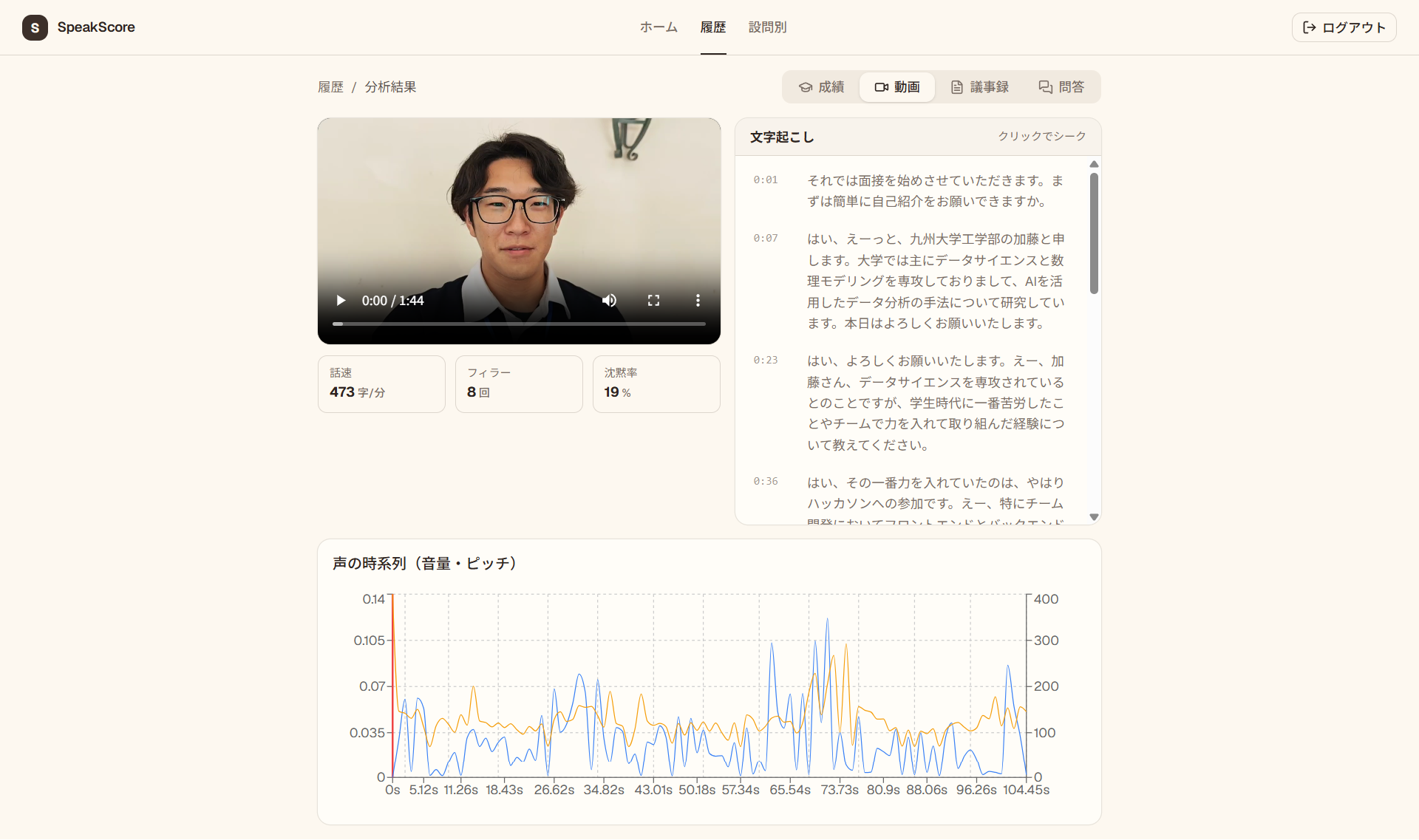 自分の面接動画を再生しながら、どの場面がどう評価されたかをタイムラインで確認できます。
自分の面接動画を再生しながら、どの場面がどう評価されたかをタイムラインで確認できます。
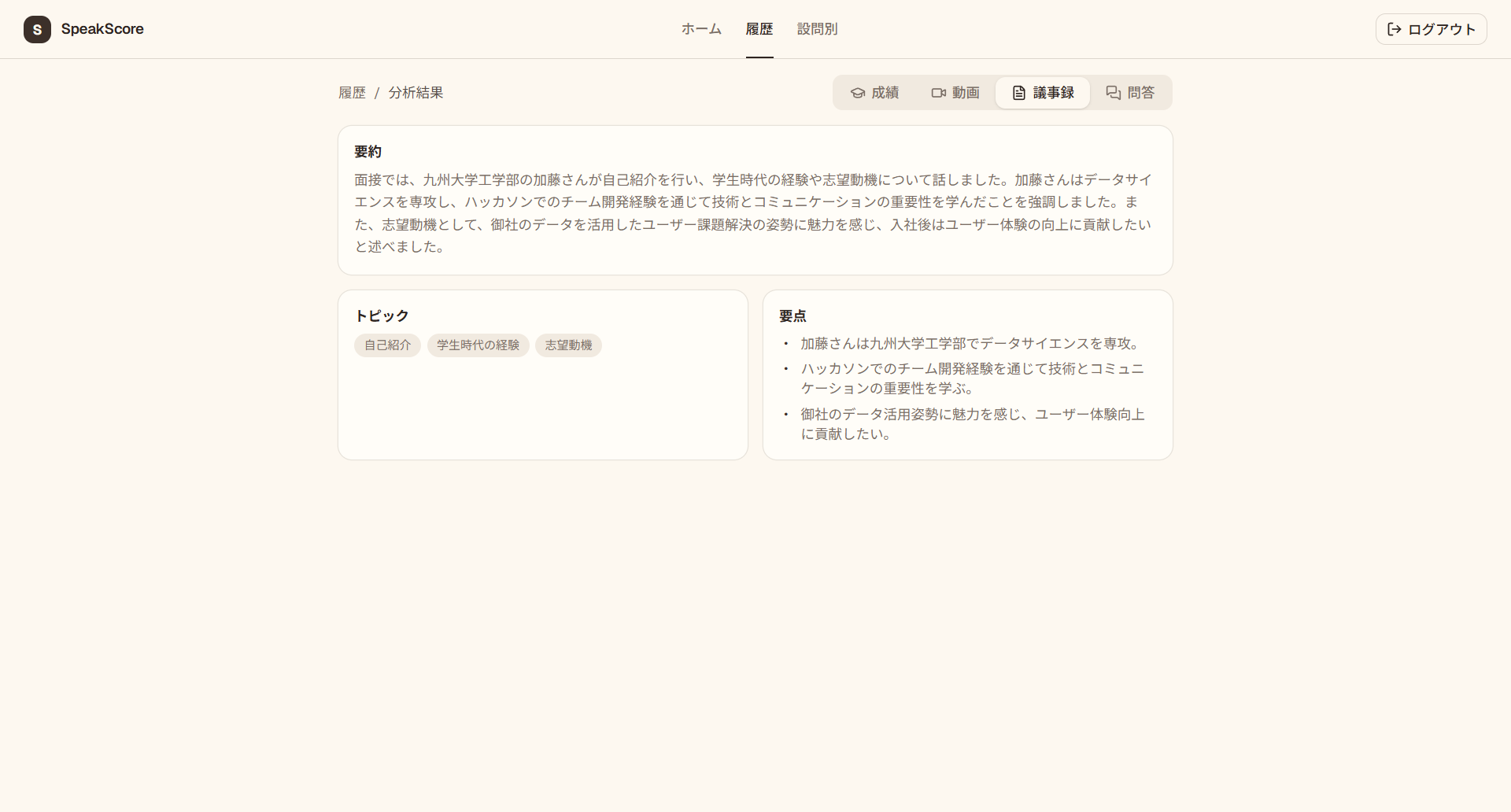
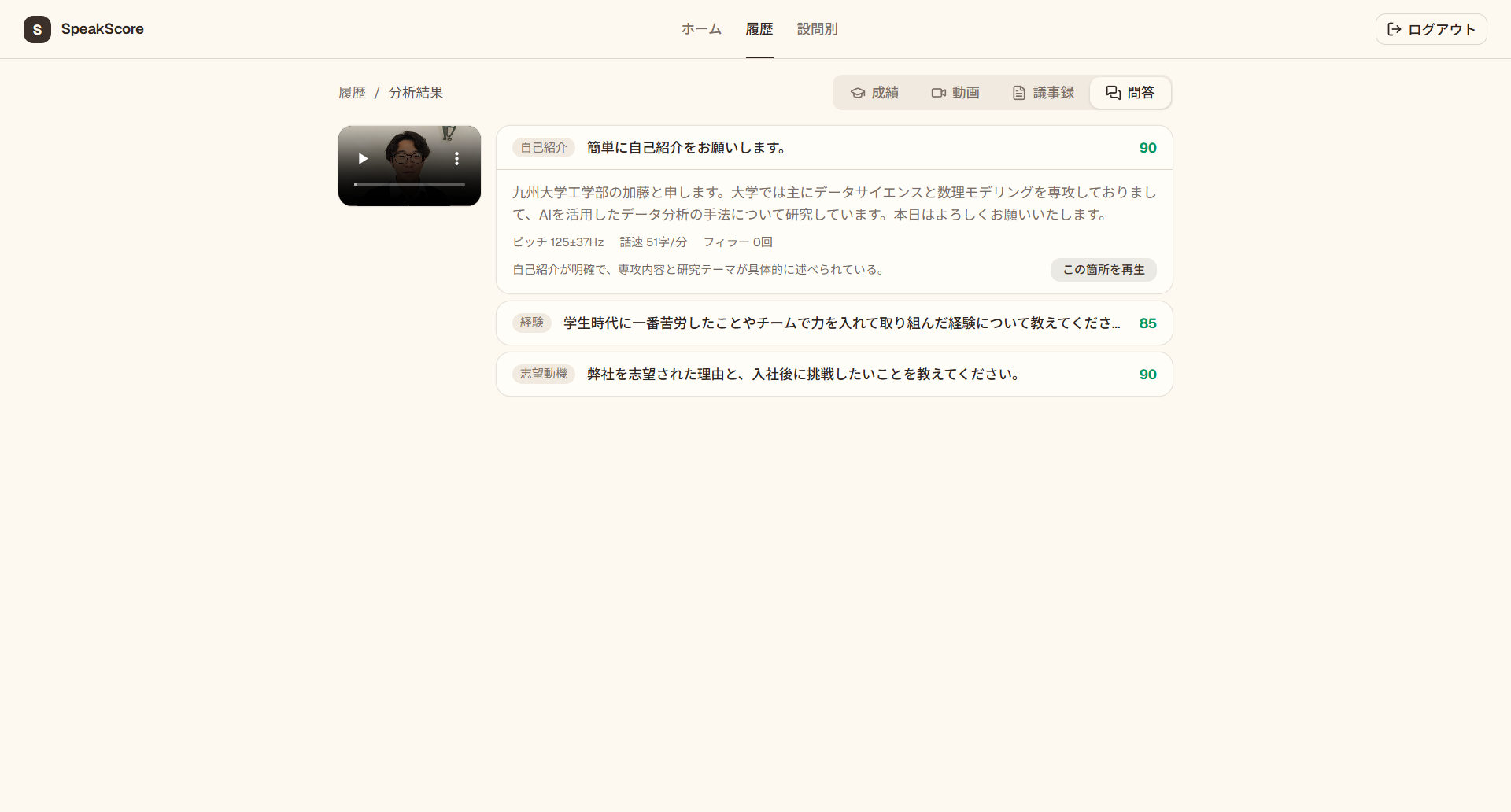 質問別に回答の内容とその評価を確認することができます。
質問別に回答の内容とその評価を確認することができます。
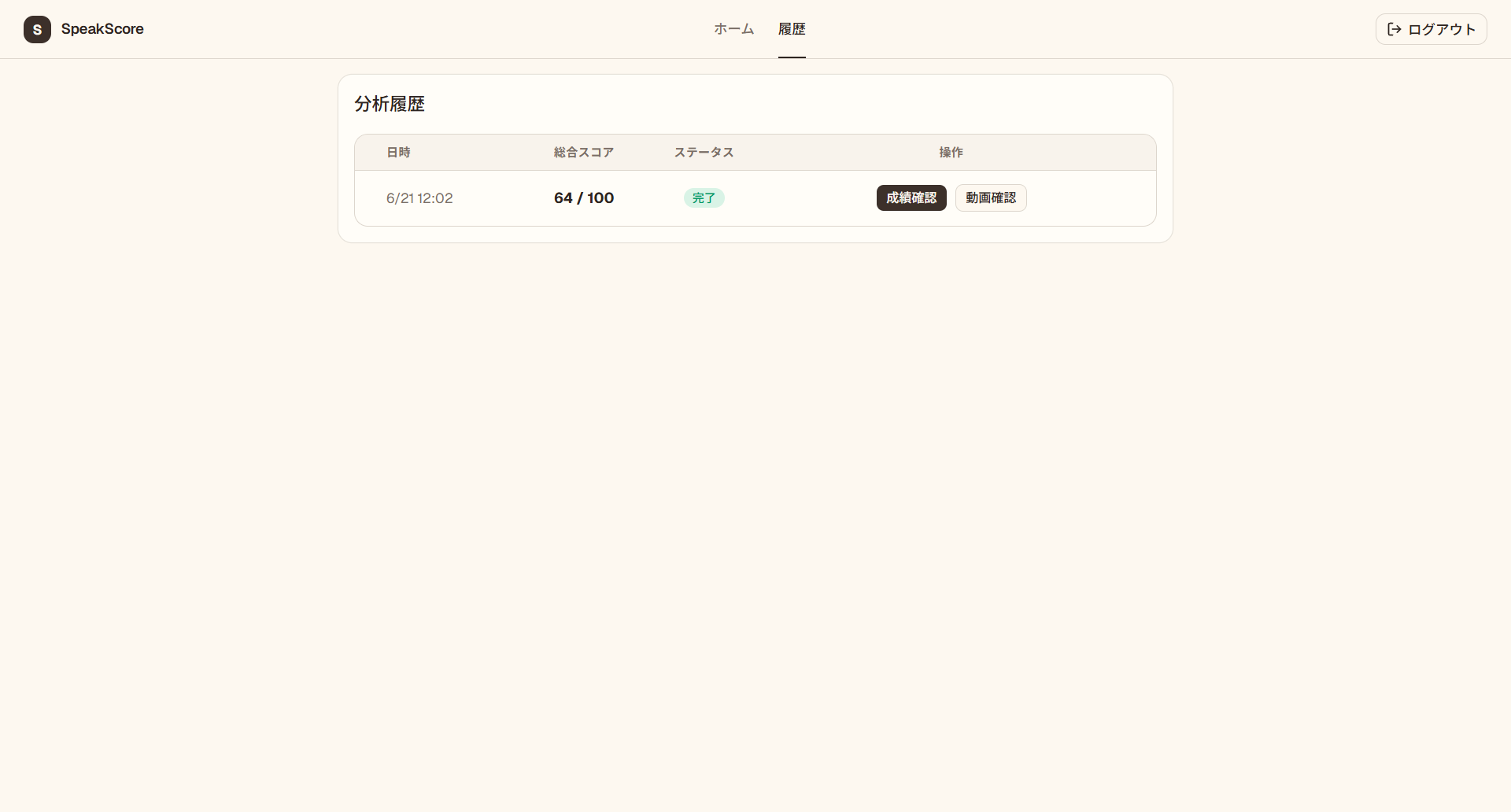
これまでに解析した面接を一覧で振り返り、回を重ねるごとの変化を追えます。
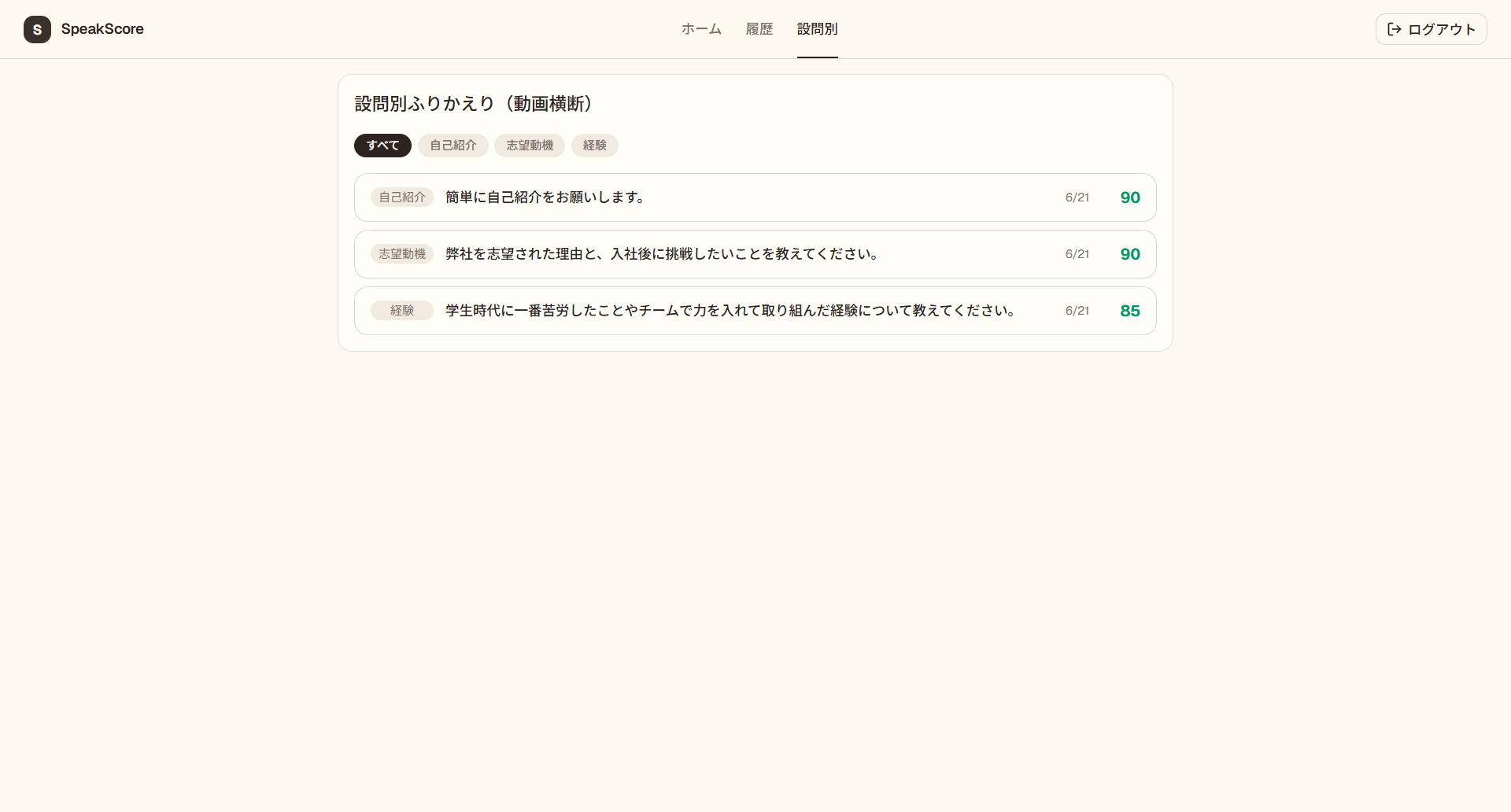
動画横断的に設問別の問答内容と、評価を確認できます。動画の問答画面に遷移します。

「待機コストをゼロに保ったまま、ちゃんとした非同期を出す」に立ち返って決定しました。
非同期処理に FastAPI の BackgroundTasks を使わなかったのは、scale-to-zero の Cloud Run がリクエスト処理中しかインスタンスの生存を保証しないからです。idle で殺されるとタスクごと落ちる。
ストアに Firestore を選んだのも同じ理由です。Cloud SQL は最小構成でも月7ドルかかり warm-up も要るので、待機ゼロの方針と噛み合いません。一方、Firestore はサーバーレスで待機コストがかかりません。
フロントを Cloud Run + Nginx にしたのは、GCS+CDN だと Load Balancer に月18ドル取られるからです。Cloud Run + Nginx なら実質ゼロで済むうえ、Nginx で /api をリバースproxyすれば本番のCORSがそもそも要らなくなります。
このプロダクトの肝は、設計方針を立てるだけでなく、バックエンドのパイプラインからCI/CD・観測性まで一気通貫で実装しきったことです。
採点はハイブリッドにしています。テキストだけでは拾えない「どう話したか」を点数に反映させたかったからです。話速・フィラー率・無音分布・ピッチ変動といった delivery / confidence は librosa の音声特徴量から scoring.py で算出し、話の中身と構成(content / structure)は LLM に採点させています。音声側は毎回同じ値が出るので評価のブレが小さく、ローカルの smoke テストと本番 E2E で overall スコアが一致することも確認しています。
worker は Cloud Tasks が at-least-once 配信である前提で組みました。放っておくと二重実行で課金が二重になったり状態が壊れたりするので、状態遷移を一度きりに絞って冪等にし、リトライも「回復できる障害は再試行・落とすべきものは即落とす」と線引きしています。
main に push すると GitHub Actions が lint・テストを回し、そのまま Cloud Run へ自動デプロイされます。認証は Workload Identity(鍵レス)・最小権限。インフラは Terraform でコード化し、「イメージはCDが所有、インフラはTerraformが所有」と所有境界を分けたので、評価ロジックを直すたびにインフラを触らず再デプロイできます。
本番で何が起きているか追えるよう、各処理段階を構造化ログ(Cloud Logging互換JSON)で計測し、恒久的な失敗だけを Sentry に通知します。面接という個人情報を扱うので、文字起こしや音声は送らず、job_id・サイズ・処理段階・所要時間だけを送るPII配慮を入れています。
プロジェクトで一番に作ったのは、Pydantic(backend)と TypeScript 型(frontend)のミラー、それとモックでした。API契約を先に push したことで、フロント担当はモックUI(進捗表示まで)を先に組み、自分はパイプラインに集中し、最後にAPIで合流する、という二人並行の進め方ができました。
採点はハイブリッドにしています。テキストだけでは拾えない「どう話したか」を点数に反映させたかったからです。文字起こしだけでは測れない delivery / confidence(話速・フィラー率・無音分布・ピッチ変動)を librosa の音声特徴量から scoring.py で算出し、content / structure(話の中身と構成)は LLM に採点させています。
実は最初「点数は機械的に、コメントはLLMに」という素朴なルールで進めていたのですが、話の中身や構成は意味を読まないと採点できず、LLMに任せるしかなくてこのルールは破綻しました。そこで2系統に分けたという経緯です。音声側は毎回同じ値が出るので評価のブレが小さく、ローカルのsmokeテストと本番E2Eでoverallスコアが一致することも確認しています。
アップロードが終わると、フロントがバックエンドに解析開始を伝えます。バックエンドはすぐ処理を始めず、まず安全確認をします。
awaiting_upload → processing を Firestore のトランザクションで一回しか通さないここから先は worker が引き取り、4段階を順番に走らせます。進捗は段階ごとに書き戻され、ユーザーは画面で「今どこか」を追えます。

Cloud Tasks は同じジョブを二回配ることがある(at-least-once)ので、worker は リースと一度きりの状態遷移で二重実行を吸収します。回復できる障害は再試行・落とすべきものは即落とす、と線引きし、長すぎる処理は soft-timeout で打ち切るので、ジョブが永久に詰まることもありません。
「待機ゼロの非同期」という設計方針を立て、Cloud Tasksの非同期パイプライン・Firestore/GCS・Terraform・CI/CD・Sentry観測性まで設計から実装まで通しきった。難所はバックエンドに寄せ、フロント担当が /api を叩くことに集中できるよう、API契約をDay 0で凍結してから二人並行で進める体制を作った。
加藤は開発もハッカソンも今回が初めてで、石川が切った細かいIssue(Tailwind v4+shadcn/ui導入、履歴一覧、SPAルーティング、認証エラー画面、フローティング進捗ウィジェットなど)を一つずつ調査・実装してフロントを作り上げた。合間にshadcnの隠れたダーク強制やnullish coalescingバグ、フィラーハイライトの文字位置ズレ、認証状態の分裂といった小さな事故をその都度直した。後半は評価品質レイヤにも踏み込み、Whisperのプロンプト文言だけでフィラー検出数が1→33に振れることを実験で突き止め、パターンマッチ+形態素解析のハイブリッド検出器に改善した。ビューポート幅に応じてレイアウトが組み替わるようにした。
フィラー検出の精度(形態素解析でdisfluency分離)と、LLM評価のプロンプト・ルーブリックを継続的に詰めていきます。
同じ仕組みは、会社の社員面談や商談の評価にもそのまま使えます。 さらに、「良い面談とは何か」の理想が確立している組織なら、自社の評価軸に合わせてスコアの重みを変えることができます。汎用の物差しではなく、組織ごとの基準で評価できるということです。
成績の良い社員の面談を、話し方のレベルまで技術的に分解して振り返れるので、「できる人は何が違うのか」を言語化し、人材育成に活かせます。
評価はすべて構造化データとして蓄積されます。今は一回ごとの振りかえりツールですがデータが溜まれば、将来的にはそのデータ自体を分析・活用する——成果との相関を見たり、組織横断で傾向をつかんだり——という展開も見込めます。



